
3. GPU vs CPU
Contents
- Hugging Face
- GPU 사용량
- PEFT
- Single GPU
1. Hugging Face
(1) Hugging Face
-
NLP/ML 분야의 open soruce platform
-
특히, Transformers, peft 라이브러리 쉽게 활용하도록 제공
-
모델 & 데이터셋 공유의 플랫폼
( 오픈소세 모델의 핵심 허브 )
(2) Hugging Face hub
- Git 기반의 플랫폼
- 수 많은 pre-trained model이 호스팅 (최신모델 활용 가능)
- 모델 & 데이터셋 공유
(3) Hugging Face의 라이브러리
Transformers:-
사전 학습된 모델들을 쉽게 불러와 사용
-
여러 NLP 작업에 바로 활용 가능
-
trl:-
Transformer 모델에 강화 학습(RL)을 적용할 수 있는 라이브러리
-
DPO도 적용 가능
-
datasets:- 다양한 공개 데이터셋도 제공
- NLP 관련 작업에 필요한 데이터셋을 쉽게 불러와 사용 가능
peft:- Parameter Efficient Fine-Tuining (PEFT)을 위한 라이브러리
- 더 적은 자원으로 효과적인 학습을 수행 가능
a) Transformers의 핵심 기능
- (1) Pre-trained model 활용 (다양한 NLP 태스크에 바로 적용 가능)
- (2) Fine-tuning
- (3) Tokenizer (각 모델에 최적화된 토크나이저 활용)
b) trl의 핵심 기능
- (1) PPO, RLHF, DPO등 다양한 최적화 방법론 OK
c) datasets의 핵심 기능
- (1) 수천 개의 공개 데이터셋 제공
- (2) 데이터 로드/처리/변환/필터링/샘플링을 간단한 코드로 OK
- (3) 대규모 데이터셋의 효율적 처리
- 데이터 전처리/관리의 복잡성 줄여서 편리함
d) peft의 핵심 기능
- (1) full-finetuning 안하고 효율적으로 가능
- (2) 메모리 절약 + 빠른 학습 가능
- (3) 리소스 제약있는 환경에서 고성능 모델 사용 OK
2. GPU 사용량
(1) GPU 메모리 결정 요소 (by model)
=> Model / Gradient / Optimizer / 활성화함수
(2) 세부 요소
- Model의 메모리
- fp16: 2byte x # params
- fp32: 4byte x # params
