
1. LLM & GPU
Contents
- LLM의 개념과 배경
- NLP Tasks
- LLM이란
- LLM의 두 부류
- LLM의 현업에서의 현실
- 현업에서 LLM을 활용하기 위해
- LLM의 향후 기술 전망
- LLM의 역사와 발전 배경
- 아키텍처 흐름
- Transformer의 활용
- LLM의 등장 흐름 1
- LLM의 등장 흐름 2
- LLM의 등장 흐름 3
- LLM의 Components
- LLM 작동 방식 및 원리
- Tokenizer
- Decoding Strategy
- GPU 자원 & LLM
- LLM의 GPU 의존성
- ROPE
- Llama 2 vs. Llama 3.1
1. LLM의 개념과 배경
(1) NLP Tasks
- 텍스트 분류 (Text Classification)
- 개체명 인식 (Named Entity Recognition)
- 감정 분석 (Sentiment Analysis)
- 텍스트 요약 (Text Summarization)
- 기계 번역 (Machine Translation)
- 질문 응답 (Question Answering)
- 대화형 인터페이스 (Conversational Interfaces)
- 문서 유사성 측정 (Document Similarity)
- 자연어 생성 (Natural Language Generation)
(2) LLM이란
- 거대한 모델 + 방대한 데이터로 사전학습된 모델
- 크게 BERT/GPT 계열로 나뉨
- 다양한 NLP task들을 푸는데에 사용됨
(3) LLM의 두 부류
a) Autoregressive LM
- Decoder-only model
- GPT 계열
- 강점: Text 생성
- 강한 Task: 텍스트 요약, 기계 번역, 대화형 인터페이스
b) Autoencoding LM
- Encoder-only model
- BERT 계열
- 강점: Text 이해
- 강한 Task: 텍스트 분류, 개체명 인식, 감정 분석 등
(4) LLM의 현업에서의 현실
- Privacy 문제: 내부 데이터 반출 & 활용에 대한 민감성
- Domain 문제: general하게는 좋으나, 특정 도메인 하에서는 X수도
- 활용 용도: 특정 용도에 맞게 변형해서 활용해야
(5) 현업에서 LLM을 활용하기 위해서? (for 서비스 개발)
a) RAG
-
LLM + RAG (정보 검색)
\(\rightarrow\) 문서 검색, 쿼리 증강, 텍스트 생성을 함께 활용하기
-
e.g., LangChain, AutoRag
b) Domain-specific LLM
- 특정 도메인에 맞게 Prompt-/Fine- tuning
(6) LLM 향후 기술 전망
- Multimodal (feat. MLLM)
- On Device (feat. sLLM)
- 통합 모델
- 다양한 Foundation model
2. LLM의 역사와 발전 배경
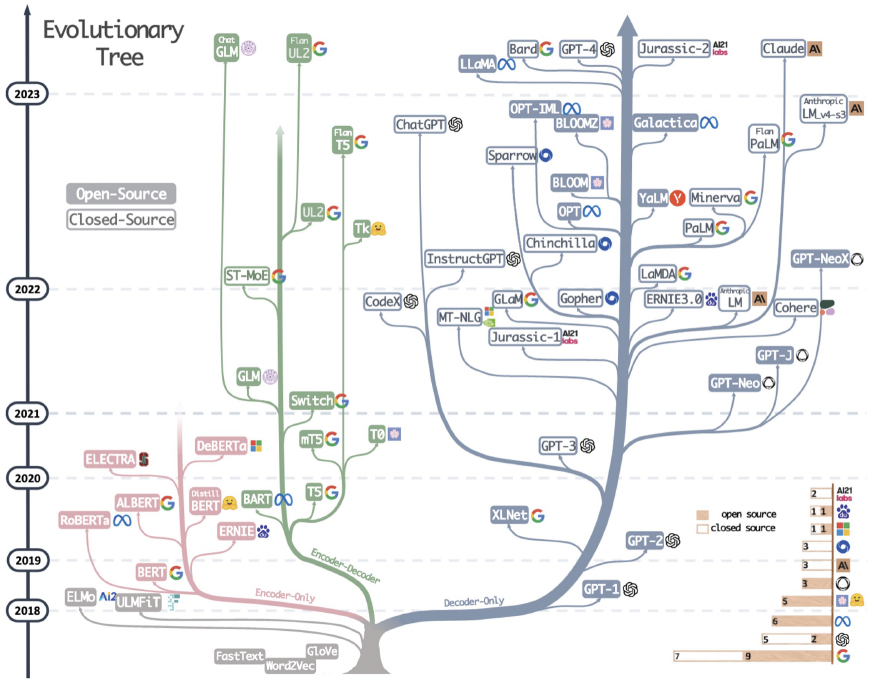
(1) 아키텍처 흐름
- RNN / LSTM / GRU
- Attention-LSTM
- Transformer
(2) Transformer의 활용
- 다량의 데이터를 기반으로 pretrain
- Scalability: model size \(\uparrow \rightarrow\) 성능 \(\uparrow\)
- (Vision) CNN의 inductive bias 극복
- 병렬화를 통한 효율적 연산
(3) LLM의 등장 흐름 1
- Transformer
- by Google / 번역 Task / LLM의 Base
- GPT1
- by OpenAI / Transformer decoder-only / 언어 생성 / Pretrain & Finetune
- BERT
- by Google / Transformer encoder-only / 언어 이해 / Pretrain & Finetune
- GPT2
