
NV-Embed; Improved Techniques for Training LLMs as Generalist Embedding Models (arxiv 2024)
Lee, Chankyu, et al. "NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models." arXiv preprint arXiv:2405.17428 (2024).
참고: https://www.youtube.com/watch?v=nQxC8hIXer8&t=1s
( https://arxiv.org/pdf/2405.17428 )
Contents
- (1) Decoder Models
- E5-Mistral
- LLM2Vec
- (2) Concept of NV-Embed
- (3) Methods
- Bidirectional Attention
- Latent Attention Layer
- Two-stage Contrastive Instruction Tuning
1. Decoder Model
Decoder-only (e.g., GPT) (vs. Encoder-only/Bidirectional)
- Embedding 성능은 상대적으로 결여 ( due to 단방향 attention )
- LLM size가 커질 수록, curse of dimensionality
이를 해결하기 위한 decoder model들:
- a) E5-Mistral
- b) LLM2Vec
(1) E5-Mistral
(https://arxiv.org/pdf/2401.00368)
GPT4에서 생성된 “synthetic dataset”을 사용하여 성능 향상
2-step procedure
- Step 1) Task description 생성 (with LLM)
- Ex) “주식 티커가 주어지면, 해당 회사의 재무 보고서를 검색” 등
- Step 2) Task에 해당하는 (query, document) pair 생성

(2) LLM2Vec
(https://arxiv.org/abs/2404.05961)
3가지 방식 도입
- (1) Bidirectional attention
- (2) MNTP (Masked Next Token Prediction)
- (3) Unsupervsied Contrastive Learning
- ( feat. SimCSE: Simple Contrastive Learning of Sentence Embeddings )
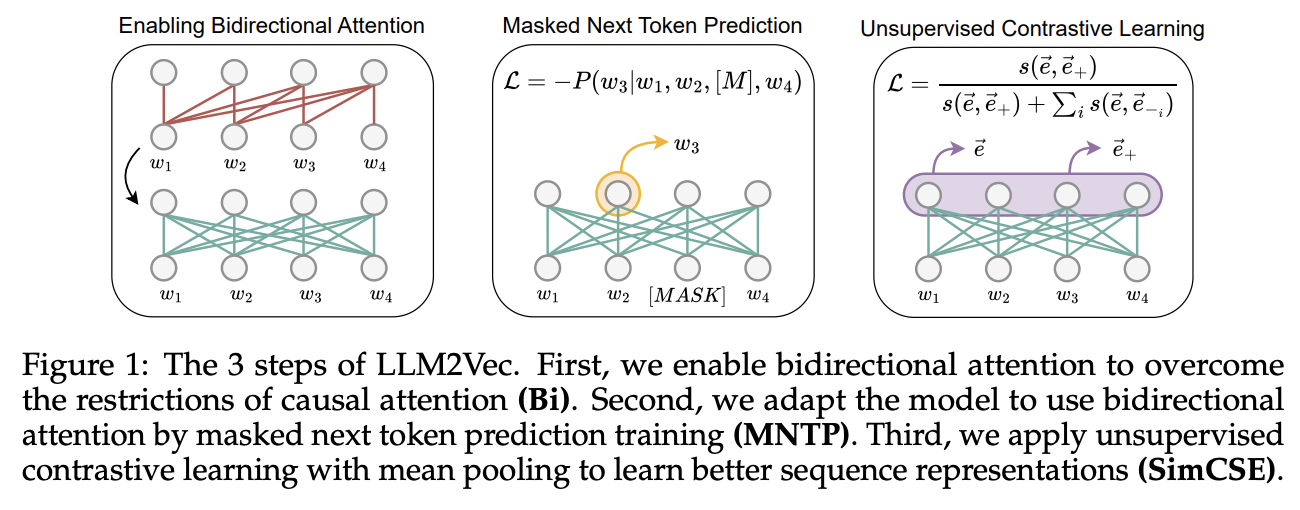
한계: 공개 데이터만 사용했으나, 성능이 상대적으로 낮음
2. Concept of NV-Embed
- 기본: Decoder-based LLM을 향상시키자!