- Gradient의 메모리
- 모델의 메모리와 비슷
- Optimizer 의 메모리
- AdamW: 12byte x # params
- 8-bit optimizer: 6byte x # params
\($\rightarrow\)$ 이 외에도, batch size, sequence length에 영향 받음
3. Parameter Efficient Fine-Tuining (PEFT)
(1) Why PEFT?
-
효율적인 resource 사용
- 소수의 param 만을 학습 (특히 대규모 LLM에 필요)
- 양자화 (quantization) 적용 시, 더 저렴하게 학습 가능
-
성능 유지
-
Full-finetuning 시, 기존의 학습 지식 손실 위험
-
이에 반해, PEFT는 핵심만 가성비 있게 조정
\($\rightarrow\)$ 고유의성능 유지하면서도, 새로운 domain/task에 최적화
-
ICL과 비교했을때에도 효율적 + 우수함
-
-
Customizing
- 다양한 task에 customize하는 유연성 제공
- Domain-specific LLM 개발 가능
(2) Full-finetuning
장점
- 적은 데이터로도 OK (feat. LIMA (2023))
- (모두 학습하므로) 잘 튜닝 가정 하에, PEFT 보다 효과적
단점
- 계산 비용 & 자원 소모 높음
- 새로운 데이터 학습 시, 사전 학습 정보 상실 위험
(3) PEFT 기법 소개
a) 기법 1
-
Adapter: 모델의 기존 레이어 사이에 작은 모듈(어댑터)을 삽입하여 일부 파라미터만 미세 조정하는 기법 -
Prompt Tuning: 입력에 특정 프롬프트를 추가하여, 모델이 특정 방식으로 응답하거나 예측하도록 학습시키는 방법 -
Prefix Tuning: 유사하지만, 입력에 추가된 프롬프트가 고정된 텍스트 대신 학습 가능한 벡터 형태로 모델의 앞부분에 추가되는 기법 -
P-Tuning: 입력 데이터에 학습 가능한 프롬프트를 추가하는 방법. 프롬프트는 모델의 입력에 추가되며, 이는 텍스트뿐만 아니라 임베딩(embedding) 벡터의 형태로 표현
b) 기법 2
-
LoRA: 특정 가중치만을 추가하여 학습 (feat. Low rank Decomposition) -
IA3: Q,K,V를 rescale해주는 벡터 + FFNN의 output을 rescale하는 벡터를 추가하여 훈련 -
