
LLM Fine-tuning 실습 프로젝트 - Part 1
Contents
- 개요
- Domain-specific LLM의 필요성
- Domain-specific Dataset
- DPO Dataset 생성하기
- Wizard LM: Evolving
1. 개요
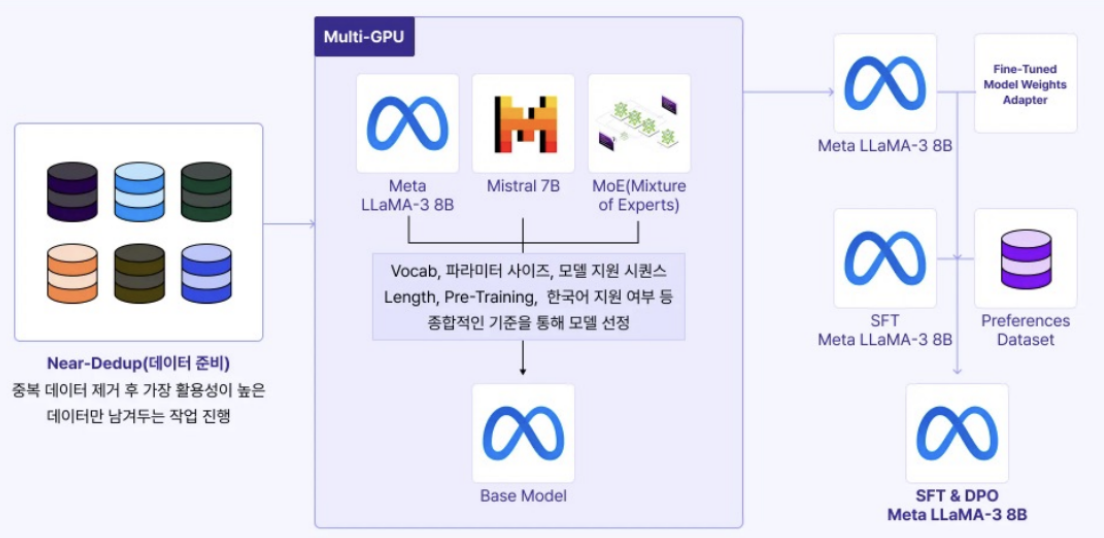
- Step 1) Data 생성
- Synthetic data
- Near-deduplication (중복 제거)
- 데이터 도메인: 보험 약관
- Step 2) Base model 선정
- 3개의 후보 모델 중, Llama 사용
- Step 3) SFT 진행 (feat. full fine-tuning)
- Step 4) DPO 진행
2. Domain-specific LLM의 필요성
Why? LLM이 가장 효과적으로 활용될 수 있는 영역임!
- Specific한 영역에서 학습되지 않은 모델
Examples
- ex) 회사 내규 LLM
- Pretrained LLM은 (private한) 회사 내규 데이터를 접해본 적이 없음!
- 새로운 (domain-specific한) 데이터에 align할 필요가 있음
- ex) 제조업, 응대 protocol 등…
RAG를 사용하면 되지 않나?
한계점은?
- (1) Hyperparameter에 민감하다
- (2) 불확실한 semantic space … query와 유사한 chunk를 잘 못찾을 수도
- (3) System이 무거워짐
- (4) 한국어 Embedding 모델의 성능 한계
- BERT 기반의 모델의 연구가 최근에는 활발히 이뤄지지 않음
\(\rightarrow\) 따라서, Domain-specific domain에 대해서 SFT 데이터 생성 이후, fine-tuning을 하는 것이 가장 효과적!
3. Domain-specific Dataset
Question) Domain-specific Dataset를 어떻게 생성할지?
Answer)
- 후보1: (Data 생성용) 라이브러리? \(\rightarrow\) Model / Prompt dependency가 높음
- 후보2: Human labeling \(\rightarrow\) Too costly!
