
1. Axolotl 라이브러리 소개
Goal: LLM을 쉽게 fine-tuning하자!
-
Open-source
( https://github.com/axolotl-ai-cloud/axolotl )
-
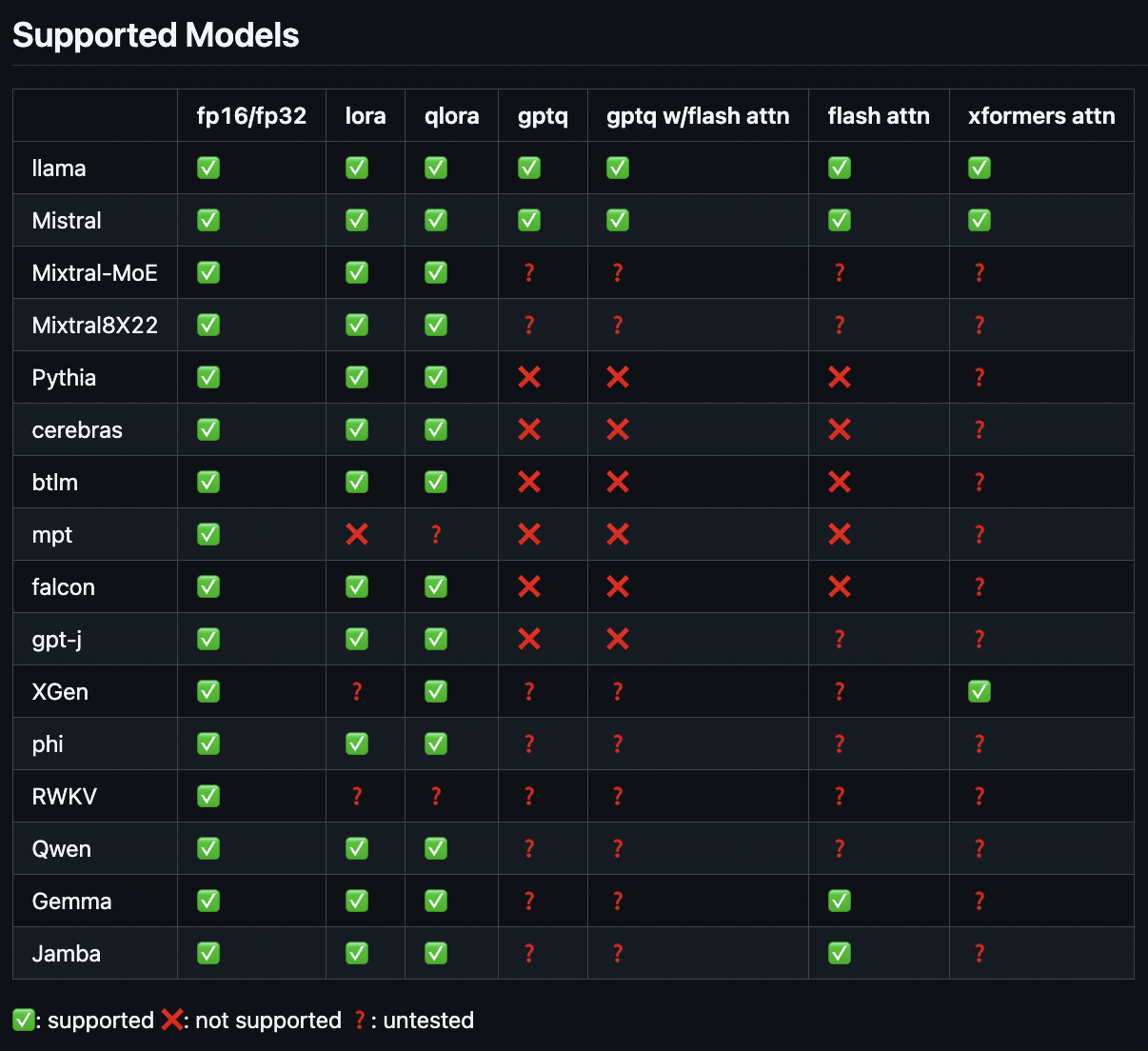
Hugging face model들과 호환성 O
주요 기능
- Fine-tuning
- LoRA, QLoRA, GPTQ 등
- Multi-gpu 지원
- DeepSpeed, FSDP 등을 사용하여 병렬학습 O
- 다양한 기술
- Flash attention, xformers, rope scaling
- 데이터셋
- JSONL 같은 다양한 format의 데이터셋 지원

2. 실습
Axolotl을 활용한 네 가지 실습
( model: LLaMA)
-
FSDP + LoRA
-
ZeRO + LoRA
-
MP + QLoRA
-
FFT + (MP/ZeRO)
참고: configs는 아래의 3. Configurations 참고하기!
