
Vision-Language Models (VLMs)
참고: https://encord.com/blog/vision-language-models-guide/
Contents
- Overview
- (1) VLM architectures
- (2) VLM evaluation strategies
- (3) VLM mainstream datasets
- (4) Key challenges, primary applications, and future trends
Overview
Vision-language model (VLM)
- Input: Images & Respective textual descriptions
- Goal: Learns to associate the knowledge from the two modalities
- Vision model: Captures spatial features from the images
- Language model: Encodes information from the text
\(\rightarrow\) Learns to understand images and transforms the knowledge into text (and vice versa)
Training VLMS
- (1) Pre-training foundation models
- Contrastive Learning
- Masked language-image modeling
- (2) Zero-shot learning & Transfer Learning (w/ fine-tuning)
1. VLM Architectures
Mainstream models: CLIP, Flamingo, and VisualBert
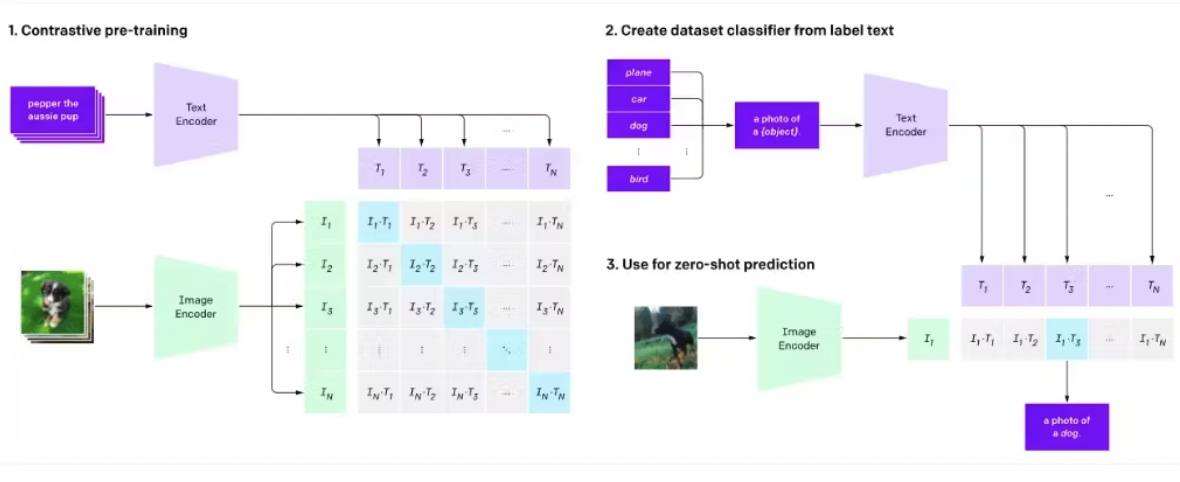
(1) CLIP
Contrastive learning in CLIP
- Similarity between text and image embeddings
3 Step process (to enable zero-shot predictions)
- Step 1) Pretrain
- Train a text & image encoder
- Step 2) Converts training dataset classes into captions
- Step 3) Zero-shot prediction
- Estimates the best caption for the given input image
ALIGN : Also uses image and textual encoders to minimize the distance between similar embeddings with contrastive learning
(2) SimVLM & VirTex & Frozen
PrefixLM
NLP learning technique for model pre-training
- Input: Part of the text (= prefix)
- Goal: Predict the next word in the sequence
PrefixLM in VLMs
Enables the model to predict the next sequence of words based on …
\(\rightarrow\) an image & its respective prefix text
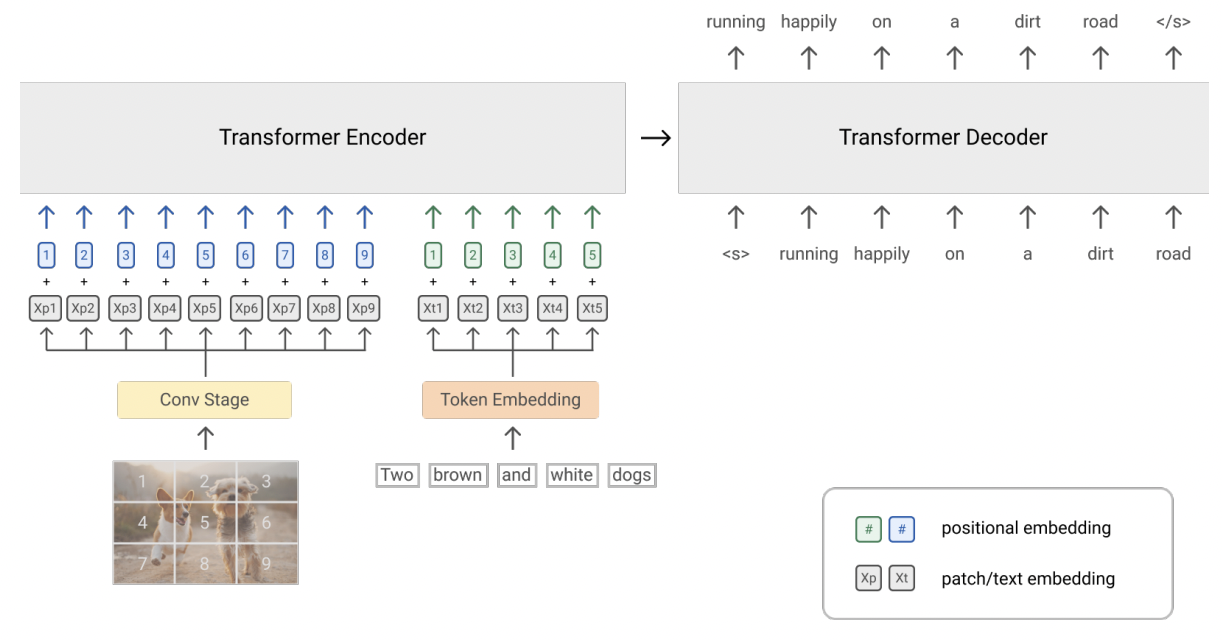
Model: Vision Transformer (ViT)
