Pytorch Geometric Review 1 - intro
( 참고 : https://www.youtube.com/c/DeepFindr/videos )
1. Message Passing Update & Aggregation Function

2. GNN Variants
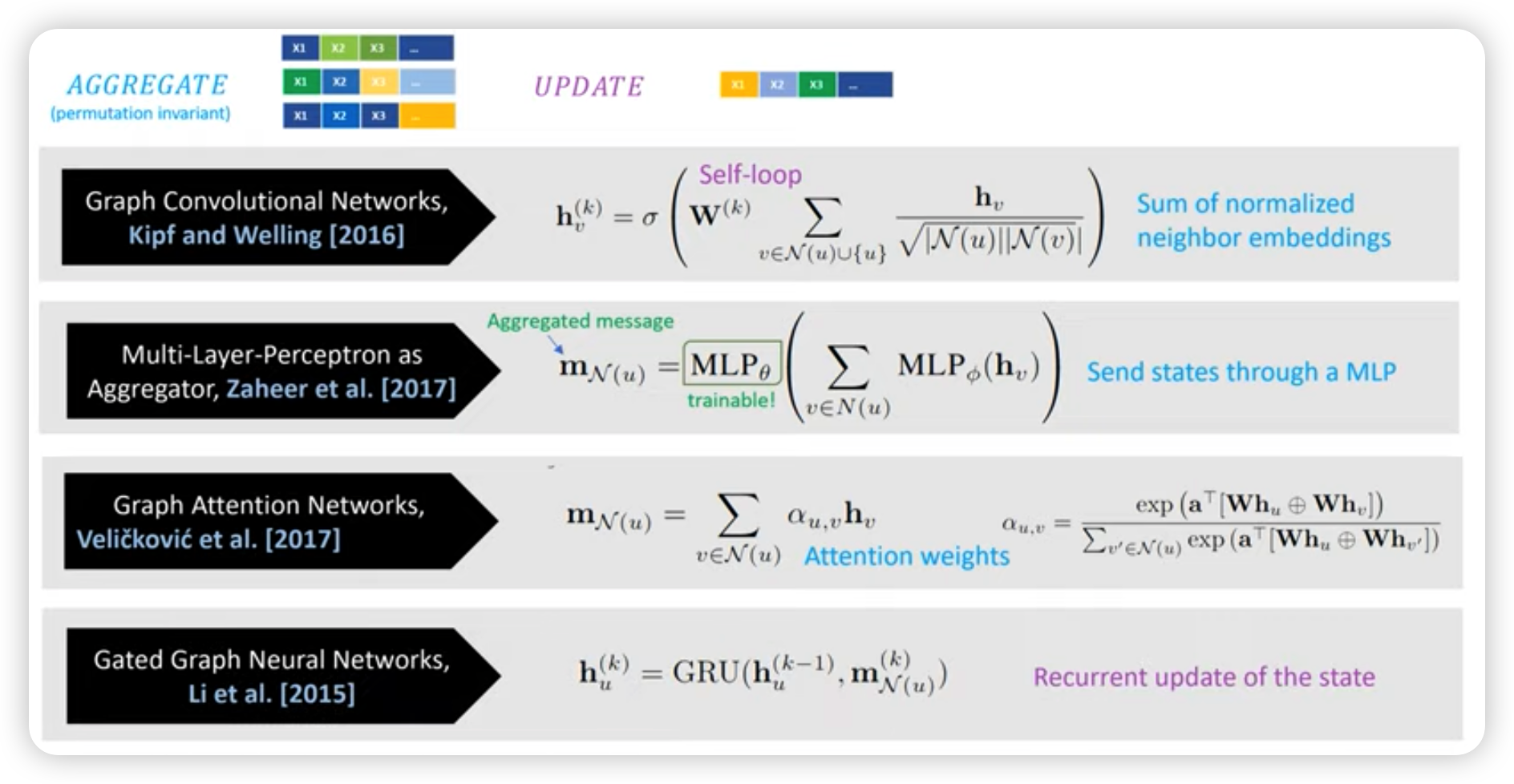
3. GNN intro
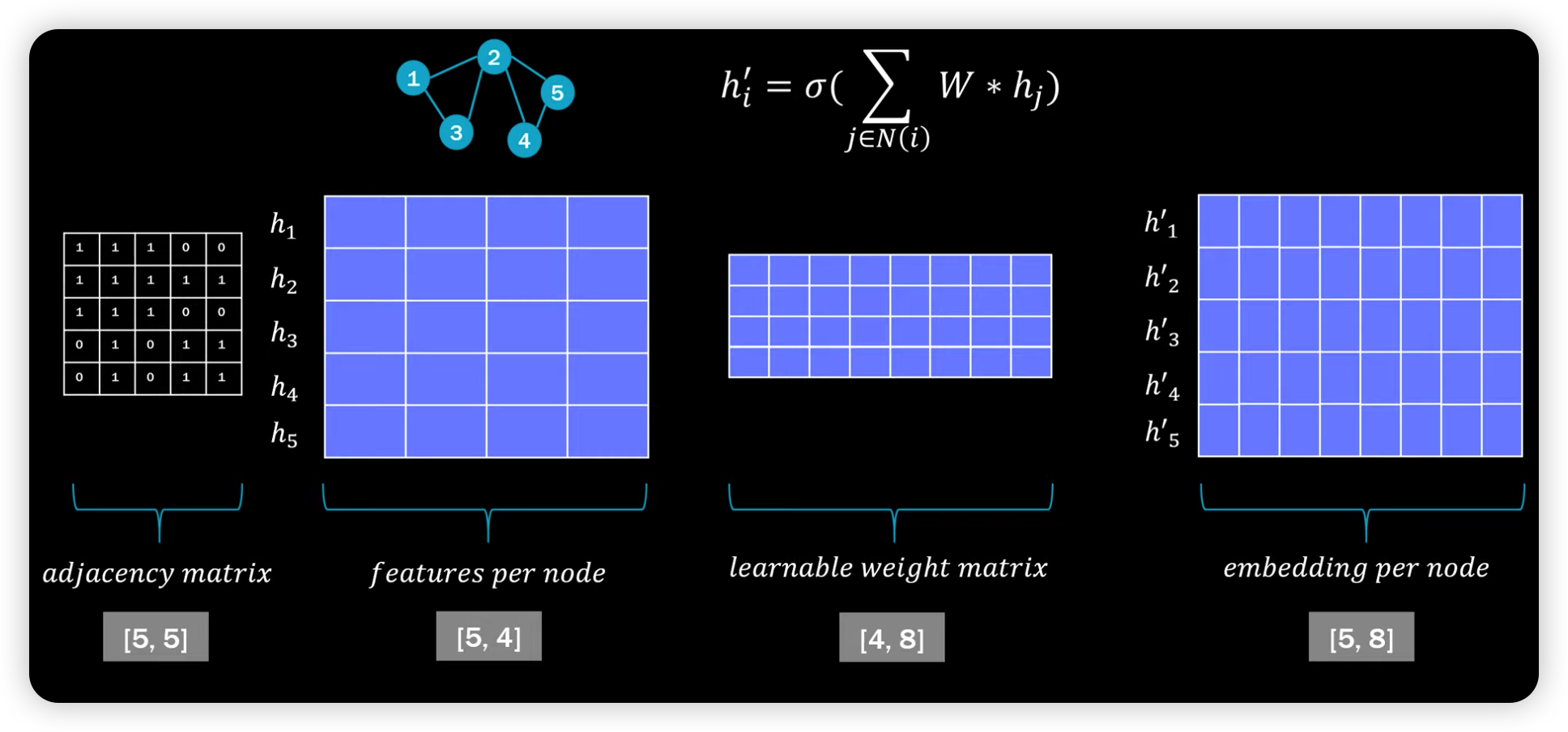
(1) Vanilla GNN