(1) FSDP + LoRA: yaml 기반
- config에 아래의 내용을 넣어줘야!
fsdp:
- full_shart
- auto_wrap
fsdp_config:
fsdp_limit_all_gathers: true
...
실행하기
accelerate launch -m axolotl.cli.train fsdp_train.yaml
(2) ZeRO + LoRA: yaml 기반
- config에 아래의 내용을 넣어줘야!
deepspeed: ./deepspeed_configs/zero3_bf16_cpuoffload_all.json
실행하기
- 만약 위의 내용을 안넣을 경우, 아래의 argument로!
accelerate launch -m axolotl.cli.train zero3_train.yaml -deepspeed deepspeed_configs/zero3_bf16_cpuoffload_all.json
(3) MP + QLoRA: 코드 기반
finetune.sh
merge.sh
upload.sh
3. Configurations
https://axolotl-ai-cloud.github.io/axolotl/docs/config.html
(1) base model 경로
base_model: ./llama-7b-hf
base_model_ignore_patterns:
base_model_config: ./llama-7b-hf
revision_of_model:
(2) tokenizer & model
tokenizer_config:
model_type: AutoModelForCausalLM
tokenizer_type: AutoTokenizer
trust_remote_code:
tokenizer_use_fast:
tokenizer_legacy:
resize_token_embeddings_to_32x:
(3) 모델 유형 선택 (padding 관련 이슈로 필요)
# ex) mistral 시, padding_side='left'
is_falcon_derived_model:
is_llama_derived_model:
is_qwen_derived_model:
is_mistral_derived_model:
(4) 기본 모델의 구성 설정 변경하고 싶은 경우
overrides_of_model_config:
rope_scaling:
type: # linear | dynamic
factor: # float
overrides_of_model_kwargs:
# use_cache: False
(5) 양자화 설정
bnb_config_kwargs:
# 아래는 default 값
llm_int8_has_fp16_weight: false
bnb_4bit_quant_type: nf4
bnb_4bit_use_double_quant: true
# 4-bit GPTQ quantized model
gptq: true
load_in_8bit: true
load_in_4bit:
bf16: true
fp16: true
tf32: true
# No AMP (automatic mixed precision)
bfloat16: true # require >=ampere
float16: true
(6) Memory limit
gpu_memory_limit: 20GiB
lora_on_cpu: true
(7) 데이터셋
- https://axolotl-ai-cloud.github.io/axolotl/docs/dataset-formats/
datasets:
# HuggingFace dataset repo
- path: vicgalle/alpaca-gpt4
type: alpaca # format (template)
ds_type: # Optional[str]
data_files: # Optional[str] path to source data files
shards:
shards_idx:
preprocess_shards:
name:
train_on_split: train
revision:
trust_remote_code:
# Custom user instruction prompt
- path: repo
type:
system_prompt: ""
system_format: "{system}"
field_system: system
field_instruction: instruction
field_input: input
field_output: output
# Customizable to be single line or multi-line
# Use {instruction}/{input} as key to be replaced
# 'format' can include {input}
format: |-
User: {instruction} {input}
Assistant:
# 'no_input_format' cannot include {input}
no_input_format: "{instruction} "
# For `completion` datsets only, uses the provided field instead of `text` column
field:
val_set_size: 0.04
dataset_shard_num:
dataset_shard_idx:
sequence_len: 2048
pad_to_sequence_len:
sample_packing:
eval_sample_packing:
sample_packing_eff_est:
total_num_tokens:
sample_packing_group_size: 100000
sample_packing_bin_size: 200
pretraining_sample_concatenation:
batch_flattening:
device_map:
max_memory:
(8) LoRA
adapter: lora
