An Inverse Scaling Law for CLIP Training (NeurIPS 2023)
Li, Xianhang, Zeyu Wang, and Cihang Xie. "An inverse scaling law for clip training." Advances in Neural Information Processing Systems 36 (2024).
( https://arxiv.org/pdf/2305.07017 )
참고: https://www.youtube.com/watch?v=iSXxz3YfMfg
Contents
- Overview
- (1) Background
- CLIP
- Scaling law for langauge models
- Token reduction strategies
- (2) Related Works: Efficient CLIP Training
- (3) Inverse Scaling Law
- (4) CLIPA: Training CLIP with Limited Resources
Overview
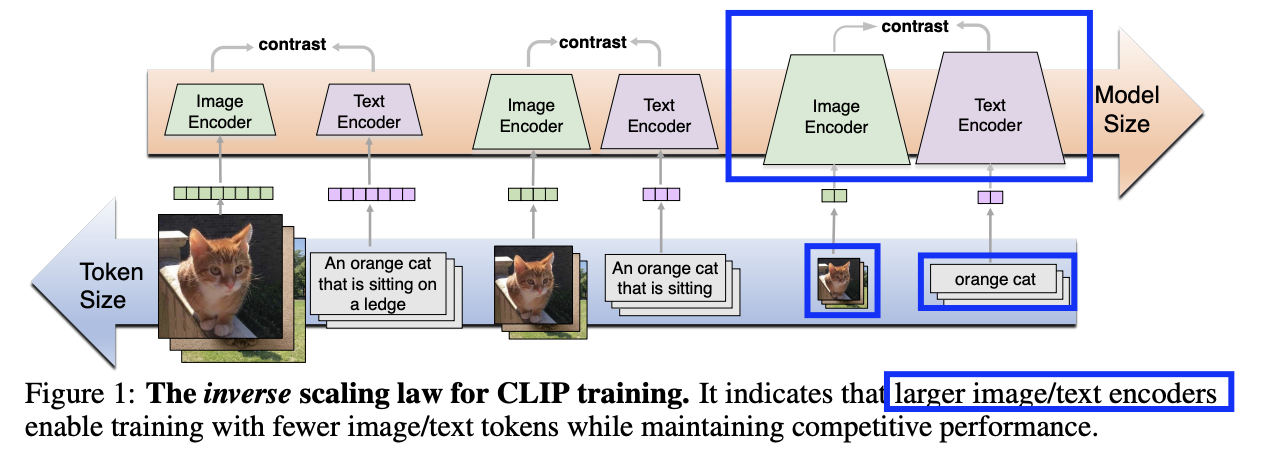
(1) Inverse Scaling Law
(Previous) Shorter (image/text) token
- 장점) 빠르고 효율적
- 단점) 정보 손실
