
Gradient Checkpointing
1. Forward 시 Activation 저장
저장 이유?
- Backprop을 위해서, 순전파 때 계산한 활성화 값(activation)이 필요
예시) 3-layer NN
[Forward]
- Layer 1:
- \(z_1=W_1x+b_1z_1 = W_1 x + b_1\).
- \(a_1=f(z_1)a_1 = f(z_1)\).
- Layer 2:
- \(z_2=W_2a_1+b2z_2 = W_2 a_1 + b_2\).
- \(a_2=f(z_2)a_2 = f(z_2)\).
- Layer 3 (출력층):
- \(z_3=W_3a_2+b3z_3 = W_3 a_2 + b_3\).
- \(a_3=f(z_3)a_3 = f(z_3)\).
[Backward]
손실 함수 \(L\) 에 대한 가중치 \(W\) 의 미분(그래디언트) \(\frac{\partial L}{\partial W}\) 를 구하려면, 체인룰 적용 필요!
\(\frac{\partial L}{\partial W_3}=\frac{\partial L}{\partial z_3} \cdot \frac{\partial z_3}{\partial W_3}\).
- 여기서 \(\frac{\partial z_3}{\partial W_3}=a_2\).
\(\rightarrow\) 족, 순전파 때 계산한 \(a_2\) 가 필요!
3층의 그래디언트:
\(\begin{aligned} &\frac{\partial L}{\partial W_3}=\frac{\partial L}{\partial z_3} \cdot \frac{\partial z_3}{\partial W_3}\\ &\frac{\partial z_3}{\partial W_3}=a_2 \end{aligned}\).
2층의 그래디언트:
\(\begin{gathered} \frac{\partial L}{\partial W_2}=\frac{\partial L}{\partial z_2} \cdot \frac{\partial z_2}{\partial W_2} \\ \frac{\partial z_2}{\partial W_2}=a_1 \end{gathered}\).
요약
- 각 층에서 가중치의 그래디언트를 계산하려면, 그 층의 입력(activation)이 필요
- 역전파를 수행할 때마다 각 층의 activation을 다시 계산하면 “비효율적”이므로 순전파 때 저장!
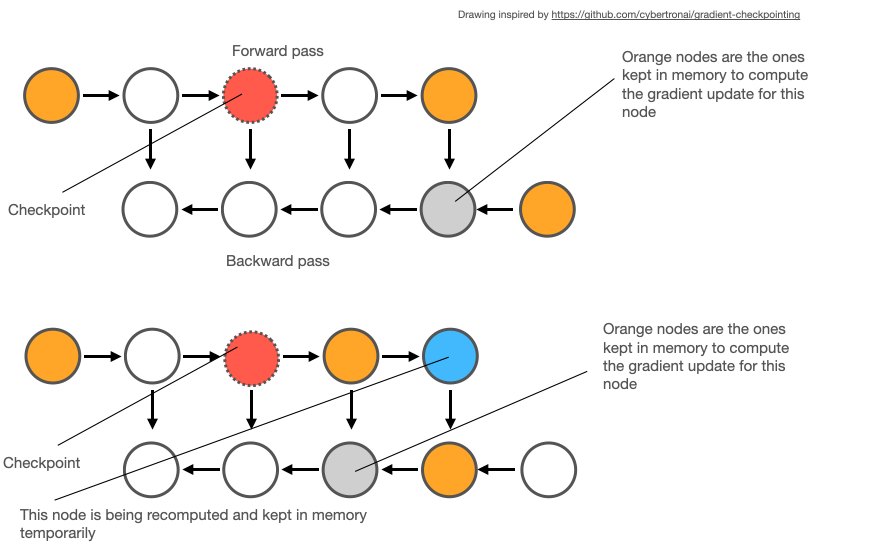
2. Gradient Checkpointing의 원리
Gradient Checkpointing은 모든 activation을 저장하는 대신….
\(\rightarrow\) 일부만 저장하고, 나머지는 역전파 때 다시 계산하는 방법이야.
Example
- Layer 1의 \(a_1\) 만 저장하고
- Layer 2, Layer 3의 \(a_2\), \(a_3\) 는 저장X
\(\rightarrow\) 역전파 시 다시 계산해야 하지만, 메모리를 절약할 수 있음!
3. Code
import torch
import torch.nn as nn
import torch.utils.checkpoint as checkpoint
class SimpleMLP(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(10, 20)
self.fc2 = nn.Linear(20, 20)
self.fc3 = nn.Linear(20, 5)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = checkpoint.checkpoint(self.checkpointed_block, x) # Gradient Checkpoint 적용
x = self.fc3(x)
return x
def checkpointed_block(self, x):
return torch.relu(self.fc2(x))
# 모델 및 입력 생성
model = SimpleMLP()
x = torch.randn(1, 10)
# Forward Pass
output = model(x)
checkpoint.checkpoint(self.checkpointed_block, x)
self.fc2(x)에서 발생하는 activation을 저장하지 않음.- 역전파 시 다시 계산하여 그래디언트를 구함.