Solution
\(\rightarrow\) 따라서, (1) 적당한 비용 & (2) 적당한 정도의 모델 dependency
생성 과정
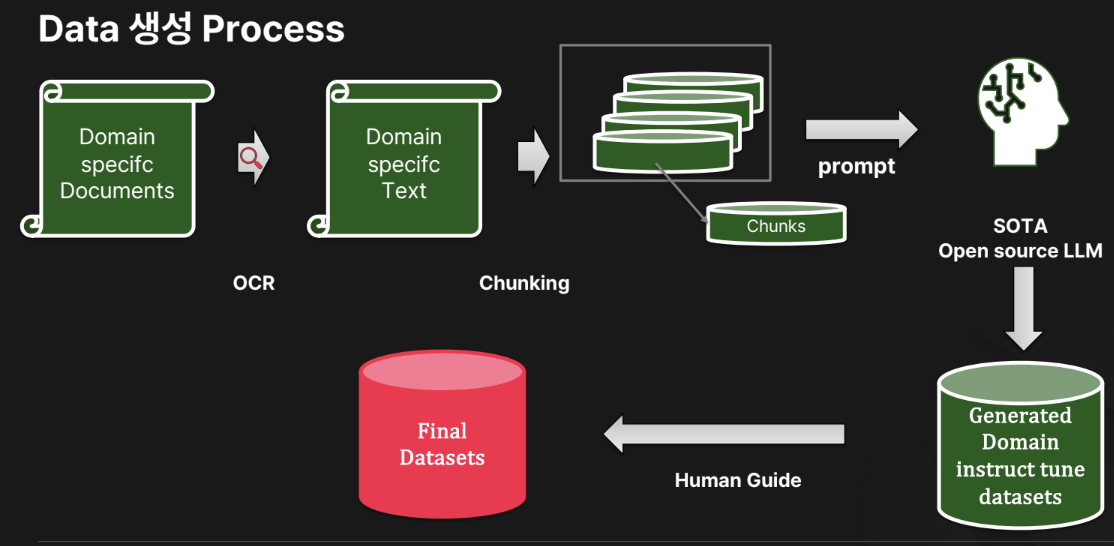
- Step 1) PDF 데이터셋 준비
- Step 2) OCR 통해 추출
- Step 3) Text를 chunking
- Step 4) 하나의 Chunk를 하나의 Prompt로 LLM에
- Step 5) 사람 검증을 통해 final dataset 완성하기
Q) 위 과정도 결국 LLM을 쓰는 것 아니냐? Model-dependency?
\(\rightarrow\) 적당한 비용에 대한 trade-off 감안해야! “후”처리 과정이 더 중요하다!
4. DPO Dataset 생성하기
RLHF보다 더 적은 framework
\(\rightarrow\) But 여전히, DPO 데이터셋 (선호/비선호 데이터셋) 생성은 매우 중요함!
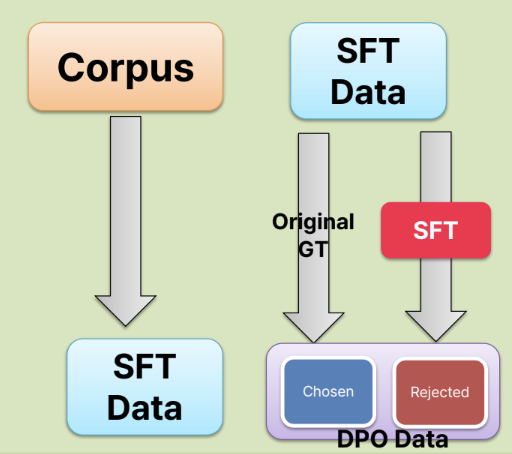
선호 (1) 데이터셋 = Label
비선호 (0) 데이터셋 = ??
- 후보 1) Multiple choice 변형하기: 오답지를 비선호로!
- 후보 2) SFT Sampling
- SFT된 모델을 활용하여 샘플링 (output (답변) 추출)하여 사용!
SFT Sampling
SFT 데이터를 재활용하자!
- SFT 데이터 & DPO 데이터: 일부 교집합 O \(\rightarrow\) 좋은 성능!
- 단, 그 외의 새로운 데이터도 활용은 해줘야!
5. Wizard LM: Evolving
한 줄 요약: 기존의 instruction을 다양하게 “재”생성!
- LLM이 더욱 복잡한 지시를 이해하고 따를 수 있도록!