(Proposed) Shorter (image/text) token + Larger (image/text) encoder
\(\rightarrow\) 빠르고 효율적 & 성능 향상/유지
(2) CLIPA
CLIPA = CLIP + Inverse Scaling Law
1. Background
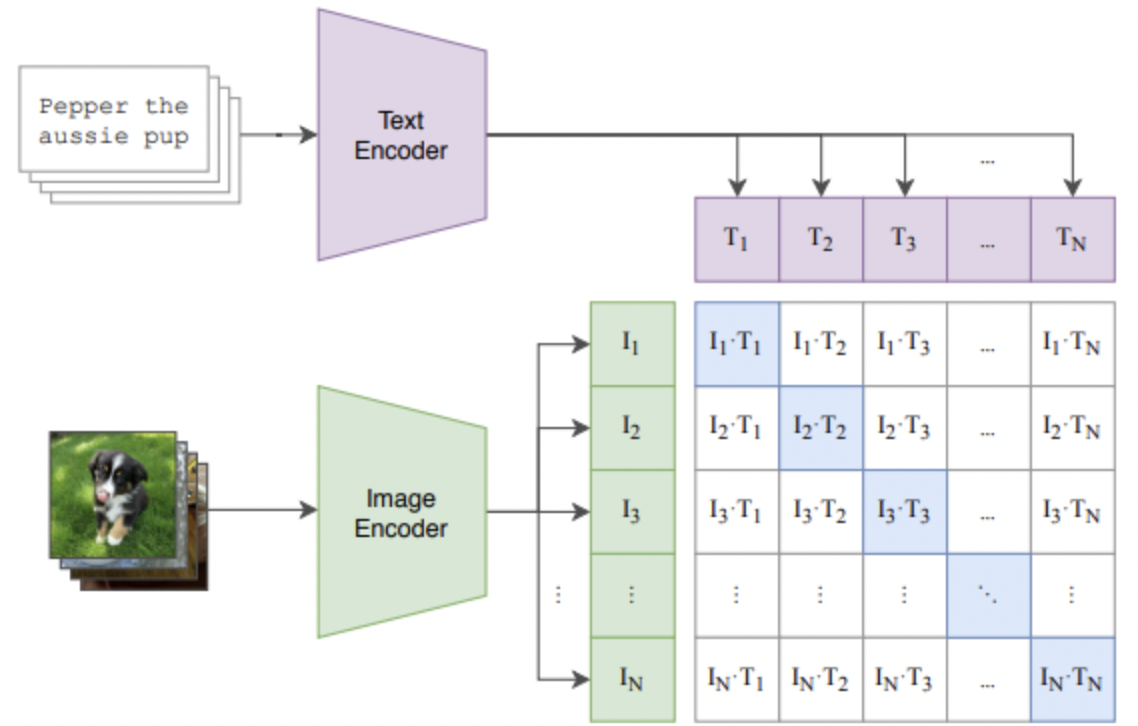
(1) CLIP
세 줄 요약
- a) 대표적인 VLM
- b) Contrastive Learning with (image, text) pair
- c) Zero-shot classification, retrieval
OpenCLIP
- CLIP을 reproduce 후 opensource로 공개
- scaling law를 발견함.
- Model / dataset 클 수록 성능 향상
(2) Scaling law for Languages models
성능 & 모델.데이터 크기와 비례
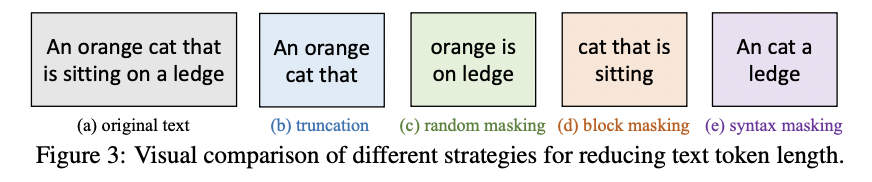
(3) Token reduction strategies


2. Related Works: Efficient CLIP Training
Motivation: Requires HIGH computational cost
Efficient CLIP Training의 세 갈래
- (1) Dataset
