
LLM Fine-tuning 실습 프로젝트 - Part 2
Open Source Model 종류 및 특징
Contents
- Llama
- Mistral
- Gemma2
- Qwen
1. Llama (by Meta)
(최신 버전: LLaMA 3.2 출시)
다양한 버전
- LLaMA 2: GQA (Grouped Query Attention) 도입으로 효율적인 추론 가능
- LLaMA 3 → 3.1: Context length 확장 (4K → 8K → 128K)
- LLaMA 3.1 → 3.2: On-device 및 멀티모달 지원
특징: Fine-tuning 시 무겁게(robust하게) 작동하는 경향
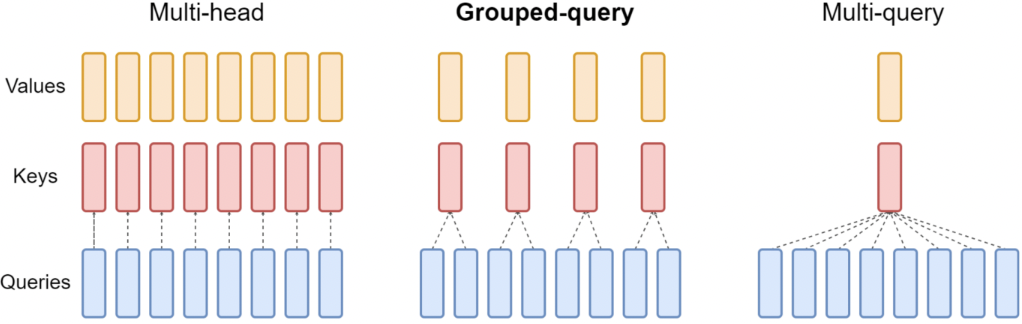
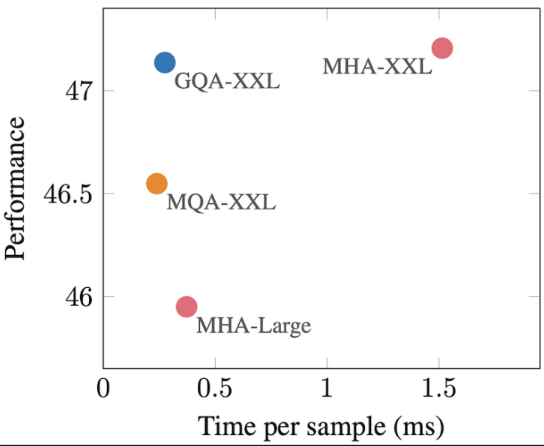
GQA (Grouped Query Attention)
- MQA만큼 빠름 & MHA와 비슷한 성능
- Group 개수: 주로 \(\sqrt{\text{\# heads}}\)
2. Mistral
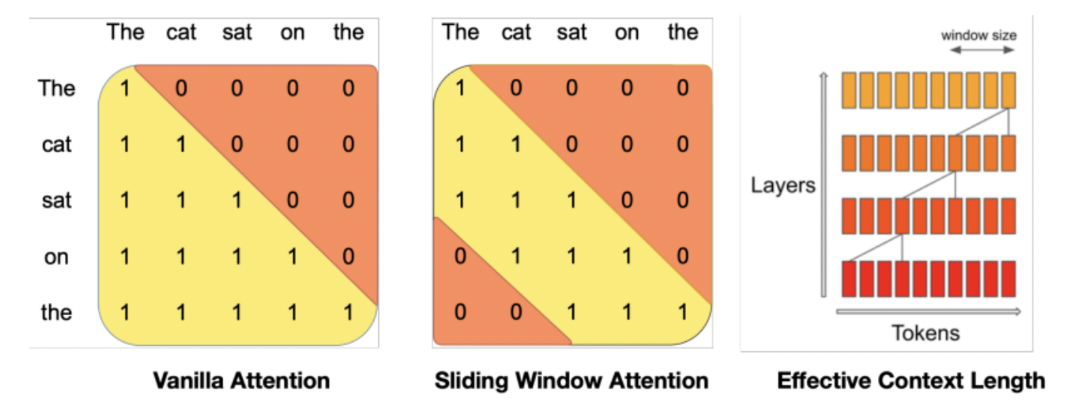
(1) Sliding Window Attention
Memory issue of Transformers: Quadratic attention
- 기존) context length (\(L\))의 제곱
- SWA) window 크기 (\(w\))의 제곱
(2) MoE
MoE관련 detail은 생략!
