
[Paper Review] 09.A Simple Framework for Contrastive Learning of Visualized Representations
Contents
- Abstract
- Introduction
- Method
- The Contrastive Learning Framework
- Training with Large Batch Size
- Data Augmentation for Contrastive Representation Learning
0. Abstract
SimCLR를 제안한다
- simple framework for contrastive learning
contrastive learning이란?
- 현재의 이미지와 매칭이 되는 이미지의 특징 벡터를 가깝게, 현재 이미지와 다른 데이터에 대해서는 특징 벡터가 멀어지도록 학습
- (참고 : http://dmqm.korea.ac.kr/activity/seminar/308 )
Show that…
-
composition of data augmentations : critical role in defining effective predictive task
-
introduce a learnable non-linear transformation between the
- representation
- contrastive loss
substantially improves the quality of learned representation
-
contrastive learning benefits from larger batch sizes
1. Introduction
Learning effective visual representations
[ Generative approach ]
-
learn to generate OR model pixels into input space
-
BUT, pixel-level generation : computationally expensive
[ Discriminative approach ]
-
via objective functions, similar to those used in supervised learning
-
train networks to perform pretext tasks, where both the inputs & labels are derived from an unlabeled dataset
Introduce a simple framework for contrastive learning of visual representations, SimcLR
2. Method
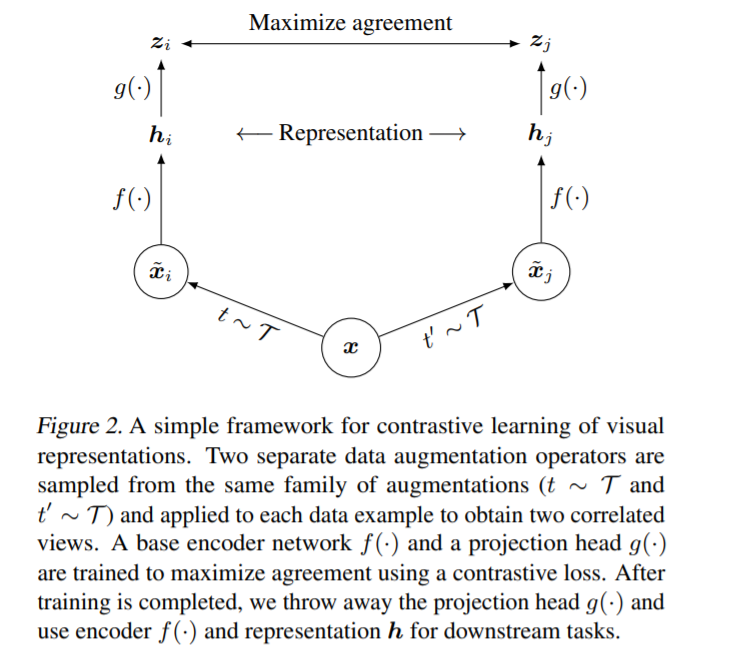
2-1. The Contrastive Learning Framework
SimCLR learns representations, by…
“maximizing agreement between DIFFERENTLY AUGMENTED views of the same data example, via a CONTRASTIVE LOSS in the latent space”
4 major components
- 1) stochastic data augmentation module
- 2) NN base encoder \(f(\cdot)\)
- 3) NN projection head \(g(\cdot)\)
- 4) Contrastive Loss Function
1) stochastic data augmentation module
- transforms any data randomly
- notation : \(\tilde{\boldsymbol{x}}_{i},\tilde{\boldsymbol{x}}_{j}\) ( = called positive pair )
- sequentially apply 3 simple augmentations
- (1) random cropping ( + resize back )
- (2) random color distortions
- (3) random Gaussian blur
2) NN base encoder \(f(\cdot)\)
-
extract representations from augmented data examples
-
use ResNet
-
\(\boldsymbol{h}_{i}=f\left(\tilde{\boldsymbol{x}}_{i}\right)=\operatorname{ResNet}\left(\tilde{\boldsymbol{x}}_{i}\right)\).
( where \(\boldsymbol{h}_{i} \in \mathbb{R}^{d}\) is the output after the average pooling layer )
-
3) NN projection head \(g(\cdot)\)
- map representations to the space, where constrastive loss is applied
- use MLP ( one hidden layer )
- \(\boldsymbol{z}_{i}=g\left(\boldsymbol{h}_{i}\right)=W^{(2)} \sigma\left(W^{(1)} \boldsymbol{h}_{i}\right)\).
- beneficial to define contrastive loss on \(\boldsymbol{z}_{i}\) ‘s rather than \(\boldsymbol{h}_{i}\) ‘s.
4) Contrastive Loss Function
- set \(\left\{\tilde{\boldsymbol{x}}_{k}\right\}\) including a positive pair of examples \(\tilde{\boldsymbol{x}}_{i}\) and \(\tilde{\boldsymbol{x}}_{j}\)
- contrastive prediction task :
- identify \(\tilde{\boldsymbol{x}}_{j}\) in \(\left\{\tilde{\boldsymbol{x}}_{k}\right\}_{k \neq i}\) for a given \(\tilde{\boldsymbol{x}}_{i}\)
Sample a minibatch of \(N\) examples
-
after augmentations… \(2N\) data points
-
do not explicitly sample negative samples…
the other \(2(N-1)\) augmented samples are negative examples
Similarity & Loss
-
similarity measure : \(\operatorname{sim}(\boldsymbol{u}, \boldsymbol{v})=\boldsymbol{u}^{\top} \boldsymbol{v} / \mid \mid \boldsymbol{u} \mid \mid \mid \mid \boldsymbol{v} \mid \mid\)
-
loss function ( for positive pair ) : \(\ell_{i, j}=-\log \frac{\exp \left(\operatorname{sim}\left(\boldsymbol{z}_{i}, \boldsymbol{z}_{j}\right) / \tau\right)}{\sum_{k=1}^{2 N} \mathbb{1}_{[k \neq i]} \exp \left(\operatorname{sim}\left(\boldsymbol{z}_{i}, \boldsymbol{z}_{k}\right) / \tau\right)}\).
-
Final Loss : computed across all positive pairs ( both \((i,j)\) and \((j,i)\) )

2-2. Training with Large Batch Size
vary the training batch size from 256 to 8192
- ex) 8192 \(\rightarrow\) 16382 negative examples ( \(2N=2(8192-1)\) )
- large batch size… use LARS optimizer
Global BN
-
[problem] as positive pairs are computed in same device,
the model can exploit local information leakage to improve prediction accuracy, without improving representations
-
[solution] aggregating BN mean & variance over ALL devices
3. Data Augmentation for Contrastive Representation Learning
결론 1) composition of data augmentation operations is crucial for learning good representations
-
consider several common augmentations
- ex) cropping / resizing / rotation / cutout
-
always apply crop & resize
-
Steps
-
step 1) [always] randomly crop images & resize them to same resolution
-
step 2) apply the targeted transformations ONLY to one branch
( leaving the other one as identity \(t(x_i) = x_i\) )
-

결론 2) Contrastive learning needs stronger data augmentation, than supervised learning