
Pytorch Geometric Review 2 - Graph Level Prediction
( 참고 : https://www.youtube.com/c/DeepFindr/videos )
How to make graph representation vector?
- (1) Naive global Pooling
- (2) Hierarchical Pooling
- (3) Super / virtual / dummy node
1) Naive global Pooling
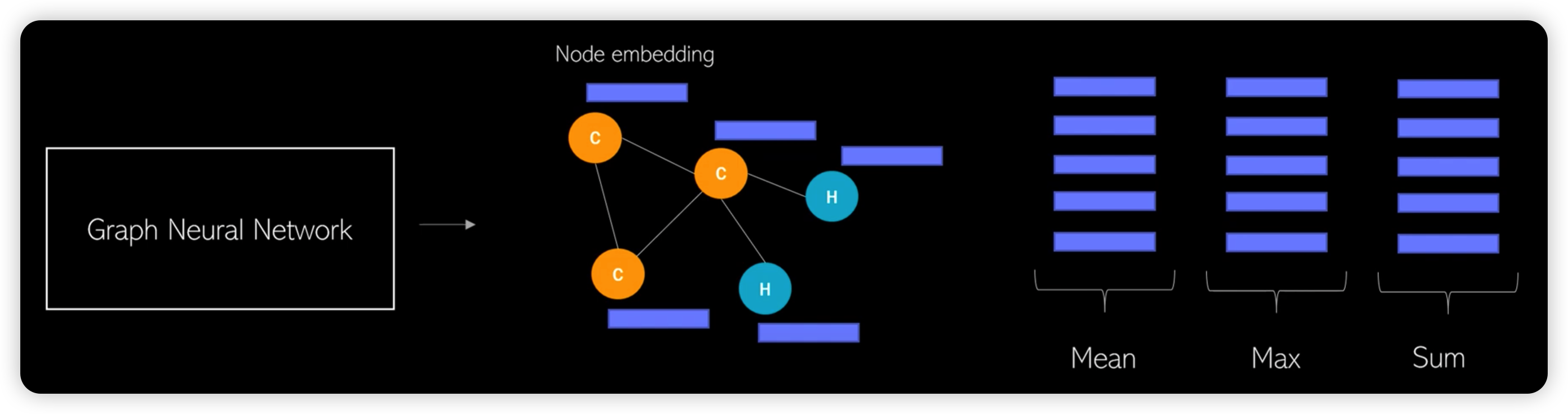
2) Hierarchical Pooling
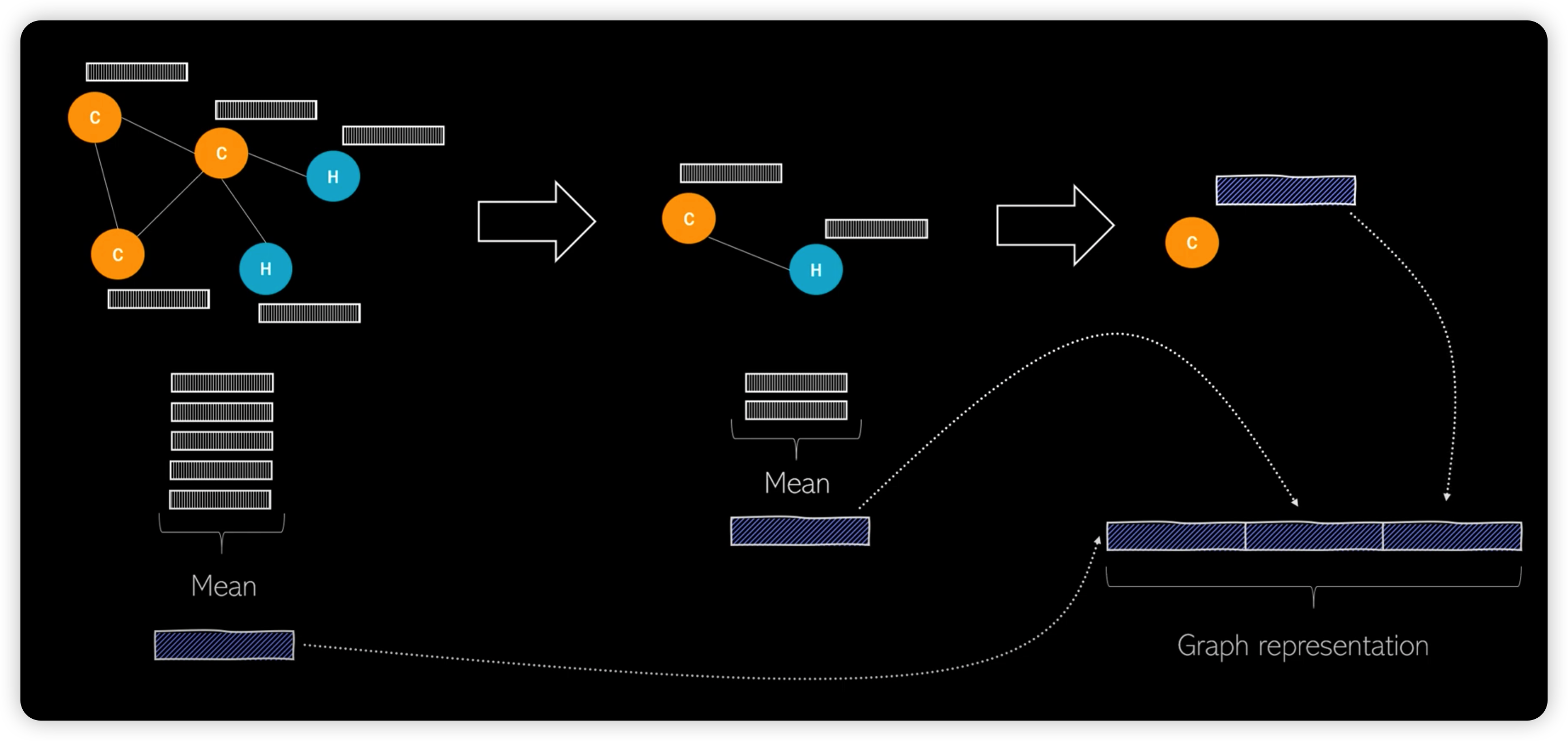
How to pool nodes? ( = select nodes )
- (1) differentiable pooling
- (2) top K Pooling
3) Super / virtual / dummy node
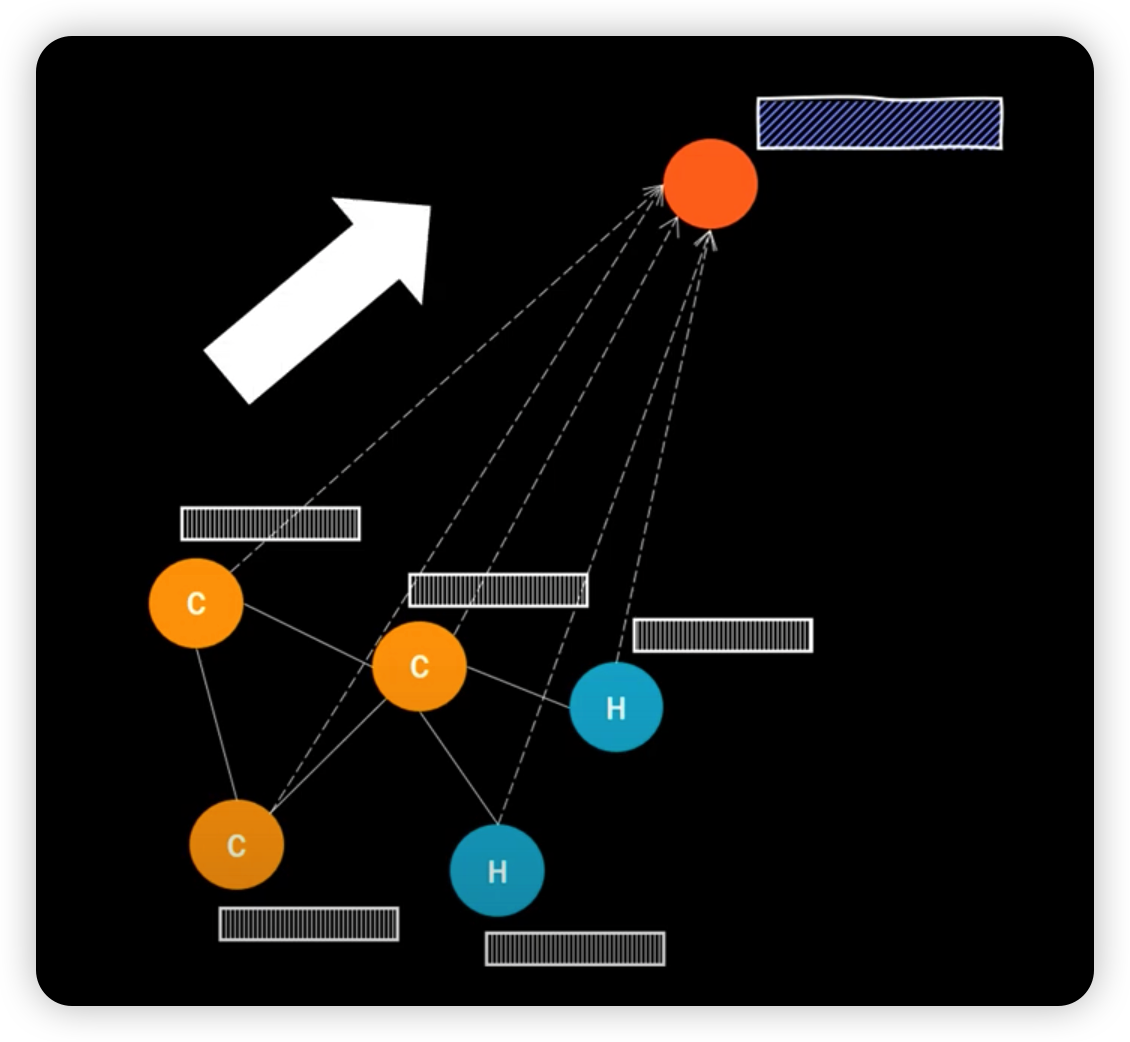
add additional node, which is connected to every node!
- directed edge
- all nodes \(\rightarrow\) super node (O)
- super nodes \(\rightarrow\) all nodes (X)
4) Model Architecture
Overview
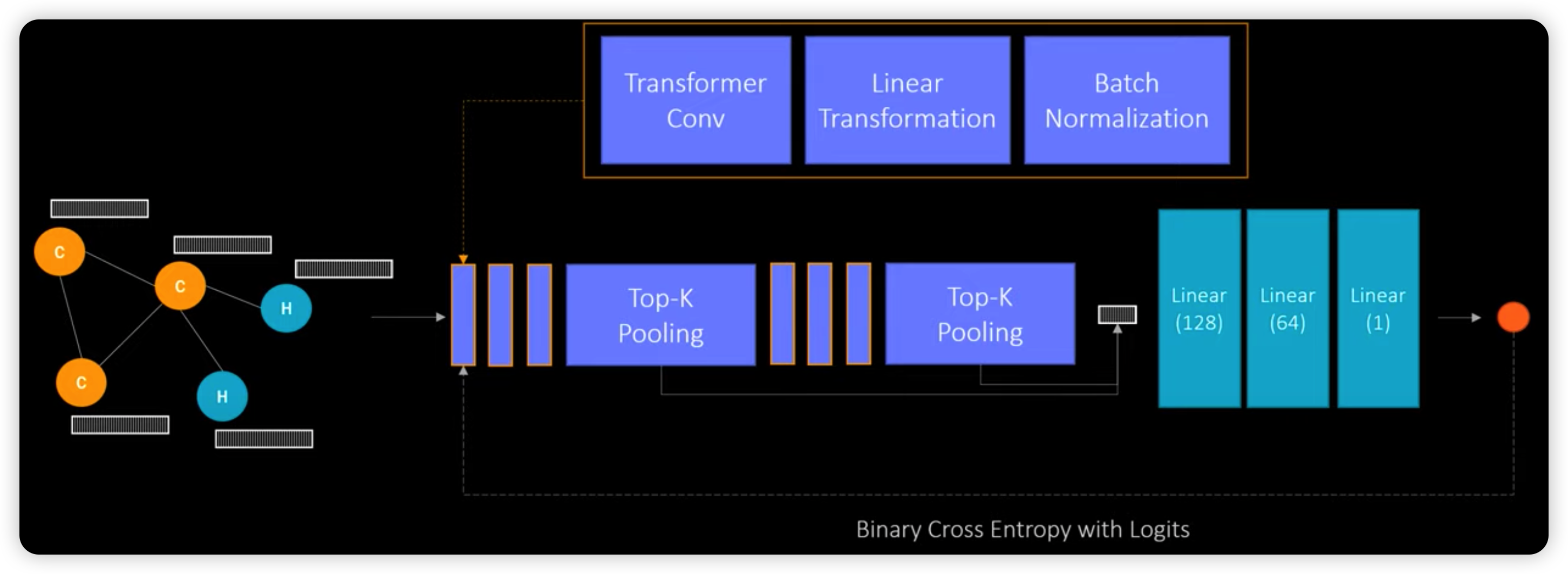
Transformer 내의 multi-head attention
from torch_geometric.nn import TransformerConv로 사용 가능

5) Code
import torch
import torch.nn.functional as F
from torch.nn import Linear, BatchNorm1d, ModuleList