-
(1) Vision part
-
Divides an image into a 1d-patch sequence
-
Applies convolution or linear projection over the processed patches
\(\rightarrow\) Generate contextualized visual embeddings
-
- (2) Text part
- Converts the text prefix relative to the patch into a token embedding
- Transformer’s encoder-decoder blocks receive both “visual” and “token” embeddings
a) SimVLM
- Popular architecture utilizing the PrefixLM
- Simple Transformer architecture
- Encoder: to learn image-prefix pairs
- Decoder: to generate an output sequence
- Good generalization and zero-shot learning capabilities
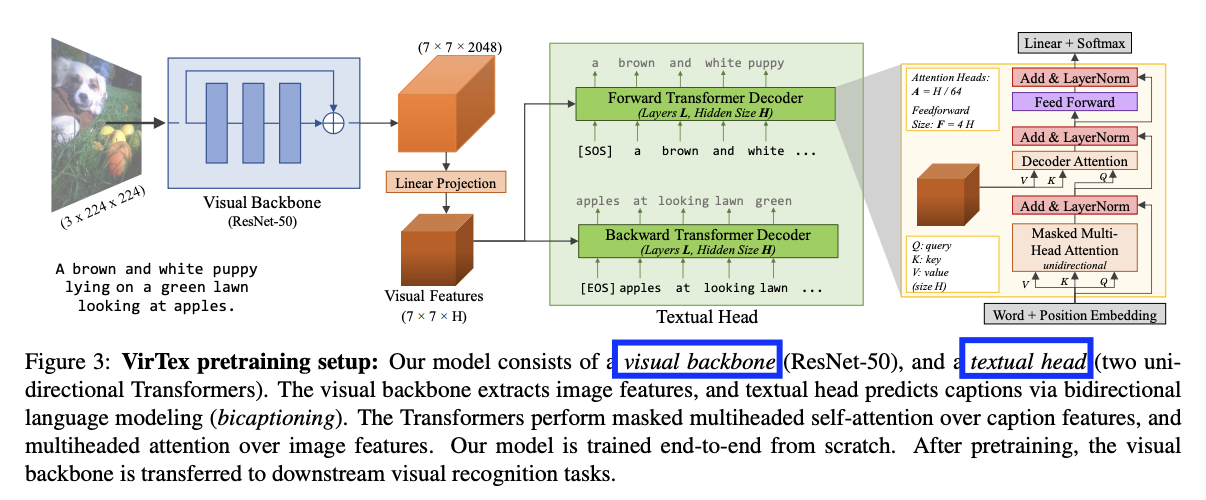
b) VirTex
-
(1) Image: **CNN **
-
(2) Text: Textual head with transformers
-
Train the model end-to-end to predict the image captions
( by feeding image-text pairs to the textual head )
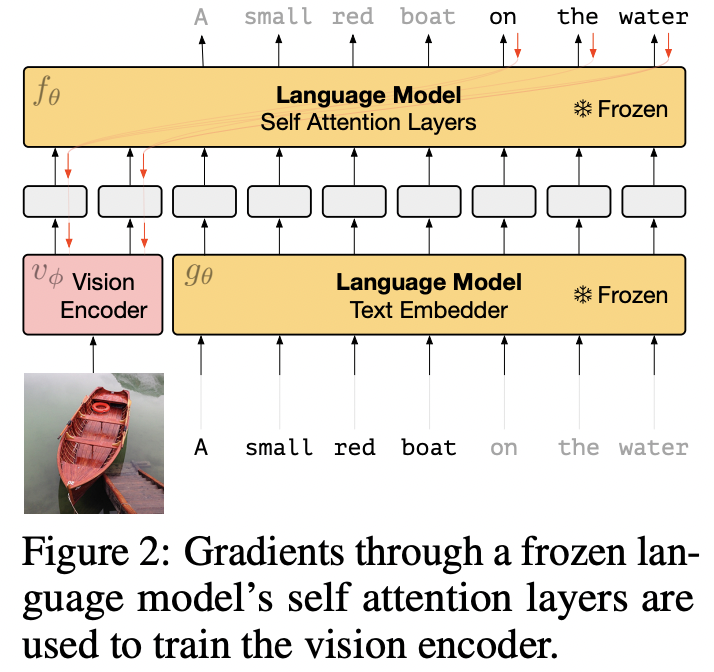
