
vllm의 PagedAttention
Contents
- PagedAttention이란?
- Preliminaries
- KV 캐싱
- 연속된 메모리 블록
- PagedAttention을 통한 해결
- Summary
1. PagedAttention이란?
vllm에서 도입한 효율적인 Key-Value (KV) 캐싱 기법- 목적: 대규모 LLM의 Inference 속도를 높이고 메모리 사용량을 최적화
- 특히 긴 문맥(Context)에서 모델이 빠르게 응답
2. Preliminaries
(1) KV 캐싱
(Self-Attention 시) Input token 간의 연관성을 계산하는 과정에서 Key (K)와 Value (V) 행렬을 생성
- Inference 시: 이전 토큰들의 K, V 값을 저장 & 새로운 토큰을 생성할 때, 다시 계산하지 않도록 캐싱하는 것이 일반적
- 이를 KV 캐싱이라고 하며, 특히 LLM처럼 긴 문맥을 다룰 때 매우 중요!
기존 KV 캐싱 방식:
- 일반적: 연속된 메모리 블록을 할당
- 한계점: 비효율적인 메모리 사용과 재할당 비용을 초래
(2) 연속된 메모리 블록
컴퓨터에서 데이터를 저장할 때 메모리 주소(메모리 공간의 위치)를 사용한다.
- “연속된 메모리 블록”이란 데이터가 물리적으로 메모리 상에서 순서대로 배치된 경우를 의미한다.
- 예를 들어, 1GB의 공간이 필요하다면, 하나의 커다란 1GB 크기의 연속된 메모리 영역을 확보해야 한다.
a) 연속된 메모리 블록의 예시
아래처럼 A, B, C, D 데이터를 연속된 주소 공간에 배치한 것이 연속된 메모리 블록이다.
| 메모리 주소 | 데이터 |
|---|---|
| 0x1000 | A |
| 0x1004 | B |
| 0x1008 | C |
| 0x100C | D |
b) 연속된 메모리 블록의 문제점
LLM의 Inference에서는 Self-Attention 연산을 위해 이전 토큰들의 Key (K)와 Value (V) 행렬을 저장하는 KV 캐시를 사용
- 기존 방식에서는 KV 캐시를 한 번에 큰 연속된 메모리 블록으로 할당해야 했음
- 하지만 긴 문맥(Context)이 필요하면 KV 캐시가 점점 커지므로 연속된 큰 공간을 확보하는 것이 어려워진임
- 특히 GPU 메모리는 단편화(Fragmentation)되기 쉬워 충분한 총 메모리가 있어도 연속된 공간을 확보하지 못하면 할당이 실패할 수 있음
[예시: 연속된 메모리 할당이 어려운 경우]
기존에 여러 개의 작은 데이터(A, B, C)가 저장된 메모리에서 새로운 1GB의 연속된 공간이 필요한 경우를 생각해보자!
| 메모리 주소 | 데이터 |
|---|---|
| 0x1000 | A |
| 0x2000 | B |
| 0x3000 | C |
| 0x4000 | (빈 공간) |
| 0x5000 | (빈 공간) |
| 0x6000 | D |
| 0x7000 | (빈 공간) |
이 경우, 총 빈 공간이 1GB 이상 있어도 연속된 공간이 없어서 할당이 불가능할 수 있음!
3. PagedAttention을 통한 해결
PagedAttention은 연속된 메모리 블록을 요구하지 않고, 작은 페이지 단위로 관리하여 이 문제를 해결
- 연속된 공간을 찾을 필요 없이, 여러 개의 작은 페이지를 동적으로 할당할 수 있다.
- 즉, 메모리 단편화 문제를 최소화하면서도 KV 캐시를 효율적으로 관리할 수 있다.