from torch_geometric.nn import TransformerConv, TopKPooling
from torch_geometric.nn import global_mean_pool as gap, global_max_pool as gmp
torch.manual_seed(42)
class GNN(torch.nn.Module):
def __init__(self, feature_size, model_params):
super(GNN, self).__init__()
embedding_size = model_params["model_embedding_size"]
n_heads = model_params["model_attention_heads"]
self.n_layers = model_params["model_layers"]
dropout_rate = model_params["model_dropout_rate"]
top_k_ratio = model_params["model_top_k_ratio"]
self.top_k_every_n = model_params["model_top_k_every_n"]
dense_neurons = model_params["model_dense_neurons"]
edge_dim = model_params["model_edge_dim"]
self.conv_layers = ModuleList([])
self.transf_layers = ModuleList([])
self.pooling_layers = ModuleList([])
self.bn_layers = ModuleList([])
# Transformation layer
self.conv1 = TransformerConv(feature_size,
embedding_size,
heads=n_heads,
dropout=dropout_rate,
edge_dim=edge_dim,
beta=True)
self.transf1 = Linear(embedding_size*n_heads, embedding_size)
self.bn1 = BatchNorm1d(embedding_size)
# Other layers
for i in range(self.n_layers):
self.conv_layers.append(TransformerConv(embedding_size,
embedding_size,
heads=n_heads,
dropout=dropout_rate,
edge_dim=edge_dim,
beta=True))
self.transf_layers.append(Linear(embedding_size*n_heads, embedding_size))
self.bn_layers.append(BatchNorm1d(embedding_size))
if i % self.top_k_every_n == 0:
self.pooling_layers.append(TopKPooling(embedding_size, ratio=top_k_ratio))
# Linear layers
self.linear1 = Linear(embedding_size*2, dense_neurons)
self.linear2 = Linear(dense_neurons, int(dense_neurons/2))
self.linear3 = Linear(int(dense_neurons/2), 1)
def forward(self, x, edge_attr, edge_index, batch_index):
#------------------------------------------------------------------------#
# step 1) Node & Edge 정보 사용하여, node들의 initial representation 생성
x = self.conv1(x, edge_index, edge_attr)
x = torch.relu(self.transf1(x))
x = self.bn1(x)
#------------------------------------------------------------------------#
# step 2) Graph Representation 얻어내기
## top K pooling 사용
global_representation = []
for i in range(self.n_layers):
x = self.conv_layers[i](x, edge_index, edge_attr)
x = torch.relu(self.transf_layers[i](x))
x = self.bn_layers[i](x)
# top K & 가장 마지막 layer 추가하기
if i % self.top_k_every_n == 0 or i == self.n_layers:
x , edge_index, edge_attr, batch_index, _, _ = self.pooling_layers[int(i/self.top_k_every_n)](
x, edge_index, edge_attr, batch_index
)
global_representation.append(torch.cat([gmp(x, batch_index), gap(x, batch_index)], dim=1))
x = sum(global_representation)
#------------------------------------------------------------------------#
# step 3) Output ( scalar ) 산출
x = torch.relu(self.linear1(x))
x = F.dropout(x, p=0.8, training=self.training)
x = torch.relu(self.linear2(x))
x = F.dropout(x, p=0.8, training=self.training)
x = self.linear3(x)
return x