- by OpenAI / GPT1 + (커진 파라미터,데이터) / 긴 context length / zero-shot (ICL)
(4) LLM의 등장 흐름 2
- XLNet
- by Google + CMU / AR+AE 결합 / AR 학습 방식 (모든 가능한 permutation 학습)
- RoBERTa
- by Facebook / Robustness + BERT / BERT + 훈련 개선 (긴 학습시간, 배치 크기) / NSP 제거
- MASS
- by Microsoft / AR + AE 결합 / 마스킹된 / (E) 마스킹 제외 임베딩 & (D) 마스킹 부분 예측
- BART
- by Facebook / AR + AE 결합 / 입력 텍스트 일부 corrupt & 원래대로 복원
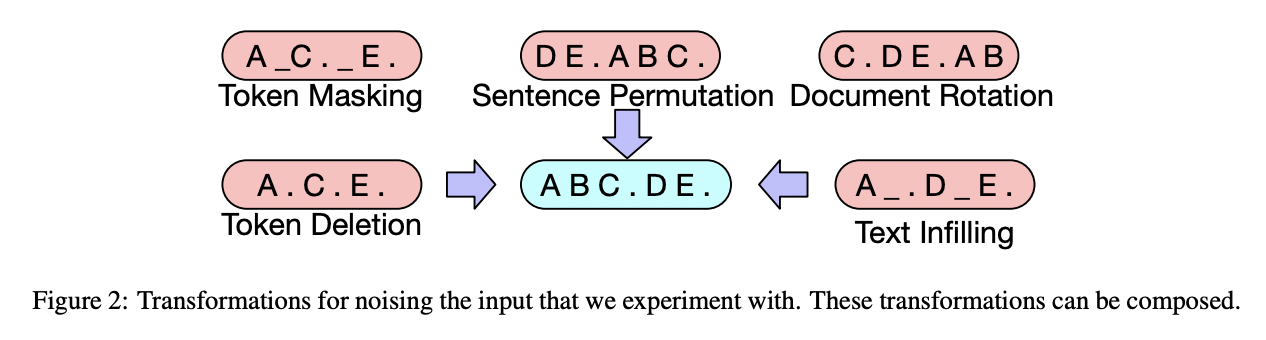
- BART의 corruption
(5) LLM의 등장 흐름 3
- MT-DNN
- by Microsoft / BERT 기반 / 다양한 task
- T5
- by Google / AR + AE / 모든 NLP작업을 Text-to-Text로 치환
- GPT3
- by Open AI / GPT2 확장 (175B) / Zero-shoft
3. LLM의 Components
(1) LLM 작동 방식 및 원리

(2) Tokenizer
-
Token: 텍스트 분할의 최소 단위
-
가장 자주 사용되는 tokenizer: BPE (Byte Pair Encoding) tokenizer
-
빈번하게 등장 \(\rightarrow\) 묶어서 subword 생성
-
장점: 희귀 단어 & 새로운 단어 처리 가능!
(어휘 집합 크기 증가 줄이면서도, 높은 커버리지)
BPE (Byte Pair Encoding) tokenizer
- Step 1) 초기화
- Step 2) 빈도 계산
- Step 3) 쌍 변환
- Step 4) 반복
(3) Decoding Strategy
- Greedy Search: 각 단계에서 가장 높은 확률의 단어를 선택하는 직관적 방식.
- Beam Search: 여러 후보 시퀀스를 유지하며, 최적의 문장을 선택.
- Sampling: 확률 분포를 기반으로 단어를 무작위로 선택.
- Top-k Sampling: 상위 k개의 단어만을 고려해 샘플링.
- Top-p (Nucleus) Sampling: 누적 확률 p에 해당하는 단어 집합에서 샘플링.
4. GPU 자원 & LLM
(1) LLM의 GPU 의존성
- Transformer의 scalability
- # params \(\uparrow\) \(\rightarrow\) GPU 사용량 필요성 \(\uparrow\)
- 병렬성
- 학습 / 추론 시간 단축 위해 필요
- 사전학습 ( + Context length )
- 대규모의 사전 학습 및 긴 입력 길이 위해 필요
- e.g., KV cache
- e.g., ROPE: 더 긴 context length를 handle하기 위해
- Fine-tuning
- 원하는 도메인에 맞게 fine-tuning하기 위해 필요
(2) 기타: ROPE
-
위치 벡터에 회전 변환 적용 \(\rightarrow\) 상대적 위치 정보를 제공.
- 상대적 위치 이해 \(\rightarrow\) 단어 간의 상대적 위치를 잘 이해.
- Attention 메커니즘 성능 향상
- 문맥 이해 향상: 상대적 위치 정보를 제공하므로
(3) 기타: Llama 2 vs. Llama 3.1
| Llama2 | LLama3.1 | |
|---|---|---|
| # params | 7B, 13B, 70B | 8B, 70B, 405B |
| Context Length | 4,096 | 131,072 (실제 학습은 128K) |
| Vocab Size | 32,000 | 128,256 |
| (Pretrain) # Tokens | 2T | 15T + |
Reference
https://fastcampus.co.kr/data_online_gpu