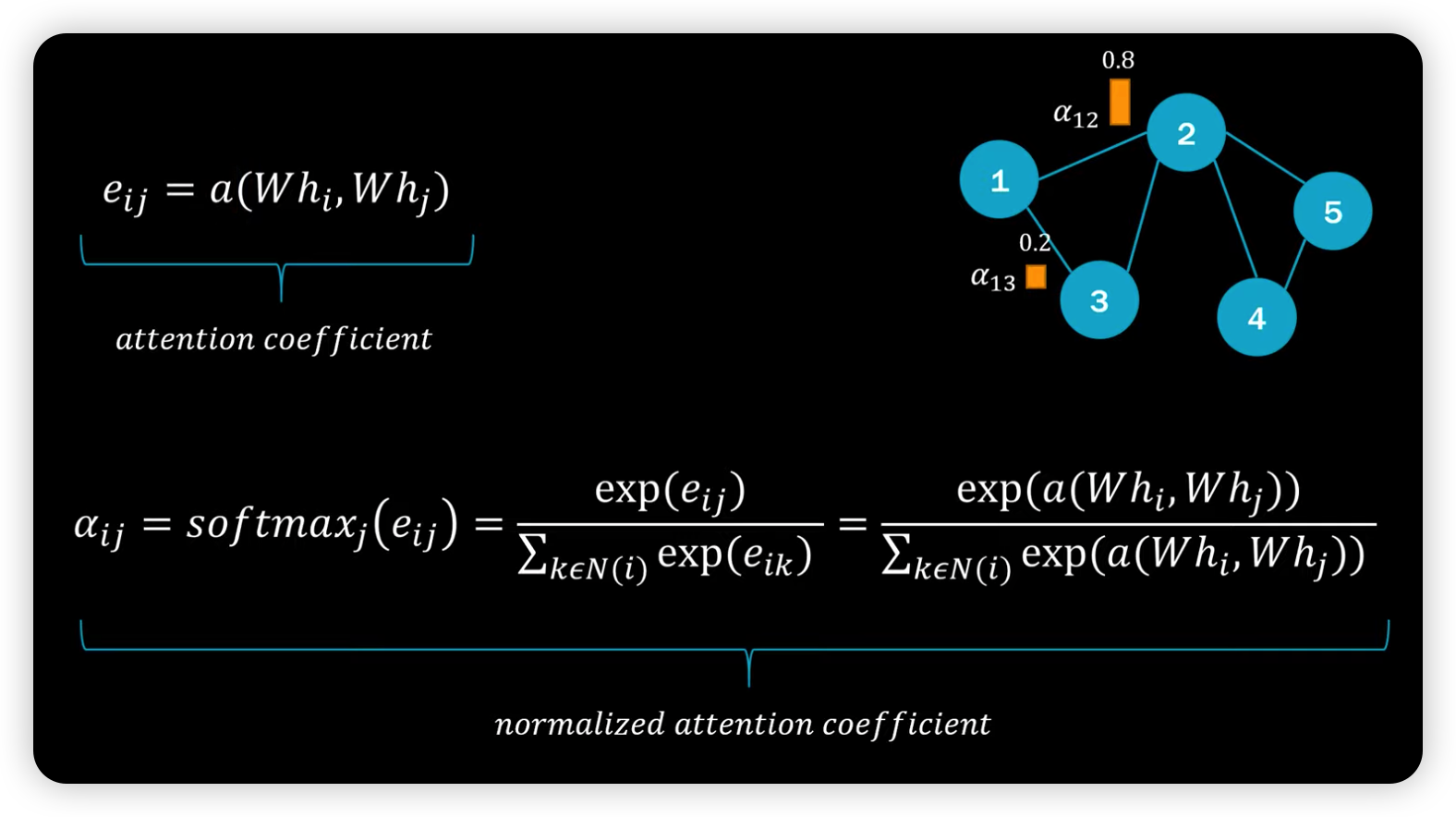
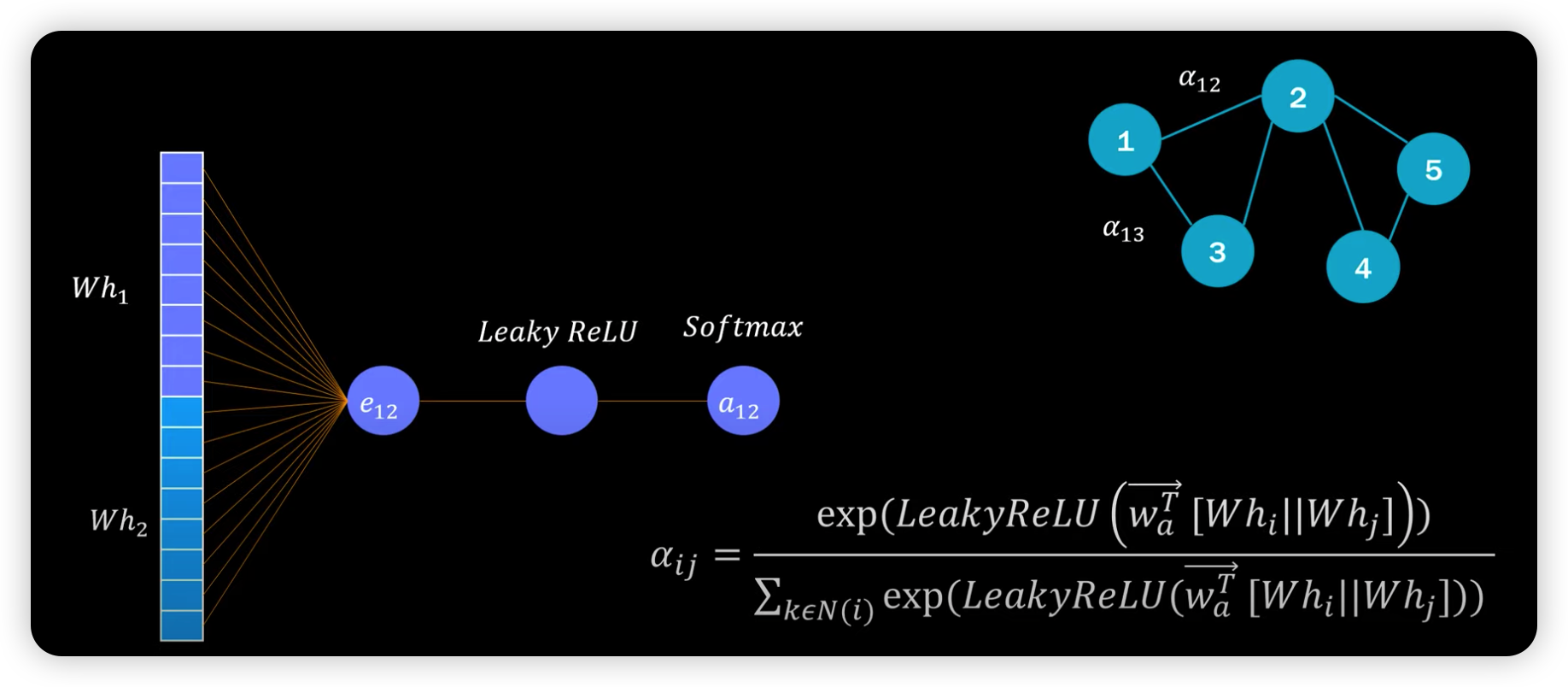
(2) GAT
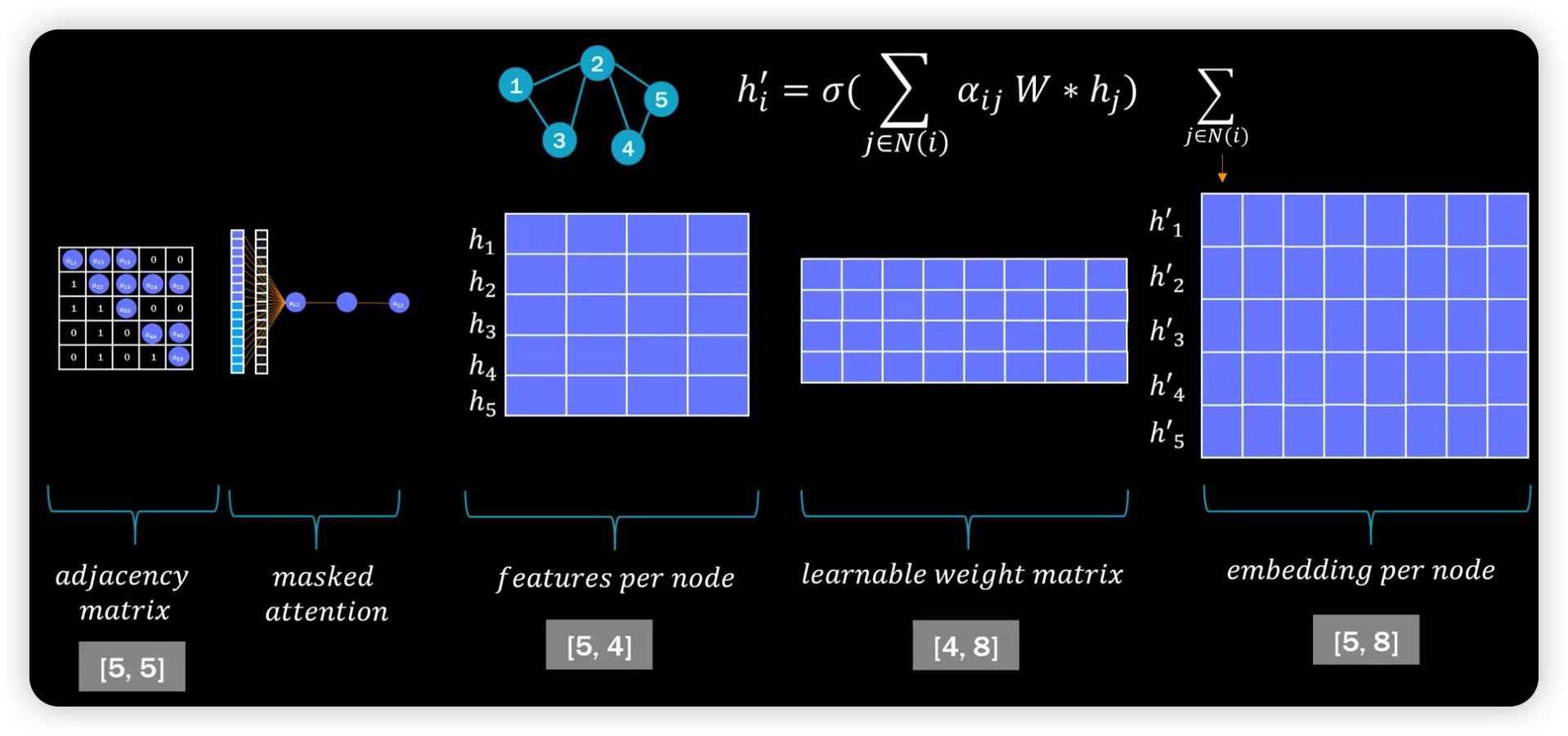
안에를 자세히 들여다보면, 아래와 같다.
