
StemGNN 코드 리뷰
( 논문 리뷰 : https://seunghan96.github.io/ts/gnn/ts25/ )
import torch
import torch.nn as nn
import torch.nn.functional as F
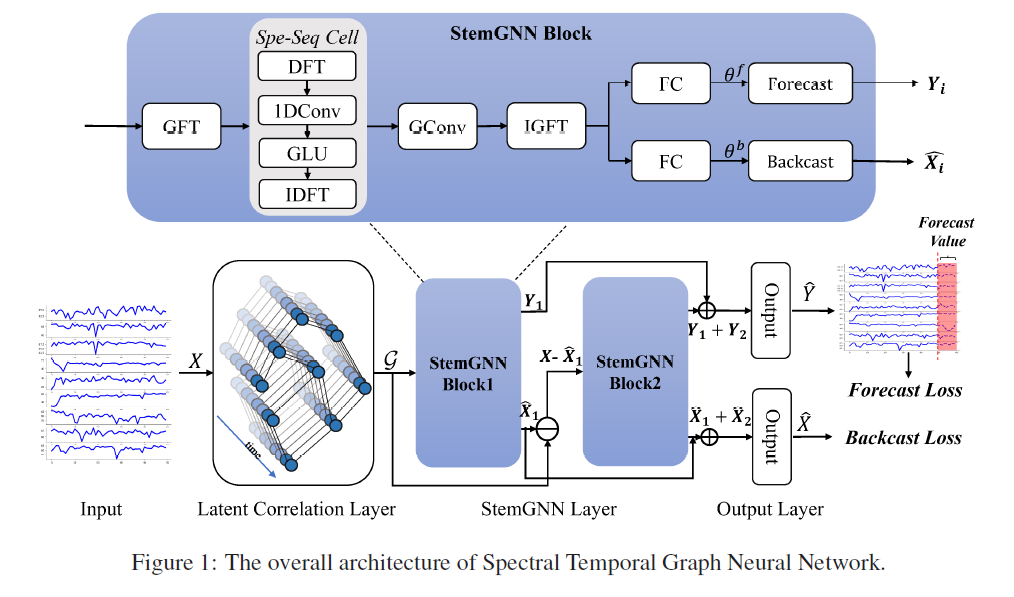
1. model.py
(1) GLU
- input : \(x\)
- output : \(FC_1(x)\) \(\times\) \(\sigma ( FC_2(x))\)
\(M^{*}\left(\hat{X}_{u}^{*}\right)=\operatorname{GLU}\left(\theta_{\tau}^{*}\left(\hat{X}_{u}^{*}\right), \theta_{\tau}^{*}\left(\hat{X}_{u}^{*}\right)\right)=\theta_{\tau}^{*}\left(\hat{X}_{u}^{*}\right) \odot \sigma^{*}\left(\theta_{\tau}^{*}\left(\hat{X}_{u}^{*}\right)\right), * \in\{r, i\}\).