- LLM 자체가 점점 더 복잡한 지시를 생성하는 방법 (Evol-Instruct)을 제안
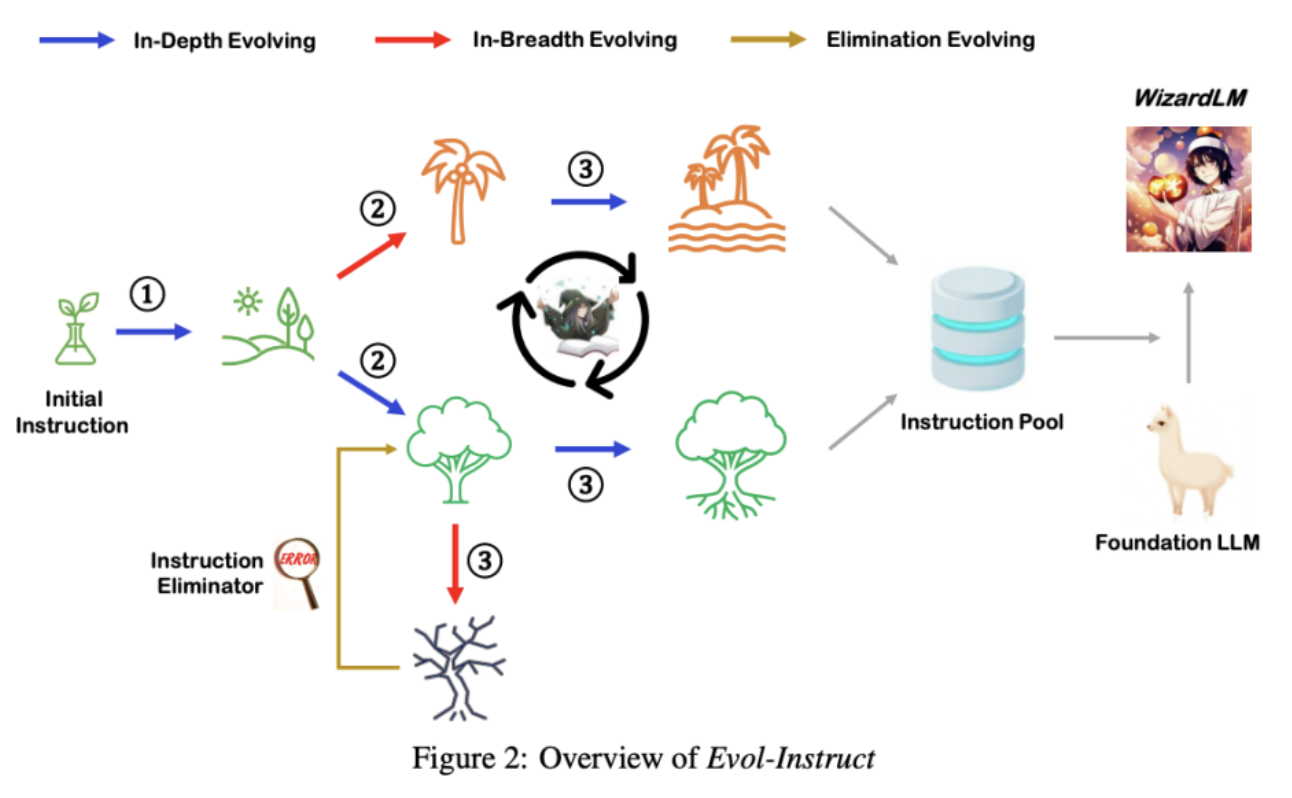
네 가지 방식
- (1) Deepening: 기존 지시를 더 깊이 있는 내용으로 확장하여 복잡성을 증가시키는 방식
- (2) Broadening: 기존 지시와 연관된 다양한 측면을 추가하여 범위를 넓히는 방식
- (3) Reasoning: 문제 해결 과정에서 논리적 사고 단계를 추가하여 AI가 더 정교한 추론을 수행하도록 유도하는 방식
- (4) Complexifying: 단순한 지시를 보다 복잡한 방식으로 변형하여 난이도를 높이는 방식
Reference
https://fastcampus.co.kr/data_online_gpu