3. Pytorch Geometric Example
(1) Summary of Dataset
import rdkit
from torch_geometric.datasets import MoleculeNet
data = MoleculeNet(root=".", name="ESOL")
print("Dataset type: ", type(data))
print("Dataset features: ", data.num_features)
print("Dataset target: ", data.num_classes)
print("Dataset length: ", data.len)
print("Dataset sample: ", data[0])
print("Sample nodes: ", data[0].num_nodes)
print("Sample edges: ", data[0].num_edges)
Dataset type: <class 'torch_geometric.datasets.molecule_net.MoleculeNet'>
Dataset features: 9
Dataset target: 734
Dataset length: <bound method InMemoryDataset.len of ESOL(1128)>
Dataset sample: Data(x=[32, 9], edge_index=[2, 68], edge_attr=[68, 3], y=[1, 1], smiles='OCC3OC(OCC2OC(OC(C#N)c1ccccc1)C(O)C(O)C2O)C(O)C(O)C3O ')
Sample nodes: 32
Sample edges: 68
(2) Graph Convolutional Network
import torch
from torch.nn import Linear
import torch.nn.functional as F
from torch_geometric.nn import GCNConv, TopKPooling, global_mean_pool
from torch_geometric.nn import global_mean_pool as gap, global_max_pool as gmp
