[Paper Review] 06.Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
Contents
- Abstract
- Introduction
- Related Work
- Representation Learning from Unlabeled data
- Generating Natural Images
- Visualizing the internals of CNNs
- Approach and Model Architecture
- Details of Adversarial Training
0. Abstract
- supervised learning with CNNs : HOT
- UNsupervised learning with CNNs : less attention
\(\rightarrow\) bridge the gap between supervised & unsupervised
propose DCGANs ( = Deep Convolutional GANs )
- learns a hierarchy of representations from object parts to scenes in both generator & discriminator
1. Introduction
learn feature representations from large UNlabled datasets
This paper proposes..
- 1) train GAN
- 2) reuse parts of the G & D networks as feature extractors for supervised tasks
Contributions
- (1) introduce DCGAN
- (2) trained discriminator for image classification
- (3) visualize the filters learnt by GANs
2. Related Work
(1) Representation Learning from Unlabeled data
- skip
(2) Generating Natural Images
main 2 categories
- 1) parametric
- has been explored extensively
- ex) GAN
- however, have not leveraged generators for supervised tasks
- 2) non-parametric
- matching from a database of existing images
(3) Visualizing the internals of CNNs
NN = black-box methods
Solution
-
deconvolutions & filtering the maximal activations
\(\rightarrow\) find the approximate purpose of each convolution filters
3. Approach and Model Architecture
attempts to scale up GANs using CNNs…unsuccessful
\(\rightarrow\) LAPGAN (2018)
- iteratively upscale low resolution generated images
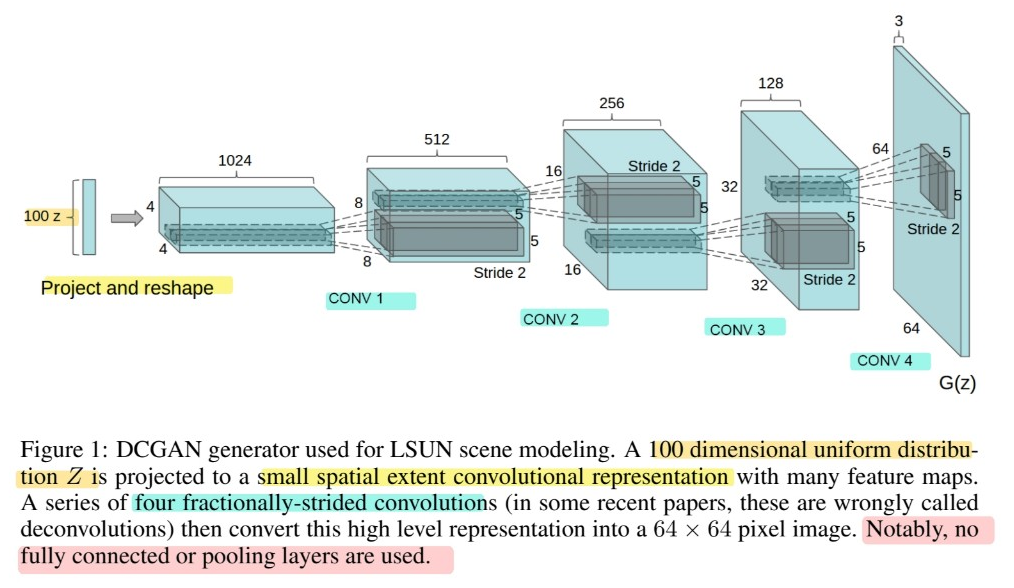
Architecture guidelines for stable DCGANs
Core approach ( = adopt & modify 3 recent changes to CNN )
[1] spatial pooling functions (ex. maxpooling) \(\rightarrow\) STRIDED CONVOLUTONS
- learn its OWN spatial downpooling
[2] ELIMINATE FC layers on top of convolutional features
[3] use BATCH NORMALIZATION
- prevent generator from collapsing all samples to a single point
4. Details of Adversarial Training
- no-preprocessing besides scaling
- SGD with mini-batch size 128
- initial weights ~ \(N(0,0.02^2)\)
- Adam optimizer
- Leakly ReLU’s slope = 0.2
- learning rate : 0.0002