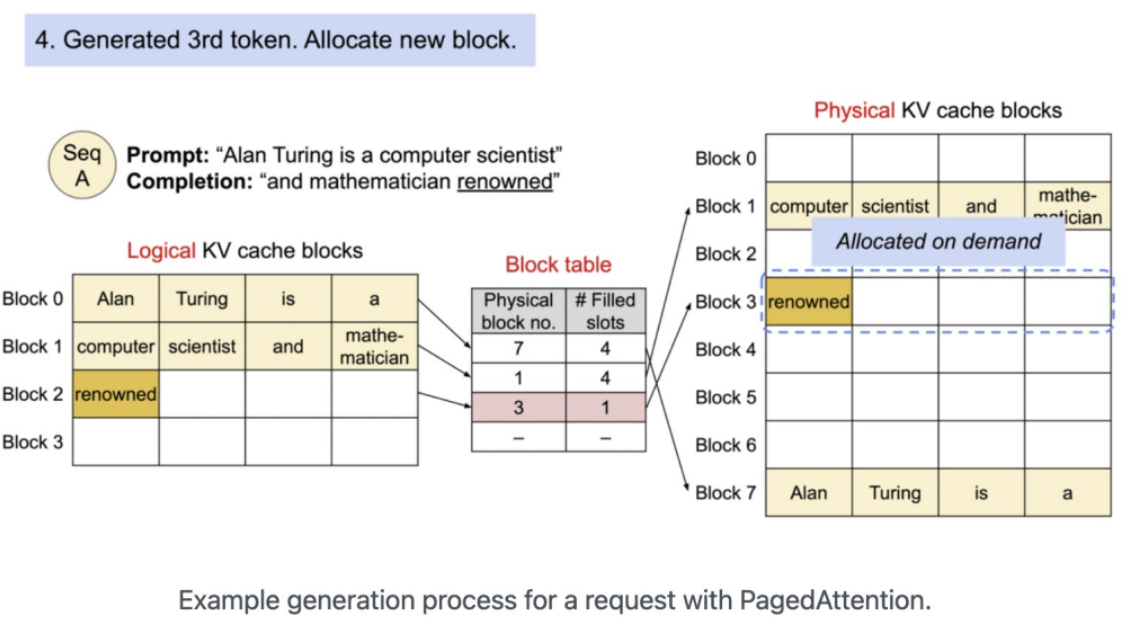
[예시: PagedAttention 방식의 메모리 할당 예시]
PagedAttention을 사용하면 KV 캐시를 작은 페이지(예: 16KB 단위)로 나누어 배치한다.
- 기존의 연속된 공간이 없어도, 여러 작은 빈 공간을 활용하여 KV 캐시를 저장할 수 있다.
| 메모리 주소 | 데이터 |
|---|---|
| 0x1000 | A |
| 0x2000 | B |
| 0x3000 | C |
| 0x4000 | KV 캐시 (Page 1) |
| 0x5000 | KV 캐시 (Page 2) |
| 0x6000 | D |
| 0x7000 | KV 캐시 (Page 3) |
이렇게 하면 연속된 큰 공간을 찾을 필요 없이, 작은 단위로 메모리를 효율적으로 활용할 수 있다.
4. Summary
- (1) 연속된 메모리 블록: 한 번에 큰 크기의 연속된 메모리 공간을 확보해야 하는 방식 → 메모리 단편화로 인해 할당이 어려울 수 있음.
- (2) PagedAttention: 작은 페이지 단위로 KV 캐시를 관리하여 비연속적인 메모리 공간에서도 효율적으로 할당 가능.
- (3) 이를 통해 LLM의 긴 문맥 지원을 원활하게 하면서도 속도와 메모리 사용량을 최적화할 수 있다.
기존 KV 캐싱 vs. PagedAttention
| 비교 항목 | 기존 KV 캐싱 | PagedAttention |
|---|---|---|
| 메모리 할당 | 연속적인 블록 필요 | 페이지 단위로 동적 할당 |
| 메모리 낭비 | 크기가 고정되어 낭비 발생 | 필요한 만큼만 할당 |
| 속도 | 블록 재할당 시 속도 저하 | 페이지 인덱싱으로 빠른 접근 |
| 긴 문맥 지원 | 어려움 | 효율적으로 가능 |