embedding_size = 64
class GCN(torch.nn.Module):
def __init__(self):
# Init parent
super(GCN, self).__init__()
torch.manual_seed(42)
# GCN layers ( for Message Passing )
self.initial_conv = GCNConv(data.num_features, embedding_size)
self.conv1 = GCNConv(embedding_size, embedding_size)
self.conv2 = GCNConv(embedding_size, embedding_size)
self.conv3 = GCNConv(embedding_size, embedding_size)
# Output layer ( for scalar output ... REGRESSION )
self.out = Linear(embedding_size*2, 1)
def forward(self, x, edge_index, batch_index):
hidden = F.tanh(self.initial_conv(x, edge_index))
hidden = F.tanh(self.conv1(hidden, edge_index))
hidden = F.tanh(self.conv2(hidden, edge_index))
hidden = F.tanh(self.conv3(hidden, edge_index))
# Global Pooling (stack different aggregations)
### (reason) multiple nodes in one graph....
## how to make 1 representation for graph??
### use POOLING!
### ( gmp : global MAX pooling, gap : global AVERAGE pooling )
hidden = torch.cat([gmp(hidden, batch_index),
gap(hidden, batch_index)], dim=1)
out = self.out(hidden)
return out, hidden
model = GCN()
print(model)
print("Number of parameters: ", sum(p.numel() for p in model.parameters()))
GCN(
(initial_conv): GCNConv(9, 64)
(conv1): GCNConv(64, 64)
(conv2): GCNConv(64, 64)
(conv3): GCNConv(64, 64)
(out): Linear(in_features=128, out_features=1, bias=True)
)
Number of parameters: 13249
(3) Training
build model & optimizer & loss function
from torch_geometric.data import DataLoader
import warnings
warnings.filterwarnings("ignore")
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.0007)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)
Data Loader
data_size = len(data)
NUM_GRAPHS_PER_BATCH = 64
loader = DataLoader(data[:int(data_size * 0.8)],
batch_size=NUM_GRAPHS_PER_BATCH, shuffle=True)
test_loader = DataLoader(data[int(data_size * 0.8):],
batch_size=NUM_GRAPHS_PER_BATCH, shuffle=True)
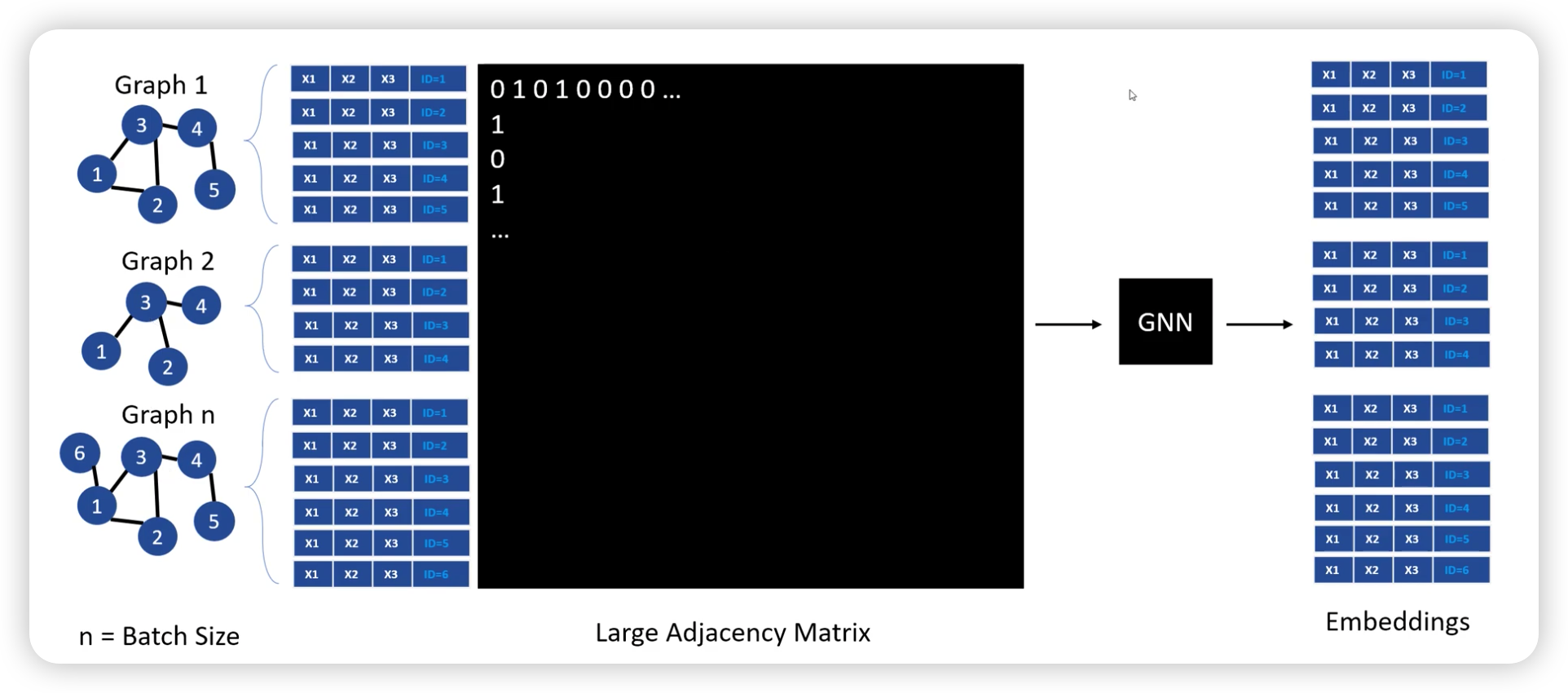
주의 : batch size는, “노드의 개수”가 아니라, “그래프 자체의 개수”이다!
def train(data):
for batch in loader:
batch.to(device)
optimizer.zero_grad()
#---------------------------------------------------------------#
