
GPU 메모리 관리 및 최적화
Contents
- 다양한 메모리 최적화 하이퍼파라미터 조합
- GPU 메모리 계산 - 구성요소
- Model Parameter
- Gradient
- Optimizer State
- Optimizer 비교
- AdamW
- Lion
- 8-bit Adam
- Adafactor
- Accumulated Step & Gradient Checkingpoint & Context Length
- Accumulated Step
- Gradient Checkingpoint
- Context Length
- Summary
1. 다양한 메모리 최적화 하이퍼파라미터 조합
- Optimizer
- Accumulated Steps
- Gradient Checkingpoint
- 자원 최적화
2. GPU 메모리 계산 - 구성요소
(1) Model Parameter
- 파라미터 수를 \(P\)라고 하면,
- FP32 (32-bit) 사용 시: \(4P\) 바이트
- BF16 / FP16 사용 시: \(2P\) 바이트
- ex) 70B 모델, FP16 → 2×70B=140GB
(2) Gradient
- 학습 중에는 각 파라미터에 대해 gradient를 저장해야 함!
- FP32 사용 시: \(4P\) 바이트
- BF16 / FP16 사용 시: \(2P\) 바이트
- ex) 70B 모델, FP16 → 2×70B=140GB
(3) Optimizer State (Adam 기준)
- Adam: 2개의 모멘텀 벡터 (m,v)를 저장해야 하므로,
- FP32 사용 시: \(8P\) 바이트
- BF16 / FP16 사용 시: \(4P\) 바이트
- ex) 70B 모델, FP16 → 4×70B=280G
총합 정리 (FP16 + Adam 기준)
| 모델 파라미터 | Gradient | Optimizer 상태 | 합계 | |
|---|---|---|---|---|
| 70B 모델 | 140GB | 140GB | 280GB | 560GB |
3. Optimizer 비교
(1) AdamW (기본 Adam 포함)
- AdamW는 1차, 2차 모멘텀 벡터 \((m,v)\)를 저장함.
- FP32 기준: \(8P\) 바이트 (\(4P\) for \(m\), \(4P\) for \(v\))
- FP16 / BF16 기준: \(4P\) 바이트
- ✅ 장점: 안정적인 학습
- ❌ 단점: 메모리 소모가 큼
(2) Lion (Less Memory Intensive Optimizer)
- AdamW와 달리 2차 모멘텀을 사용하지 않음.
- FP32 기준: \(4P\) 바이트 (\(4P\) for \(m\))
- FP16 / BF16 기준: \(2P\) 바이트
- ✅ 장점: 메모리 절약, 속도 향상
- ❌ 단점: 일부 모델에서 AdamW 대비 학습 성능 저하 가능
(3) 8-bit Adam (Quantized Adam)
- 모멘텀 벡터를 8-bit로 양자화하여 저장함.
- 일반적으로 \(2P\) 바이트로 줄어듦.
- 메모리 사용량:
- \(2P\) 바이트 (8-bit로 저장된 \(m,v\))
- 추가적인 보정 변수 필요 시 약간의 추가 메모리
- ✅ 장점: 메모리 절감 효과 큼
- ❌ 단점: 일부 모델에서 안정성 문제 발생 가능
(4) Adafactor (Extreme Memory Efficiency)
- 모멘텀을 행렬 분해 방식으로 저장하여 메모리 사용량을 극도로 절감.
- 일반적으로 \(O(\sqrt{P})\) 수준의 메모리만 필요함.
- ✅ 장점: 초대형 모델 학습 시 매우 효율적
- ❌ 단점: 성능 최적화가 어렵고, 특정 설정에서 불안정할 수 있음
(5) LoMo (Low-Memory Optimizer)
- 1차 모멘텀 (\(m\))만 저장하고 2차 모멘텀을 제거하여 최소한의 메모리 사용
- FP32 기준: \(2P\) 바이트 (\(2P\) for \(m\))
- FP16 / BF16 기준: \(P\) 바이트
- ✅ 장점: 모든 옵티마이저 중 가장 적은 메모리 사용량
- ❌ 단점: AdamW보다 학습 안정성이 낮을 수 있음
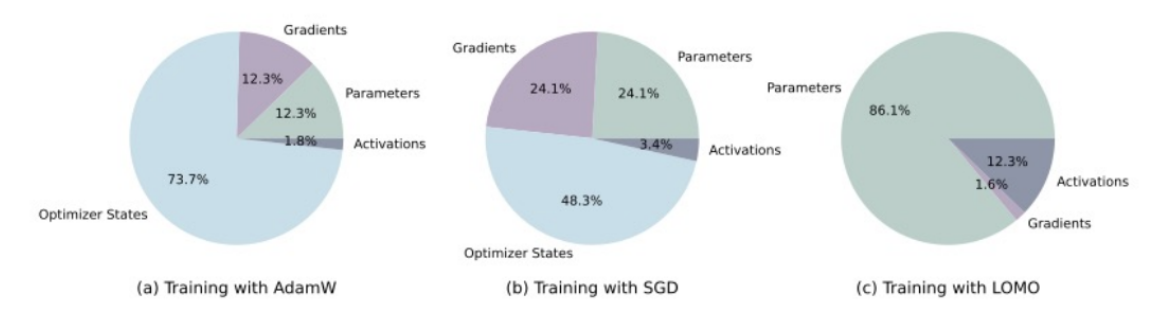
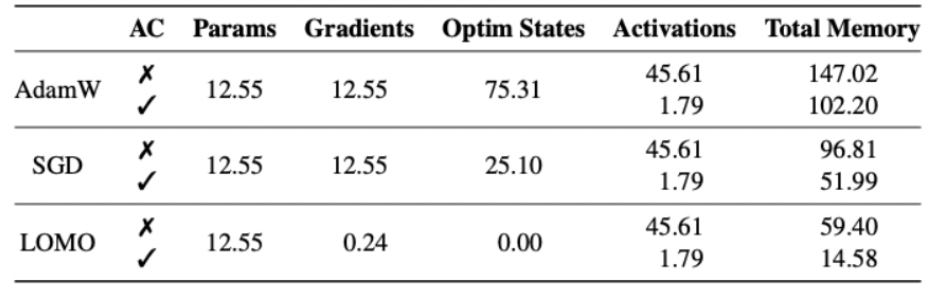
Optimizer 메모리 사용량 비교 (FP16 기준)
| 옵티마이저 | 메모리 사용량 |
|---|---|
| AdamW | \(4P\) |
| Lion | \(2P\) |
| 8-bit Adam | \(2P\) (양자화됨) |
| Adafactor | \(O(\sqrt{P})\) |
| LoMo | \(P\) |
💡 결론:
- 메모리를 많이 쓸 수 있다면 → AdamW 사용 (안정적인 학습)
- 메모리 절약이 필요하다면 → 8-bit Adam, Lion
- 극단적인 메모리 절약이 필요하다면 → Adafactor, LoMo
4. Accumulated Step & Gradient Checkingpoint & Context Length
(1) Accumulated Step
- 메모리가 부족한 경우, Batch size를 늘리는 대신 Accumulated step를 늘려도 됨!