- 모델 구조
- a) Latent attention layer
- b) Bidirectional attention layer
- Two-stage constrative instruction tuning
- Stage 1) Retrieval dataset 활용
- e.g., in-batch negatives, hard negatives
- Stage 2) Non-retrieval dataset과 혼합 학습
- e.g., 분류, 클러스터링, STS
- Stage 1) Retrieval dataset 활용
3. Method
(1) Bidirectional Attention
causal attention mask을 제거한다
(2) Latent Attention Layer
Bidirectional Attention을 통과해서 나온 벡터에 적용을 하는 layer
Sequence embedding을 얻기 위해, 기존 방법론과의 차이점?
- (기존) Mean pooling, <EOS> token 등
- Mean-pooling: 평균으로 인한 정보 희석 가능성
- <EOS> token: 마지막 토큰에 bias가 낄수도
- (제안) latent attention layer
- Q,K,V는?
- (Q) Decoder의 마지막 출력
- (K, V) learnable array
- 이후에, MLP를 통해 변환한 뒤 Mean pooling하여 최종 임메딩 생성
- Q,K,V는?
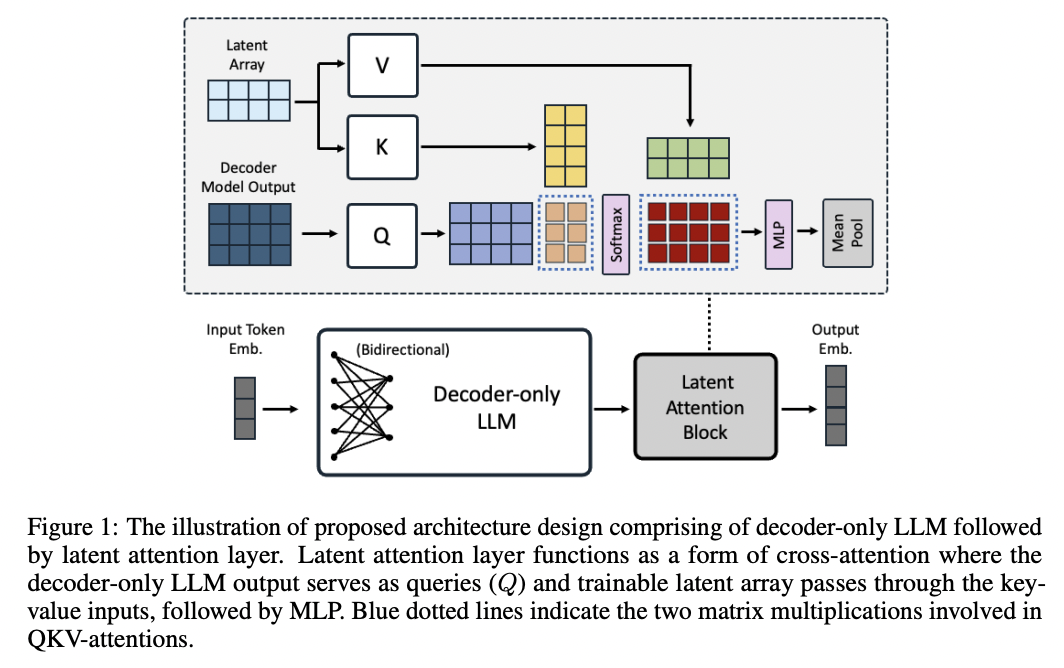
(3) Two-stage Contrastive Instruction Tuning
Retrieval & non-retrieval 작업을 모두 잘 수행하기 위해서, 각 task의 특징을 잘 파악해야!
\(\rightarrow\) 단순히 batch 내의 다른 sample을 negative로 취급하는 것은 non-retrieval에 위험!
Procedures
Stage 1) Contrastive Learning (CL)
-
Retrieval dataset 활용
( = in-batch negatives & hard negatives 사용 )
Stage 2) Non-retrieval dataset 통합
-
non-retrieval dataset 추가
( e.g., 분류, clustering, 의미적 유사도 (STS) )
-
in-batch negative 비활성화
Training Data = Retrieval + Non-retrieval
Retrieval dataset
-
(합성 데이터셋 X) 공개 데이터셋만을 사용함
-
CL을 위해, 모든 데이터셋을 instruction template로 통일

- Hard negative sampling 방법
- SimLM 논문 참고: E5학습 방법 (encoder-based embedding model)
Non-retrieval dataset
- 생략. 논문 참조