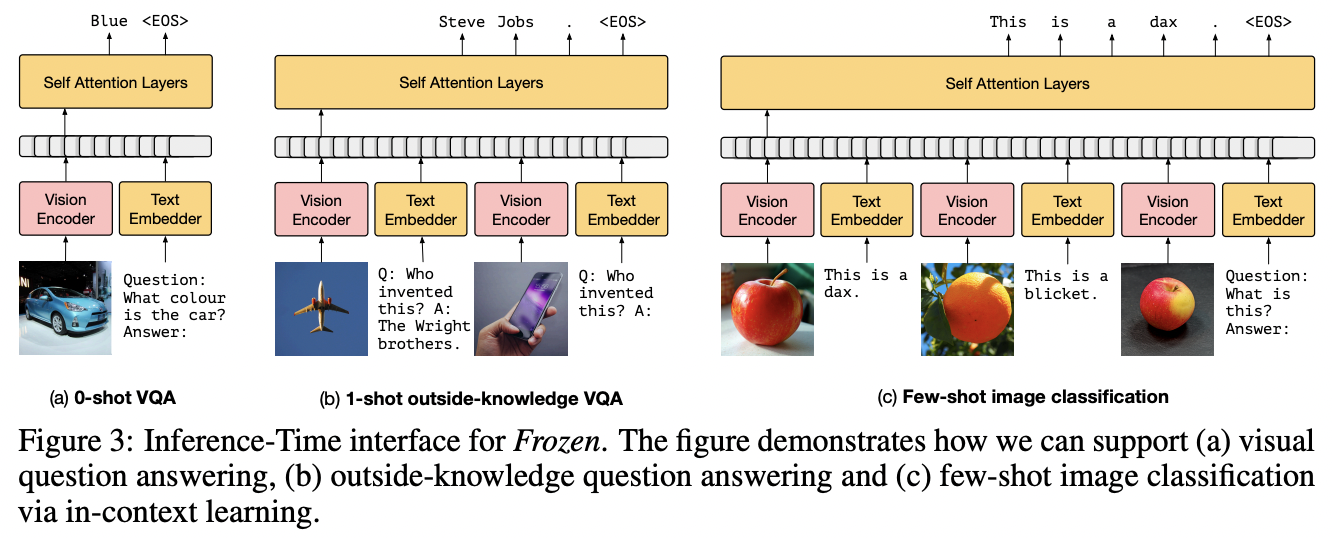
c) Frozen
- PrefixLM vs. Frozen PrefixLM
-
(1) PrefixLM : Train visual and textual encoders from scratch
-
(2) Frozen PrefixLM : Use pre-trained networks
- Only update the parameters of the image encoders
-
- Encoders
- Text encoder: Any LLMs
- Visual encoder: Any pre-trained visual foundation model
(3) Flamingo
Architecture
- Text model: **Chinchilla **
- Freeze the LLM
- Vision model: CLIP-like vision encoder
- Process the image through a Perceiver Sampler
- Results in faster inference & ideal for few-shot learning
- Process the image through a Perceiver Sampler
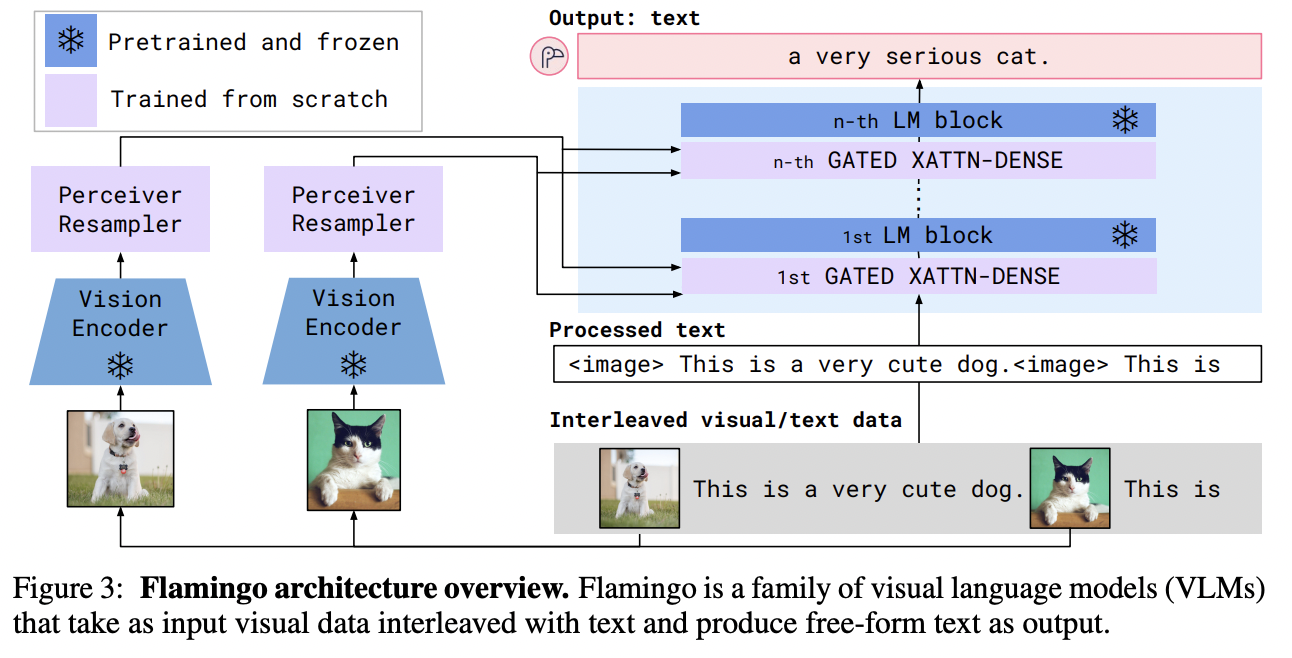
(4) Multimodal Fusing with Cross-Attention
Pre-trained LLM for visual representation learning
\(\rightarrow\) By adding cross-attention layers
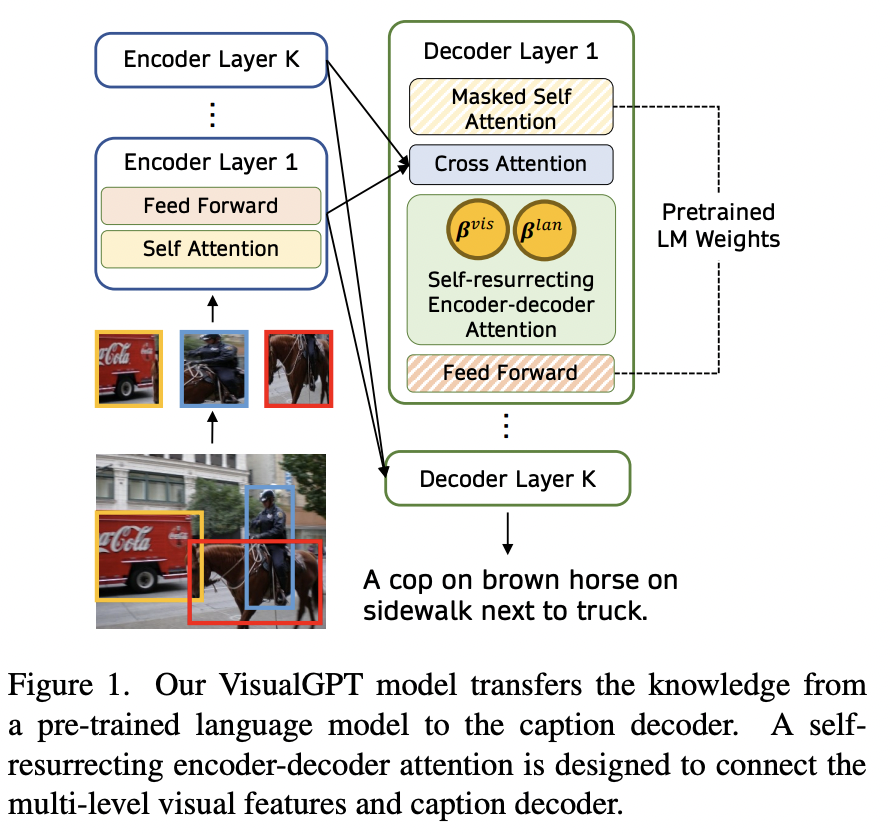
VisualGPT
-
Key: Adaptation of an LLM’s pre-trained encoder for visual tasks
-
How: Employs a novel self-resurrecting encoder-decoder attention mechanism
- To quickly adapt the LLM with a small amount of in-domain image-text data
-
Self-resurrecting activation unit: produces sparse activations
\(\rightarrow\) Prevent accidental overwriting of linguistic knowledge
( avoids the issue of vanishing gradients )
Procedure
-
Step 1) Extract relevant objects from an image input
-
Step 2) Feed them to a visual encoder
\(\rightarrow\) Obtain visual representations
-
Step 3) Feed the representations to a decoder
-
Decoder: Initialized with weights according to pre-trained LLM
-
Self-resurrecting activation unit (SRAU)
\(\rightarrow\) Balances the visual and textual information
-
(5) Masked-Language Modeling (MLM) & Image-Text Matching (ITM)
Adapt the MLM and ITM techniques for visual tasks!