- (2) Sample Efficiency
- (3) Multi-GPU
(2) Sample Efficiency (e.g., FLIP, RECLIP)
-
핵심 아이디어: 데이터셋 pair에서 “필요한 만큼의” 정보만을 사용하자!
-
Examples
- FLIP: Image Masking
- RECLIP: Image Resizing
\(\rightarrow\) 속도/메모리 향상 \(\rightarrow\) Larger batch \(\rightarrow\) 성능 향상
3. Inverse Scaling Law
(Proposed) Shorter (image/text) token + Larger (image/text) encoder

Main 실험 결과 2개
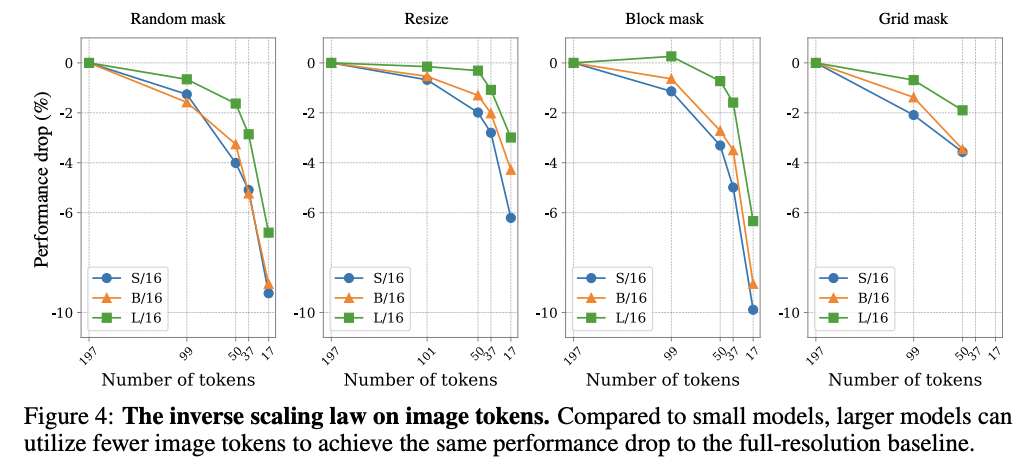
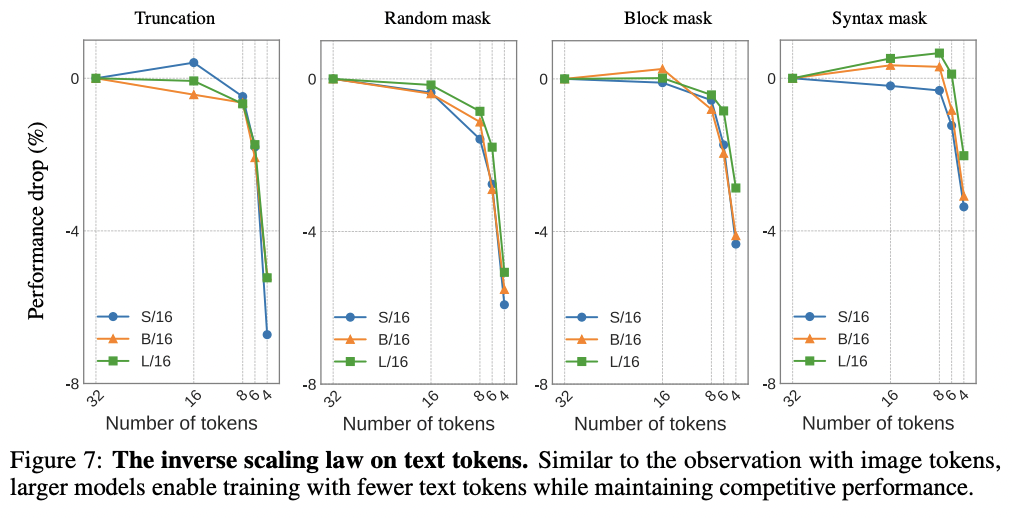
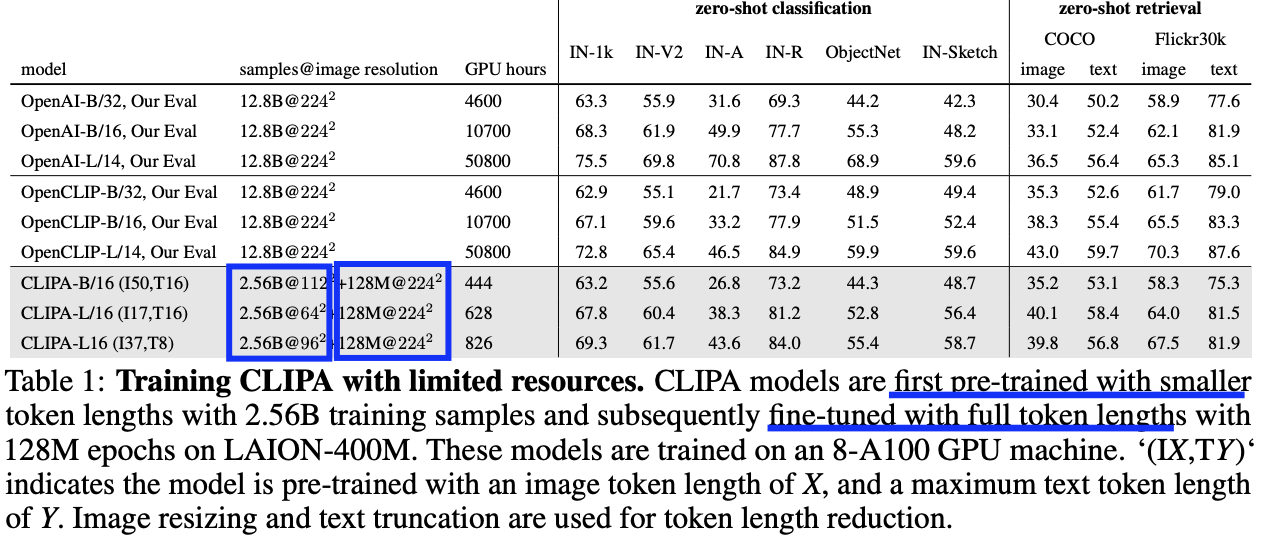
4. CLIPA: Training CLIP with Limited Resources
Inverse-scaling law를 활용해서 CLIP 모델을 학습하자!
Procedure
- Step 1) SHORTER token + LARGE encoder로 pretrain
- Step 2) FULL token으로 fine-tuning