MORA: LoRA의 square-matrix version (Non-parameter 연산자 통해 compress/decompress) -
DORA: pretrained weight를 크기 & 방향에 따라 분해. 이후에 LoRA 통하여 direction을 update
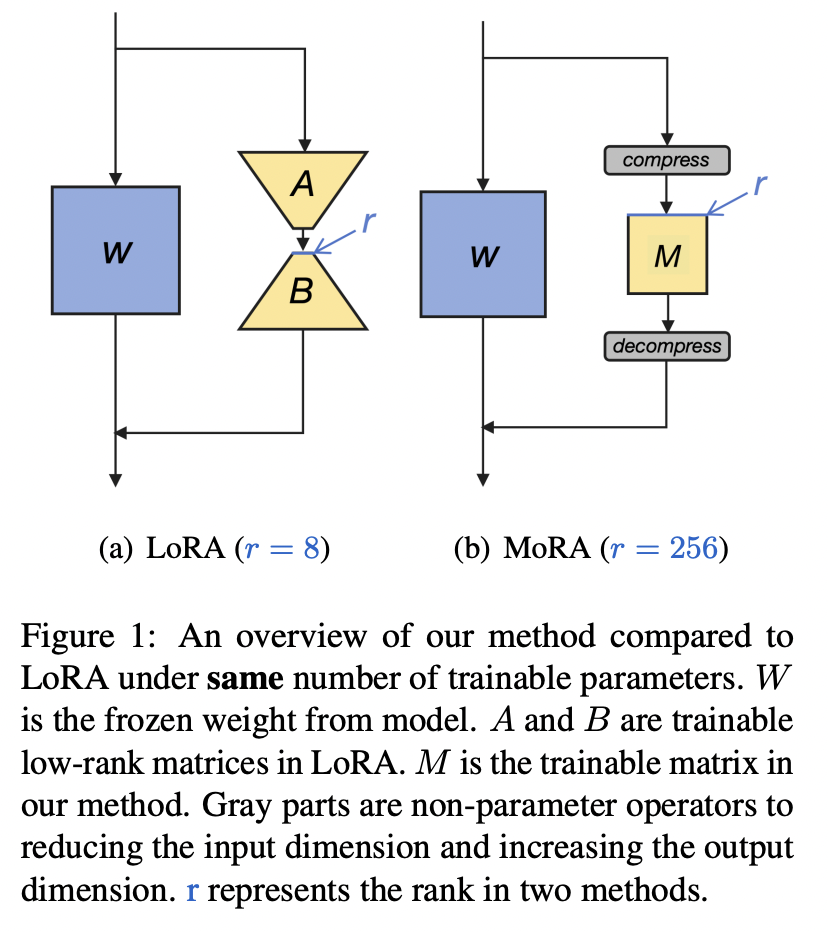
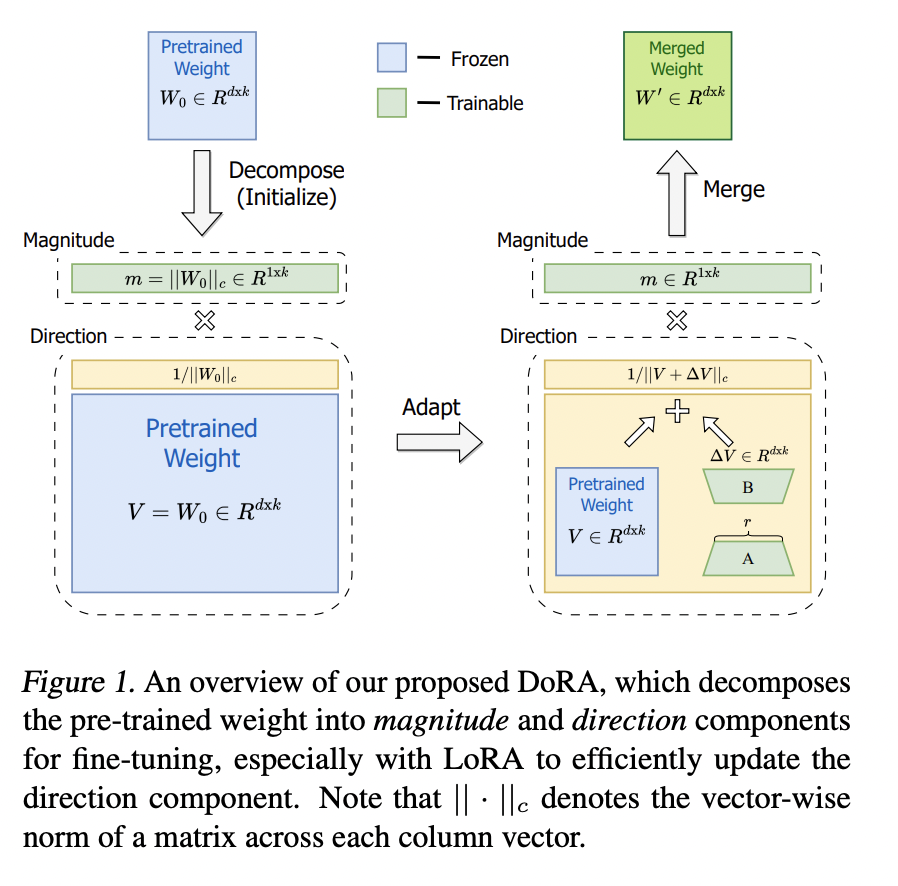
4. Single GPU 환경
(1) 문제점
- Memory 부족: LLM은 # param이 너무 많아서, GPU 메모리 부족해질 수 밖에 없는 구조
- Solution) FP 16으로 전환하거나, BF16을 활용하는 등 메모리 부족 현상 타협가능
- Batch size 제한: 모델의 update과정에서 참고하는 sample 수가 줄어듬
- Solution) “Gradient accumulated steps”, Gradient checking point
- Model size 제한: 특정 모델은 load 조차 되지 않을 수도. 성능 타협 필요하게 될 수 있음
- Inference time 문제: 추론 시에도 많은 계산자원 요구
(2) Solution
- QLoRA: 적은 Fine-tuning을 적용해보자!
- Gradient Accumulated Step: Batch size 줄이고, accumulationd을 늘려서!
- Model Size 타협하기 (feat. sLLM)
- Optimizer: 적은 메모리가 소모되는 옵티마이저 활용
Tip. Trainer에서 제공되는 Optimizer
-
[Background] Transformer 기반의 모델: 주로 adam이나 adamw
-
Optimizer도 메모리를 상당히 잡아먹음! 따라서, 잘 선택해야!
-
Adam_w보다, (제약된 single GPU 상황에서는) 양자회된 optimizer를 쓰는 것도!
\(\rightarrow\)
paged_adamw_8bit&adamw_bnb_8bit adamw_bnb_8bit:- bitsandbytes 라이브러를 사용
- adamw를 8비트로 양자화
paged_adamw_8bit:adamw_bnb_8bit의 개선 버전- 모델 파라미터의 일부만을 메모리에 로드 & 나머지는 디스크에 저장
Reference
https://fastcampus.co.kr/data_online_gpu