# data : (1) node features & (2) connection info
# [batch.x] : torch.Size([796, 9]) ... 64개 그래프 내에 총 796개의 노드 & 각각 8차원
# [batch.edge_index] : torch.Size([2, 1602]) ... 64개 그래프 내에 총 1602개의 엣지
# [batch.batch] : torch.Size([796]) ... 64개 그래프 내에 총 796개의 노드
# 각 노드가 어느 그래프에서 왔는지의 정보 ( 0,0,0...,63,63 )
# [pred] : torch.Size([64, 1]) .... 그래프 당 1개의 예측값
# [embedding] : torch.Size([64, 128]) .... 그래프 당 1개의 임베딩
pred, embedding = model(batch.x.float(), batch.edge_index, batch.batch)
#---------------------------------------------------------------#
loss = torch.sqrt(loss_fn(pred, batch.y))
loss.backward()
optimizer.step()
return loss, embedding
print("Starting training...")
losses = []
for epoch in range(2000):
loss, h = train(data)
losses.append(loss)
if epoch % 100 == 0:
print(f"Epoch {epoch} | Train Loss {loss}")
4. EDGES
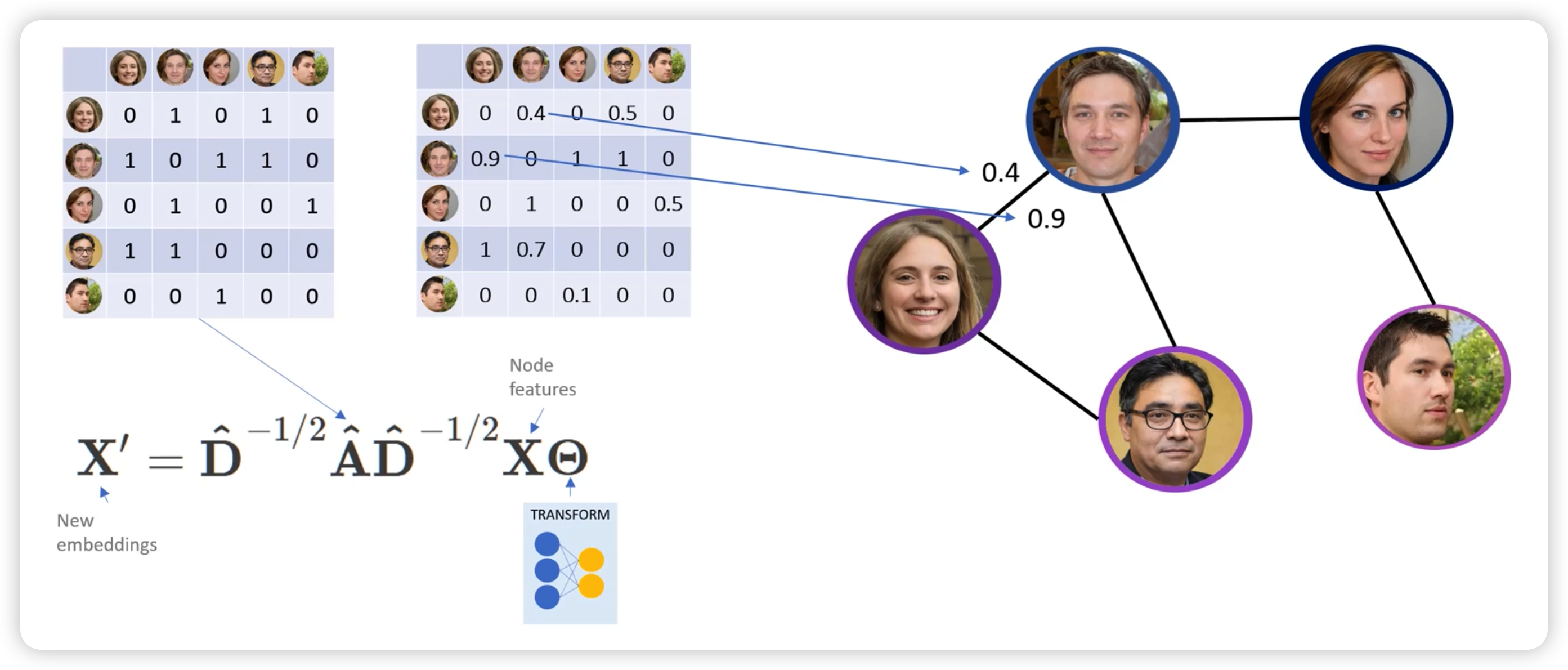
(1) Edge with weight
(2) Different type of edges
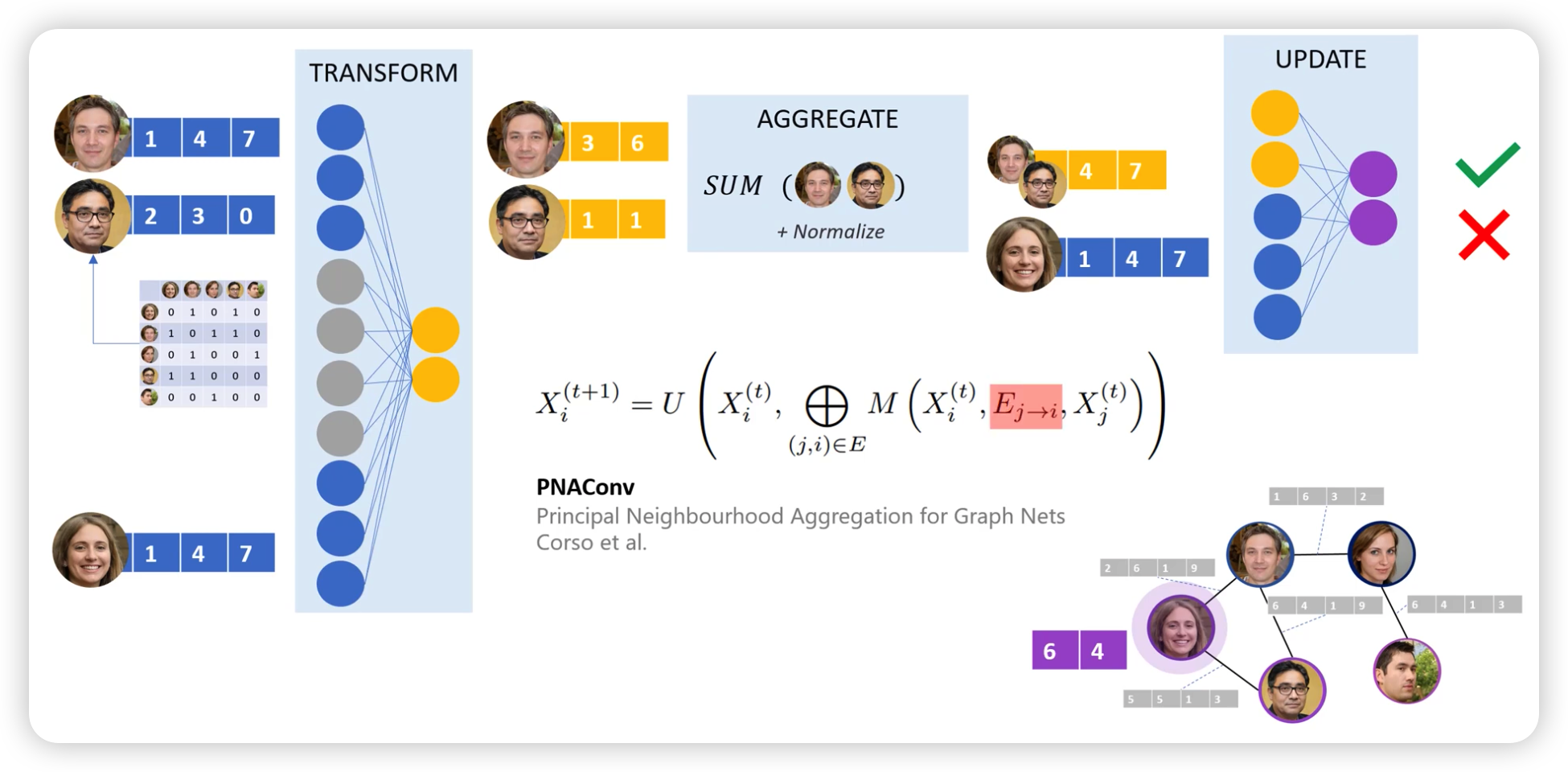
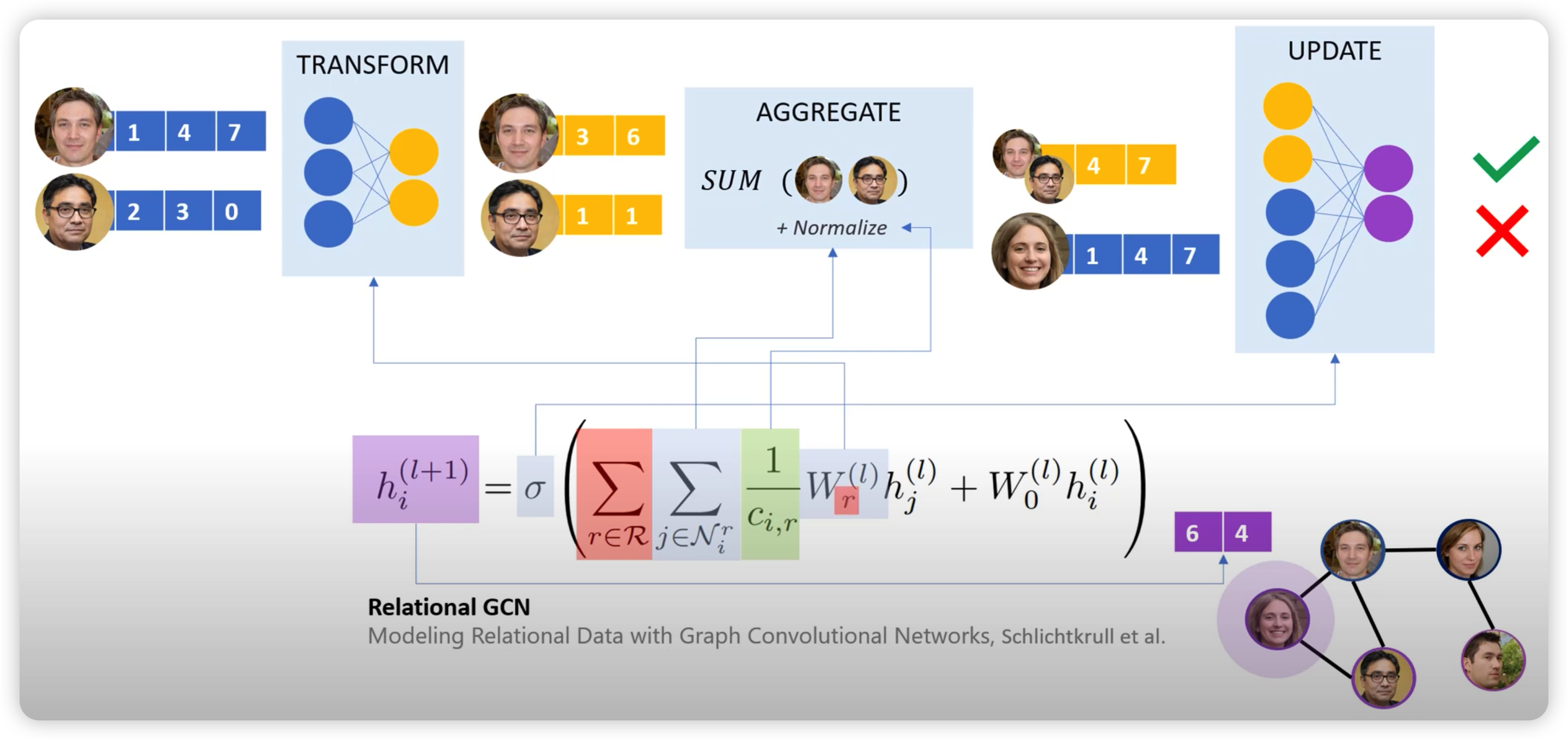
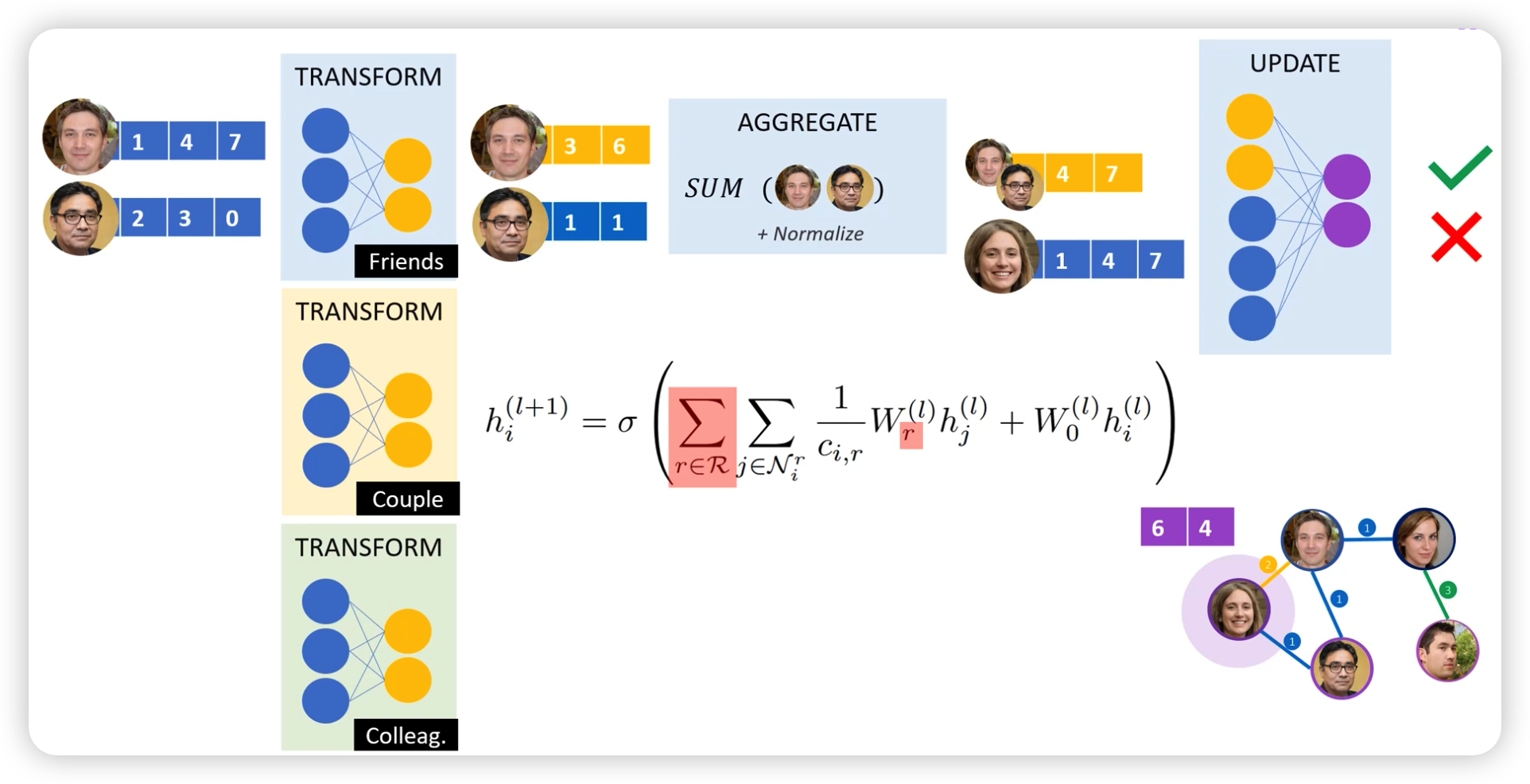
Edge에 다양한 class/category가 존재할 수 있다.