lora_model_dir: # (if pretrained lora)
# LoRA hyperparameters
# https://www.anyscale.com/blog/fine-tuning-llms-lora-or-full-parameter-an-in-depth-analysis-with-llama-2
lora_r: 8
lora_alpha: 16
lora_dropout: 0.05
lora_target_modules:
- q_proj
- v_proj
# - k_proj
# - o_proj
# - gate_proj
# - down_proj
# - up_proj
lora_target_linear: # If true, will target all linear modules
peft_layers_to_transform: # The layer indices to transform, otherwise, apply to all layers
# If you added new tokens to the tokenizer, you may need to save some LoRA modules because they need to know the new tokens.
# For LLaMA and Mistral, you need to save `embed_tokens` and `lm_head`. It may vary for other models.
# `embed_tokens` converts tokens to embeddings, and `lm_head` converts embeddings to token probabilities.
# https://github.com/huggingface/peft/issues/334#issuecomment-1561727994
lora_modules_to_save:
# - embed_tokens
# - lm_head
lora_fan_in_fan_out: false
# Apply custom LoRA autograd functions and activation function Triton kernels for
# speed and memory savings
# See: https://axolotl-ai-cloud.github.io/axolotl/docs/lora_optims.html
lora_mlp_kernel: true
lora_qkv_kernel: true
lora_o_kernel: true
# LoRA+ hyperparameters
# For more details about the following options, see:
# https://arxiv.org/abs/2402.12354 and `src/axolotl/core/train_builder.py`
loraplus_lr_ratio: # loraplus learning rate ratio lr_B / lr_A. Recommended value is 2^4.
loraplus_lr_embedding: # loraplus learning rate for lora embedding layers. Default value is 1e-6.
peft:
# Configuration options for loftq initialization for LoRA
# https://huggingface.co/docs/peft/developer_guides/quantization#loftq-initialization
loftq_config:
loftq_bits: # typically 4 bits
(9) Training hyperparameters
gradient_accumulation_steps: 1
micro_batch_size: 2
eval_batch_size:
num_epochs: 4
warmup_steps: 100 # cannot use with warmup_ratio
warmup_ratio: 0.05 # cannot use with warmup_steps
learning_rate: 0.00003
lr_quadratic_warmup:
logging_steps:
eval_steps: # Leave empty to eval at each epoch
evals_per_epoch:
eval_strategy: # Set to `"no"` to skip evaluation, `"epoch"` at end of each epoch, leave empty to infer from `eval_steps`.
save_strategy: # Set to `"no"` to skip checkpoint saves, `"epoch"` at end of each epoch, `"best"` when better result is achieved, leave empty to infer from `save_steps`.
save_steps: # Leave empty to save at each epoch, integer for every N steps. float for fraction of total steps
saves_per_epoch: # number of times per epoch to save a checkpoint, mutually exclusive with save_steps
save_total_limit: # Checkpoints saved at a time
# Maximum number of iterations to train for. It precedes num_epochs which means that
# if both are set, num_epochs will not be guaranteed.
# e.g., when 1 epoch is 1000 steps => `num_epochs: 2` and `max_steps: 100` will train for 100 steps
max_steps: