
4. 분산 처리 기법
Contents
- 분산처리 기법 소개
- 분산기법의 종류
- Axolotol 라이브러리
1. 분산처리 기법 소개
(1) 분산처리란?
- “하나”의 작업을 “여러” 대의 GPU로 나눠서 병렬로 처리
- 대규모 데이터 / 복잡한 계산을 주로 분산시킴
- 두 가지 종류
- (1) 모델 병렬화
- (2) 데이터 병렬화
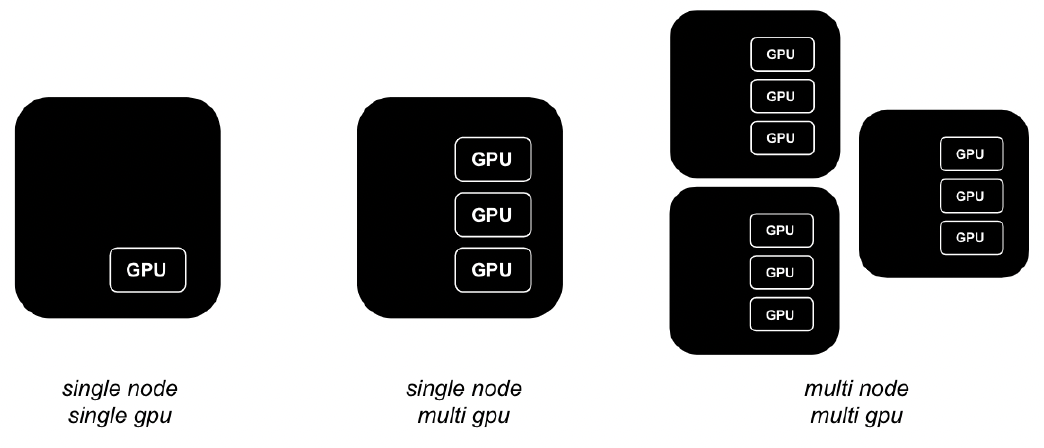
(2) LLM에서 분산처리의 필요성
- 모델 size
- 수십~수천억개의 파라미터
- 12B만되어도 single GPU에서는 많은 한계
- 긴 context (cox) length를 위해서 필요
- FFT 진행을 위해서는 필수적.
- 성능 한계 극복
- 더 많은 자원 활용을 통한 성능 높이기
- 시간 효율성
- Batch size를 더 크게 가져갈 수 있음
- 자원 최적화
- 다양한 서비스 및 고도화된 서비스 deploy 가능
2. 분산기법의 종류
(1) 개요
- a) Data Parallelism (DP)
- b) Model Parallelism (MP)
- Tensor Parallelism (TP)
- Pipeline Parallelism (PP)
- c) Distributed Data Parallelism (DDP)
- d) Fully Sharded Data Parallel (FSDP) \(\rightarrow\) 설명 생략
- e) Zero Redundancy Optimizer (ZeRO) \(\rightarrow\) 설명 생략
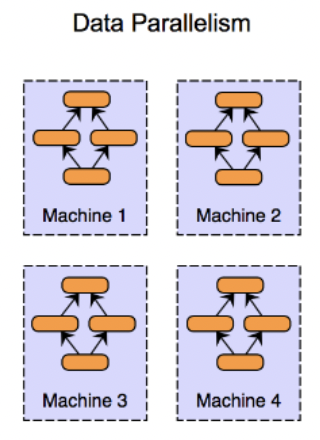
(1) Data Parallelism
핵심: 데이터를 분산시켜서 학습
- 모델을 multi-GPU에 복제해야함
- 속도 최적화 > 메모리 최적화
- (모델 사이즈가 커지는) 최근의 LLM 트렌드와는 거리감 O
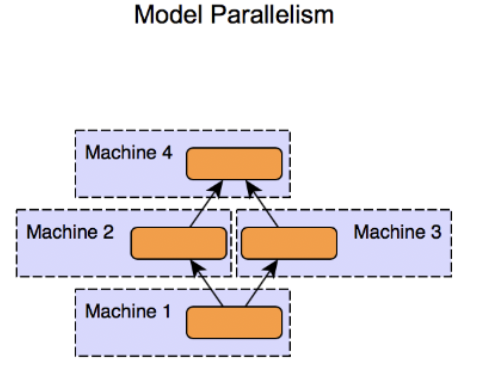
(2) Model Parallelism
핵심: 모델을 분산시켜서 학습
- 각 모델의 모듈을 각각의 GPU에 나눠서 학습
- 큰 모델 처리하는데에 유용
transformers라이브러리에서 쉽게 사용 가능
- 메모리 최적화 > 속도 최적화
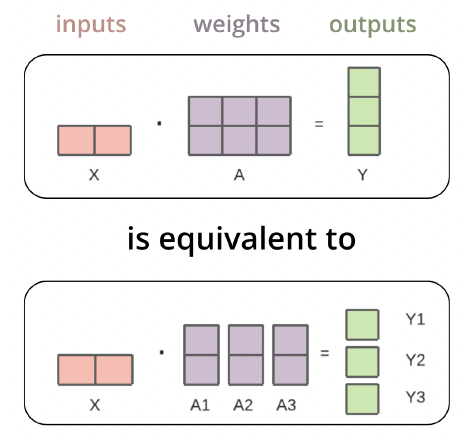
a) Tensor Parallelism
모델의 “각 텐서”를 여러 GPU에 분산
- ex) 행렬 연산
b) Pipeline Parallelism
모델의 “여러 층”을 각 gpu에 나눔
DeepSpeed: Pipeline Parallelism를 지원하는 라이브러리
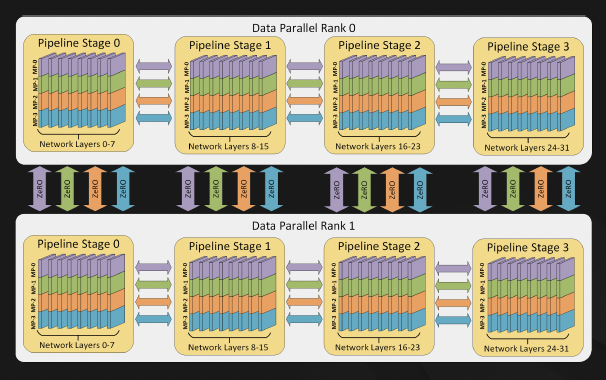
(3) DP vs. DDP
Data Parallelism (DP)
- 개념:
- 전체 모델을 모든 GPU에 동일하게 복제한 후, 미니배치를 여러 GPU에 나누어 처리.
- 각 GPU에서 독립적으로 forward & backward 연산을 수행한 후, 모든 GPU의 그래디언트(gradient)를 중앙에서 모아서 평균을 낸 후 업데이트.
- 단점:
- 중앙 서버(Parameter Server)가 필요하며, 모든 GPU가 그래디언트를 전달하고 받아야 하므로 통신 병목이 발생할 수 있음.
- 보통 싱글 노드(한 대의 서버)에서만 사용됨.
- 예시 (DP 적용 방식)
- 배치 크기 128 → GPU 4개 → 각 GPU가 128/4 = 32개 샘플을 처리.
- 모든 GPU에서 모델을 독립적으로 실행한 후, 그래디언트를 중앙에서 모아 업데이트.
Distributed Data Parallelism (DDP)
- 개념:
- DP와 비슷하지만, 각 GPU가 직접 서로 통신(All-Reduce)하여 그래디언트를 공유.
- 중앙 서버 없이 GPU들이 분산된 방식으로 학습을 수행.
- 싱글 노드뿐만 아니라 멀티 노드(여러 서버) 환경에서도 확장 가능.
- 장점:
- 중앙 서버 없이 각 GPU가 직접 통신하므로, 통신 병목이 줄어듦.
- 멀티 노드(서버 여러 대)에서도 작동 가능하여, 대규모 학습에 적합.
- 예시 (DDP 적용 방식)
- 배치 크기 128 → GPU 4개 → 각 GPU가 32개 샘플을 처리.
- 모든 GPU에서 모델을 독립적으로 실행한 후, 서로 그래디언트를 공유(All-Reduce)하여 평균을 내고 업데이트.
비교 정리
| DP | DDP | |
|---|---|---|
| 서버 수 | 1대 (싱글 노드) | 여러 대 (멀티 노드 가능) |
| 그래디언트 평균 방식 | CPU가 모아서에서 처리 | GPU 간 직접 All-Reduce |
| GPU 간 통신 | GPU간 직접 통신 X | GPU간 직접 통신 O |
| 통신 비용 | 낮음 (대신, CPU에서 모아서 계산하므로 병목 가능성 O) | 증가 (GPU간에 통신하므로) |
| 확장성 | 서버 하나의 GPU 개수에 제한됨 | 여러 서버에 확장 가능 |
| 성능 | CPU 병목 발생 가능 | 더 빠르고 효율적 |
- 작은 규모(싱글 서버)에서는 DP가 간단하고 사용하기 쉬움!
- 대규모 학습(여러 서버 필요)에서는 DDP가 필수적!
All-Reduce 연산이란?
- All-Reduce는 각 GPU가 계산한 그래디언트를 모든 GPU와 공유하고 평균을 내는 연산
- 즉, 각 GPU가 독립적으로 계산한 결과를 모아서 하나의 동일한 값으로 동기화하는 과정
(4) Fully Sharded Data Parallel (FSDP)
-
개념: 모델을 여러 GPU에 쪼개 저장하고, 필요한 부분만 불러와 학습하는 방식
-
특징: 모델 파라미터, 그래디언트, 옵티마이저 상태를 모두 셰어드(분산 저장)하여 메모리를 절약함
-
장점: 초거대 모델도 학습 가능
-
단점: 복잡한 통신 및 데이터 관리가 필요함
FSDP 요약
- FSDP는 모델 병렬화처럼 모델을 GPU에 나눠 저장하지만, 학습 방식은 데이터 병렬화(DP, DDP)와 유사함.
- 기본적으로 DDP와 유사한 데이터 병렬 학습을 수행 (모든 GPU가 전체 학습을 담당)
- 그러나 모델 전체를 복제하지 않고, 각 GPU에 모델을 “Sharding” (조각내어 분산 저장) 함
- DDP 대비 메모리 사용량을 줄일 수 있어, 초거대 모델(LLM 등) 학습에 적합함.
- 네트워크 통신이 추가되지만, 메모리 절약 효과가 크므로 대규모 모델 학습에서 중요한 기법임.
| DDP | Model Parallelism | FSDP | |
|---|---|---|---|
| 모델 저장 방식 | 각 GPU에 모델 전체 복사 | 모델을 여러 GPU에 분할 저장 | 모델을 여러 GPU에 분할 저장 |
| 그래디언트 계산 | 모든 GPU에서 같은 연산 수행 | 각 GPU가 일부 연산 수행 | 모든 GPU에서 같은 연산 수행 |
| 메모리 사용량 | 높음 (모델 전체 유지) | 낮음 (모델 분할 저장) | 낮음 (모델 분할 저장) |
| 네트워크 통신 | All-Reduce (그래디언트 공유) | Pipeline/Tensor 통신 | All-Gather (Sharded 모델 공유) + All-Reduce |
| 확장성 | 제한적 (메모리 부담 큼) | 특정 크기 이상 확장 어려움 | 매우 큰 모델까지 확장 가능 |
All-Reduce vs. All-Gather 차이점
핵심 차이
- All-Reduce: 모든 GPU가 동일한 최종 결과(예: 평균 그래디언트)를 갖도록 통신
- DDP에서 사용
- 그래디언트 업데이트 시 사용됨
- 결과: 모든 GPU가 동일한 평균 그래디언트를 가지므로 일관된 모델 업데이트 가능
- All-Gather: 모든 GPU가 서로의 데이터를 모아야 하는 경우 사용
- FSDP, ZeRO에서 사용
- 분할된 데이터(예: 모델 조각)를 모든 GPU가 모아서 사용할 수 있도록 통신
- FSDP에서는 각 GPU가 모델의 일부만 저장하므로, 순전파·역전파 시 모델 전체를 잠시 필요로 할 때 All-Gather 수행
| All-Reduce | All-Gather | |
|---|---|---|
| 주요 사용처 | DDP (그래디언트 평균) | FSDP (모델 조각 모으기) |
| 목적 | 모든 GPU가 같은 값을 가지도록 통신 | 모든 GPU가 다른 데이터를 모아서 사용 |
| 예제 | 그래디언트 평균화 | 모델 조각을 모아 전체 사용 |
| 통신 방식 | 평균 계산 후 모든 GPU에 전달 | 각 GPU가 다른 GPU의 데이터를 모음 |
(5) Zero Redundancy Optimizer (ZeRO)
-
개념: FSDP와 유사하게, 모델 학습 시 메모리 사용을 줄이기 위한 기술
-
특징: 모델의 가중치, 그래디언트, 옵티마이저 상태를 GPU 간에 분할 저장함
-
단계:
- ZeRO-1: 옵티마이저 상태를 분할
- ZeRO-2: 그래디언트까지 분할
- ZeRO-3: 모델 가중치까지 분할 (FSDP와 유사)
- 장점: 기존 DDP보다 훨씬 적은 메모리로 대형 모델 학습 가능
- 단점: 통신 비용이 증가할 수 있음
(6) FSDP vs. ZeRO
공통점
- 둘 다 GPU 메모리 절약을 위한 기법
- 네트워크 통신을 통해 모델을 분산 저장하거나 업데이트
차이점
- FSDP
- 모델을 완전히 분할(Sharding)하여 각 GPU가 모델의 일부만 저장하도록 함.
- 이를 통해 모델 복제 없이 GPU 메모리 사용량을 최소화하며, 순전파·역전파 시 All-Gather 연산을 통해 모델 조각을 공유함
- ZeRO
- 모델 파라미터는 유지하지만, 옵티마이저 상태(Optimizer States), 그래디언트 는 GPU 간에 분산 저장하거나 계산하여 메모리 효율성을 극대화
- 이는 단계적으로 적용될 수 있으며, All-Reduce 연산을 통해 그래디언트를 동기화함.
| FSDP | ZeRO | |
|---|---|---|
| 모델 저장 방식 | 모델을 여러 GPU에 조각내어 저장 | 모델 전체를 유지하면서 일부 상태만 분산 |
| 네트워크 통신 | All-Gather로 모델 조각을 모음 | All-Reduce로 필요한 정보만 공유 |
| 사용 목적 | 초대형 모델을 학습 가능하게 만듦 | GPU 메모리 사용 최적화 |
(7) 필요한 메모리에 따른 구분
| 구성 요소 | 역할 | DDP에서 저장 방식 | ZeRO에서 저장 방식 |
|---|---|---|---|
| (3) 모델 파라미터 (Weights) | 네트워크가 학습하는 주요 값 | 모든 GPU에 동일하게 저장 | 모델 전체를 유지하면서, 일부 분산 가능 (ZeRO-3) |
| (2) 그래디언트 (Gradients) | 역전파 시 계산되는 기울기 | 모든 GPU가 전체 그래디언트 저장 | 각 GPU가 일부 그래디언트만 저장 |
| (1) 옵티마이저 상태 (Optimizer States) | Adam 등에서 1차·2차 모멘텀 저장 | 모든 GPU가 전체 상태 저장 | 각 GPU가 일부 상태만 저장 |
- 즉, ZeRO는 모델 파라미터(3) 자체를 모든 GPU가 유지하지만, 그래디언트(2)와 옵티마이저 상태(1)를 여러 GPU에 분산 저장하여 메모리 절약을 극대화한다!
(8) ZeRO 단계별 차이 (ZeRO-1, ZeRO-2, ZeRO-3)
| ZeRO 단계 | 최적화 대상 | 메모리 절약 효과 |
|---|---|---|
| ZeRO-1 | 옵티마이저 상태(1)만 분산 저장 | ✅ |
| ZeRO-2 | 옵티마이저 상태(1) + 그래디언트(2) 분산 저장 | ✅✅ |
| ZeRO-3 | 옵티마이저 상태(1) + 그래디언트(2) + 모델 파라미터(3)까지 분산 저장 | ✅✅✅ (FSDP와 유사) |
(9) DDP vs. ZeRO
| DDP | ZeRO | |
|---|---|---|
| 모델 파라미터(3) | 모든 GPU가 복제 저장 | ZeRO-3에서 일부 분산 가능 |
| 그래디언트(2) | 모든 GPU가 복제 저장 | ZeRO-2부터 분산 저장 |
| 옵티마이저 상태(1) | 모든 GPU가 복제 저장 | ZeRO-1부터 분산 저장 |
| 네트워크 통신 | All-Reduce로 그래디언트 평균화 | 필요할 때만 All-Gather 수행 |
| 메모리 최적화 | ❌ (낭비 많음) | ✅ (불필요한 중복 제거) |
(10) 전체 요약
| 기법 | 개념 | 특징 |
|---|---|---|
| DP | 데이터를 나누어 학습 | 모델이 모든 GPU에 복제됨 |
| MP (TP, PP) | 모델을 나누어 학습 | 초거대 모델 학습 가능 |
| DDP | 여러 서버에서 DP 수행 | 확장성 높음 |
| FSDP | 모델을 조각내어 저장 | 메모리 효율적 |
| ZeRO | 메모리 사용 최적화 | 초거대 모델 학습 가능 |
ZeRO와 FSDP는 특히 초거대 모델을 효율적으로 학습하는 데 필수적인 기법!!
3. Axolotl 라이브러리
Goal: LLM을 쉽게 Fine-tuning하기 위해
( Hugging face와의 모델들과의 호환성 good )
- https://github.com/axolotl-ai-cloud/axolotl
주요 기능
- Model finetuning
- LoRA, QLoRA, GPTQ 등
- Multi-GPU 지원
- DeepSpeed & FSDP
- Flash Attention, xformers, ROPE 등의 기술 통합
- Dataset
- JSONL 같은 다양한 포멧 지원
Reference
https://fastcampus.co.kr/data_online_gpu