이에 따라 서로 다른 weight matrix를 사용하게끔 할 수 있다 ( Relational GCN )
( 아래 그림의 “빨간색 summation” 부분 )
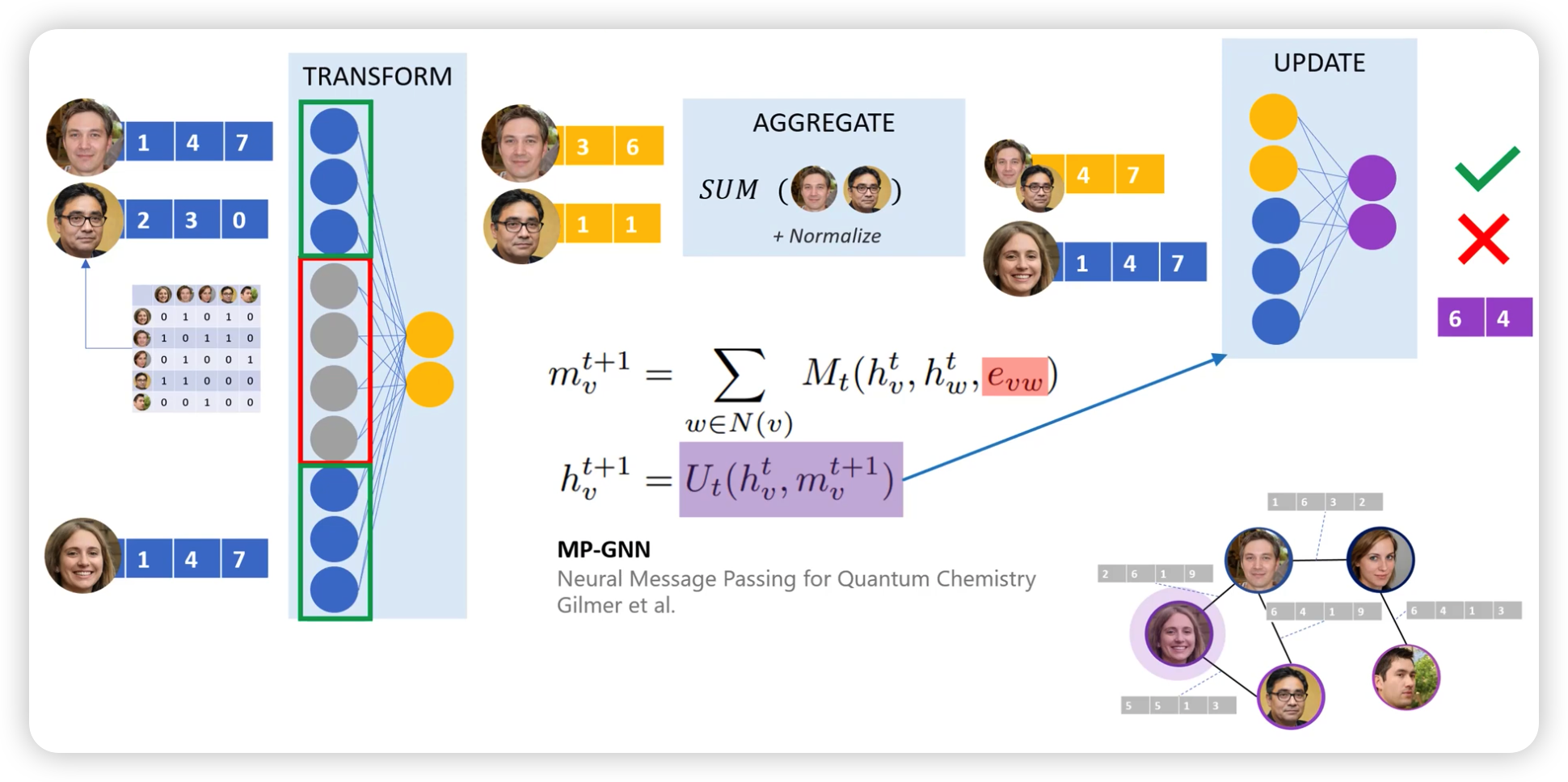
(3) Multidimensional Edge features

Message를 생성할때, additional info로써 사용한다

ex) MP-GNN
ex) PNA-Conv