-
메모리 효율적 & 더 많은 배치를 통해 weight를 업데이트
- 단점/유의할점
- (1) 더 긴 훈련 시간
- (2) lr, scheduler등을 잘 조정해줘야!
(2) Gradient Checkingpoint
위에서도 언급했듯, Gradients또한 큰 메모리를 차지함!
일반적인 NN 학습 시, forward에서 gradients를 계산하기 위해 각 노드의 계산값을 저장하게 됨
- 장점) 빠름 (backprop시 활용할 때, 재계산 불필요)
- 단점) 메모리 소모량하
\(\rightarrow\) Grandient checking point를 enable 함으로써 메모리 절감 효과!
기타 사항
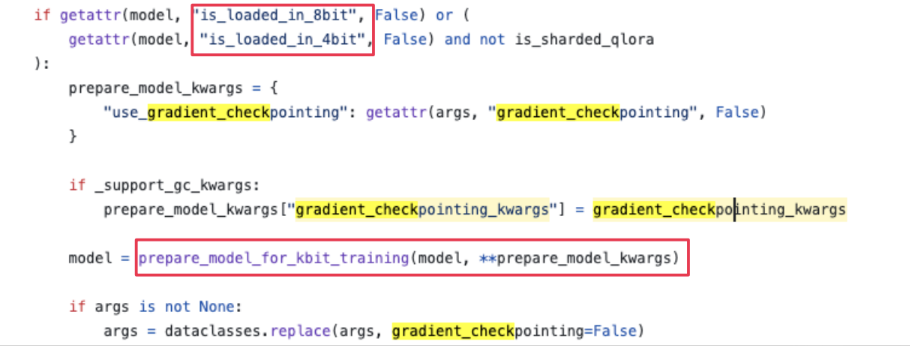
- QLoRA의 경우)
prepare_kbit_training()적용 시 gradient checking point가 풀리는 경우가 있음!- 해결책:
SFTTrainer를 쓰면, 앞단에서prepare_kbit_training()이 불필요해서, 메모리적인 이점 볼 수 있음
- 해결책:
(3) Context Length
무조건 긴 context length가 좋은 것은 아닐 수 있다!
(\(\because\) 메모리적인 측면)
KV Cache 메모리!
2 x batch size x # layers x # heads x d_head x CONTEXT LENGTH x precision
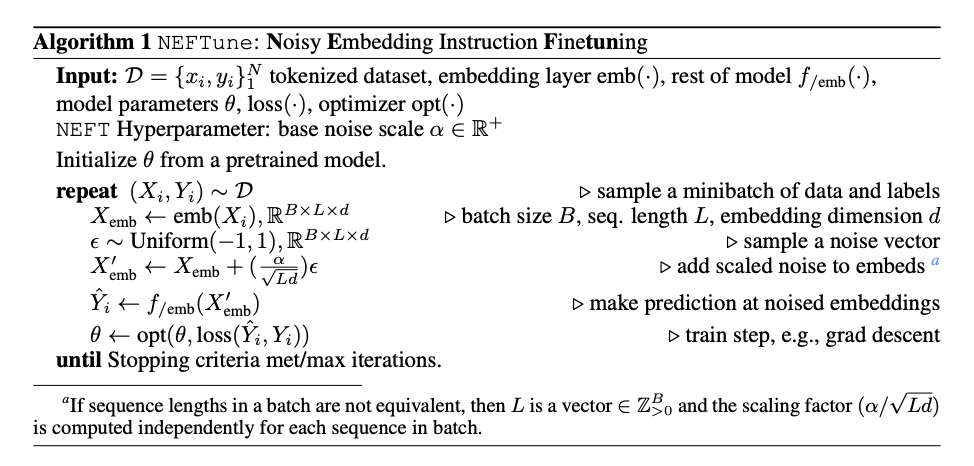
5. Neft Tune
https://arxiv.org/pdf/2310.05914
- What? LLM의 fine-tuning 기법 중 하나
- Goal? Model의 robustness를 높이자!
-
How? Add random noise to the embedding vectors of the training data during the forward pass of fine-tuning
- Training (O), Inference (X) 시에 부여!

6. Summary

Reference
https://fastcampus.co.kr/data_online_gpu