class GLU(nn.Module):
def __init__(self, input_channel, output_channel):
super(GLU, self).__init__()
self.linear_left = nn.Linear(input_channel, output_channel)
self.linear_right = nn.Linear(input_channel, output_channel)
def forward(self, x):
return torch.mul(self.linear_left(x),
torch.sigmoid(self.linear_right(x)))
(2) StockBlockLayer
- input 2개 ( \(G = (X,W)\) )
- (1) x : MTS ( = \(X\) )
- (2) mul_L : x가 latent correlation layer를 거쳐서 나온 output ( = \(W\) )
spe_seq_cell- DFT and IDFT transforms time-series data between temporal domain and frequency domain,
- 1D convolution and GLU learn feature representations in the frequency domain
class StockBlockLayer(nn.Module):
def __init__(self, time_step, unit, multi_layer, stack_cnt=0):
super(StockBlockLayer, self).__init__()
self.time_step = time_step
self.unit = unit
self.stack_cnt = stack_cnt
self.multi = multi_layer
self.weight = nn.Parameter(
torch.Tensor(1, 3 + 1, 1, self.time_step * self.multi,
self.multi * self.time_step)) # [K+1, 1, in_c, out_c]
nn.init.xavier_normal_(self.weight)
self.forecast = nn.Linear(self.time_step * self.multi, self.time_step * self.multi)
self.forecast_result = nn.Linear(self.time_step * self.multi, self.time_step)
if self.stack_cnt == 0:
self.backcast = nn.Linear(self.time_step * self.multi, self.time_step)
self.backcast_short_cut = nn.Linear(self.time_step, self.time_step)
self.relu = nn.ReLU()
self.GLUs = nn.ModuleList()
self.output_channel = 4 * self.multi
for i in range(3):
if i == 0:
self.GLUs.append(GLU(self.time_step * 4, self.time_step * self.output_channel))
self.GLUs.append(GLU(self.time_step * 4, self.time_step * self.output_channel))
elif i == 1:
self.GLUs.append(GLU(self.time_step * self.output_channel, self.time_step * self.output_channel))
self.GLUs.append(GLU(self.time_step * self.output_channel, self.time_step * self.output_channel))
else:
self.GLUs.append(GLU(self.time_step * self.output_channel, self.time_step * self.output_channel))
self.GLUs.append(GLU(self.time_step * self.output_channel, self.time_step * self.output_channel))
def spe_seq_cell(self, input):
#-----------------------------------------------------------------#
# Reshape
batch_size, k, input_channel, node_cnt, time_step = input.size()
input = input.view(batch_size, -1, node_cnt, time_step)
#-----------------------------------------------------------------#
# (1) DFT ( Discrete Fourier Transform)
ffted = torch.rfft(input, 1, onesided=False)
real = ffted[..., 0].permute(0, 2, 1, 3).contiguous().reshape(batch_size, node_cnt, -1)
img = ffted[..., 1].permute(0, 2, 1, 3).contiguous().reshape(batch_size, node_cnt, -1)
#-----------------------------------------------------------------#
# (2) GLU
for i in range(3):
real = self.GLUs[i * 2](real)
img = self.GLUs[2 * i + 1](img)
real = real.reshape(batch_size, node_cnt, 4, -1).permute(0, 2, 1, 3).contiguous()
img = img.reshape(batch_size, node_cnt, 4, -1).permute(0, 2, 1, 3).contiguous()
time_step_as_inner = torch.cat([real.unsqueeze(-1), img.unsqueeze(-1)], dim=-1)
#-----------------------------------------------------------------#
# (3) iDFT ( inverse Discrete Fourier Transform)
iffted = torch.irfft(time_step_as_inner, 1, onesided=False)
return iffted
def forward(self, x, mul_L):
#------------------------------------------#
# reshape ( G = (X,W) )
x = x.unsqueeze(1) # X
mul_L = mul_L.unsqueeze(1) # W
#------------------------------------------#
# [1. GFT]
gft_out = torch.matmul(mul_L, x)
#------------------------------------------#
# [2. Spec-Seq Cell]
gconv_input = self.spe_seq_cell(gft_out).unsqueeze(2)
#------------------------------------------#
# [3. GCN & iGFT]
igft_out = torch.matmul(gconv_input, self.weight)
igft_out = torch.sum(igft_out, dim=1)
#------------------------------------------#
# [4. FORE & BACK cast]
forecast_source = torch.sigmoid(self.forecast(igft_out).squeeze(1))
forecast = self.forecast_result(forecast_source)
if self.stack_cnt == 0:
backcast_short = self.backcast_short_cut(x).squeeze(1)
backcast_source = torch.sigmoid(self.backcast(igft_out) - backcast_short)
else:
backcast_source = None
return forecast, backcast_source

class Model(nn.Module):
def __init__(self, units, stack_cnt, time_step, multi_layer, horizon=1, dropout_rate=0.5, leaky_rate=0.2,
device='cpu'):
super(Model, self).__init__()
self.unit = units
self.stack_cnt = stack_cnt
self.unit = units
self.alpha = leaky_rate
self.time_step = time_step
self.horizon = horizon
self.weight_key = nn.Parameter(torch.zeros(size=(self.unit, 1)))
nn.init.xavier_uniform_(self.weight_key.data, gain=1.414)
self.weight_query = nn.Parameter(torch.zeros(size=(self.unit, 1)))
nn.init.xavier_uniform_(self.weight_query.data, gain=1.414)
self.GRU = nn.GRU(self.time_step, self.unit)
self.multi_layer = multi_layer
self.stock_block = nn.ModuleList()
self.stock_block.extend(
[StockBlockLayer(self.time_step, self.unit, self.multi_layer, stack_cnt=i) for i in range(self.stack_cnt)])
self.fc = nn.Sequential(
nn.Linear(int(self.time_step), int(self.time_step)),
nn.LeakyReLU(),
nn.Linear(int(self.time_step), self.horizon),
)
self.leakyrelu = nn.LeakyReLU(self.alpha)
self.dropout = nn.Dropout(p=dropout_rate)
self.to(device)
def latent_correlation_layer(self, x):
#----------------------------------------------------#
# [ 1. GRU 통과 ]
# (before) x의 크기 : ( bs, node 개수, time length )
# (after) x의 크기 : ( time length, bs, node 개수 )
input, _ = self.GRU(x.permute(2, 0, 1).contiguous())
input = input.permute(1, 0, 2).contiguous()
#----------------------------------------------------#
# [ 2. self GAT 통과 ]
# ------ attention matrix를 마치 Adjacency matrix 처럼!
attention = self.self_graph_attention(input)
attention = torch.mean(attention, dim=0)
degree = torch.sum(attention, dim=1)
attention = 0.5 * (attention + attention.T)
#----------------------------------------------------#
# [ 3. (multi order) Laplacian Matrix 구하기 ]
degree_l = torch.diag(degree)
diagonal_degree_hat = torch.diag(1 / (torch.sqrt(degree) + 1e-7))
laplacian = torch.matmul(diagonal_degree_hat,
torch.matmul(degree_l - attention, diagonal_degree_hat))
mul_L = self.cheb_polynomial(laplacian)
return mul_L, attention
def cheb_polynomial(self, laplacian):
"""
Compute the Chebyshev Polynomial, according to the graph laplacian.
:param laplacian: the graph laplacian, [N, N].
:return: the multi order Chebyshev laplacian, [K, N, N].
"""
N = laplacian.size(0) # [N, N]
laplacian = laplacian.unsqueeze(0)
first_laplacian = torch.zeros([1, N, N], device=laplacian.device, dtype=torch.float)
second_laplacian = laplacian
third_laplacian = (2 * torch.matmul(laplacian, second_laplacian)) - first_laplacian
forth_laplacian = 2 * torch.matmul(laplacian, third_laplacian) - second_laplacian
multi_order_laplacian = torch.cat([first_laplacian, second_laplacian, third_laplacian, forth_laplacian], dim=0)
return multi_order_laplacian
def self_graph_attention(self, input):
input = input.permute(0, 2, 1).contiguous()
bat, N, fea = input.size()
key = torch.matmul(input, self.weight_key)
query = torch.matmul(input, self.weight_query)
data = key.repeat(1, 1, N).view(bat, N * N, 1) + query.repeat(1, N, 1)
data = data.squeeze(2)
data = data.view(bat, N, -1)
data = self.leakyrelu(data)
attention = F.softmax(data, dim=2)
attention = self.dropout(attention)
return attention
def forward(self, x):
# (1) W, Att = Latent_Correlation_Layer(X)
mul_L, attention = self.latent_correlation_layer(x)
X = x.unsqueeze(1).permute(0, 1, 3, 2).contiguous()
# (2) G=(X,W)가 2개의 StemGNN Layer에 들어감
result = []
for stack_i in range(self.stack_cnt):
# (output 1) forecast : "미래" 예측
# (output 2) X : "과거" 예측
forecast, X = self.stock_block[stack_i](X, mul_L)
result.append(forecast)
forecast = result[0] + result[1]
forecast = self.fc(forecast)
if forecast.size()[-1] == 1:
return forecast.unsqueeze(1).squeeze(-1), attention
else:
return forecast.permute(0, 2, 1).contiguous(), attention