Mistral의 다양한 버전
- Mistral 7B: MoE (X)
- Mixtral 8x7B: Mistral + MoE
- 8개의 Expert 중 2개만 활성화 (# active params: 14B)
(3) (최신 모델) Large & Nemo
Large
- # params: 123B
- 다국어 LLM
- Llama 3.1 405B보다 효율적
- 다만, non-commercialized
NeMo
- Nvidia와 협력하여 개발
- 128k의 sequence length
3. Gemma2 (by Google)
-
Self-attention을 활용한 LLM
-
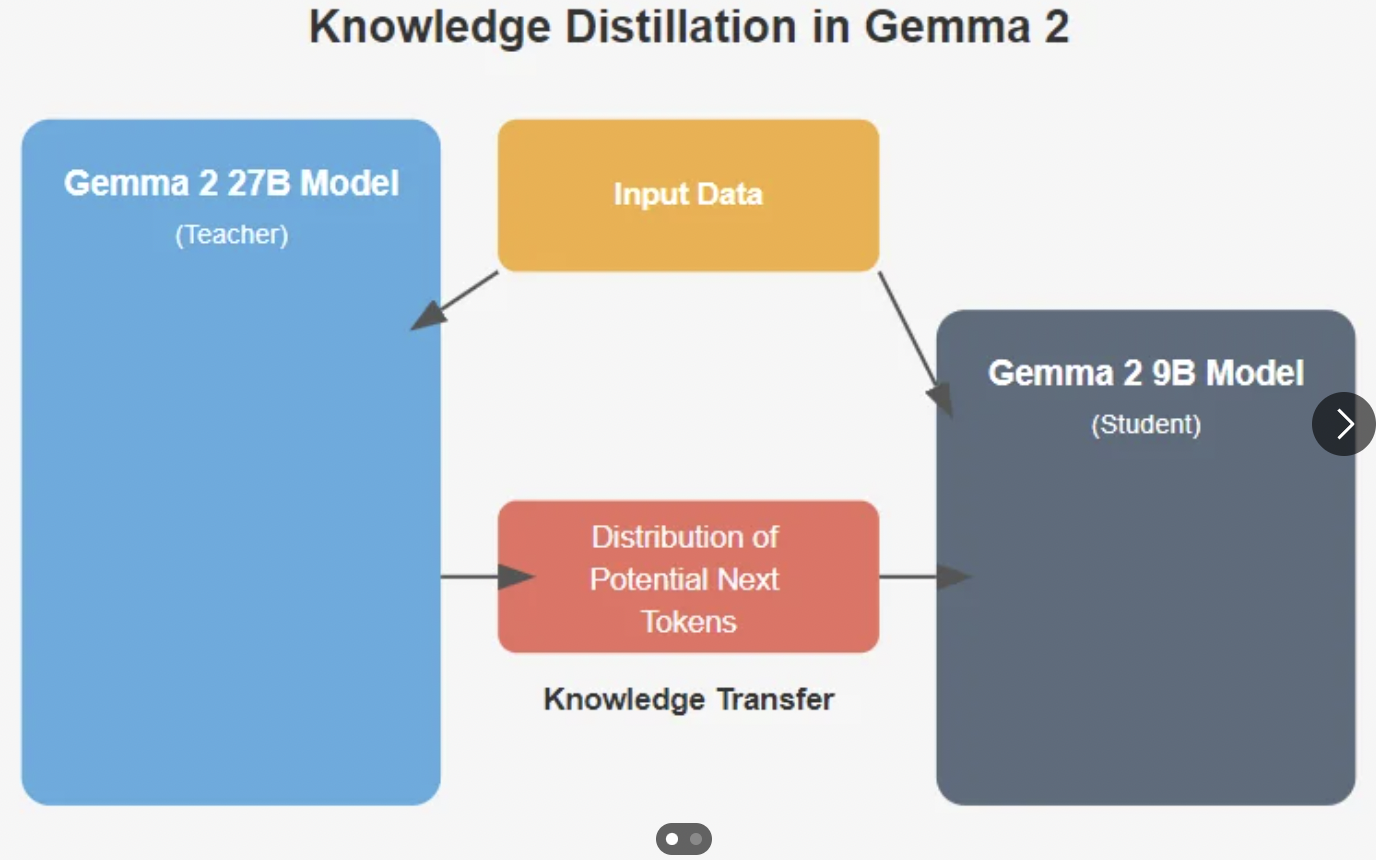
27B model
- Knowledge Distillation을 활용하여 student model을 학습
-
Pre-FFN layer norm & Post-FFN layer norm에 RMSNorm을 추가
\(\rightarrow\) 학습의 안정성 향상
- Attention에서, local & global attention을 교차 사용
- Logit soft capping
- 다음 단어 예측 시, logit 값이 너무 크거나 작지 않게끔!

4. Qwen
( Alibaba Cloud의 Qwen 팀에서 개발한 모델 )
-
주요 특징
- 다국어 모델
- GQA 사용
-
Length 특징
-
Sequence length: 최대 128K 토큰
-
Output length: 최대 8K 토큰
-
-
기타 특징
- SwiGLU + RMSNorm + ROPE
- (작은 모델의 경우) Embedding tie 기법
- Input embedding & Output embedding이 동일한 weight 사용
Reference
https://fastcampus.co.kr/data_online_gpu