VisualBERT
(Trained on the COCO dataset)
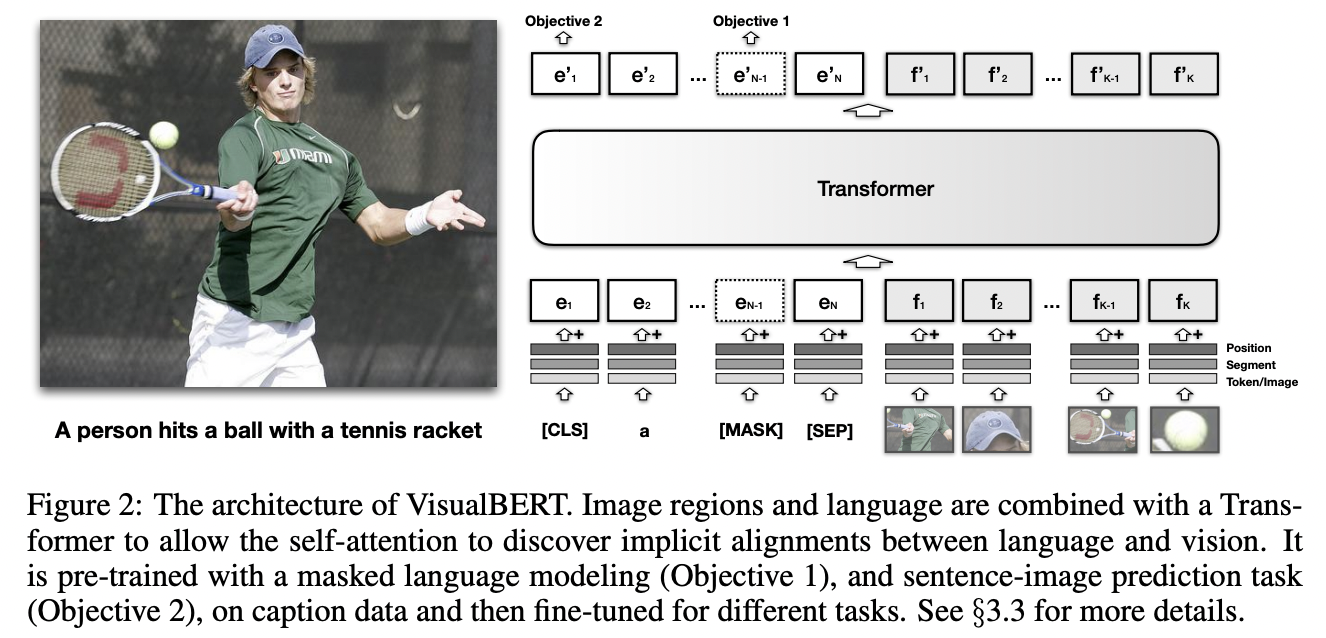
- A simple and flexible framework for modeling vision-and-language tasks
- Stack of Transformer layers: Implicitly align elements of …
- (1) An input text
- (2) Regions in an associated input image
- Propose two visually-grounded language model objectives for pre-training: MLM & ITM
- ITM: Whether or not a caption matches the image
(6) No Training
Directly use large-scale, pre-trained VLMs without any fine-tuning
MAGIC
- “Specialized score” based on CLIP-generated image embeddings to guide LLMs’ output
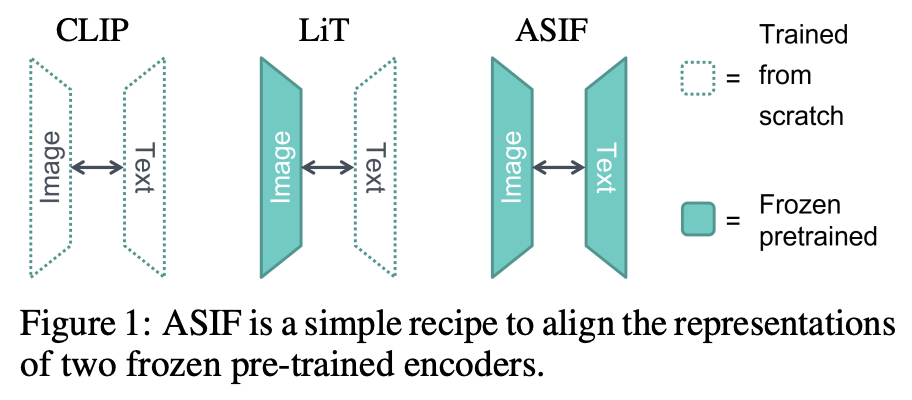
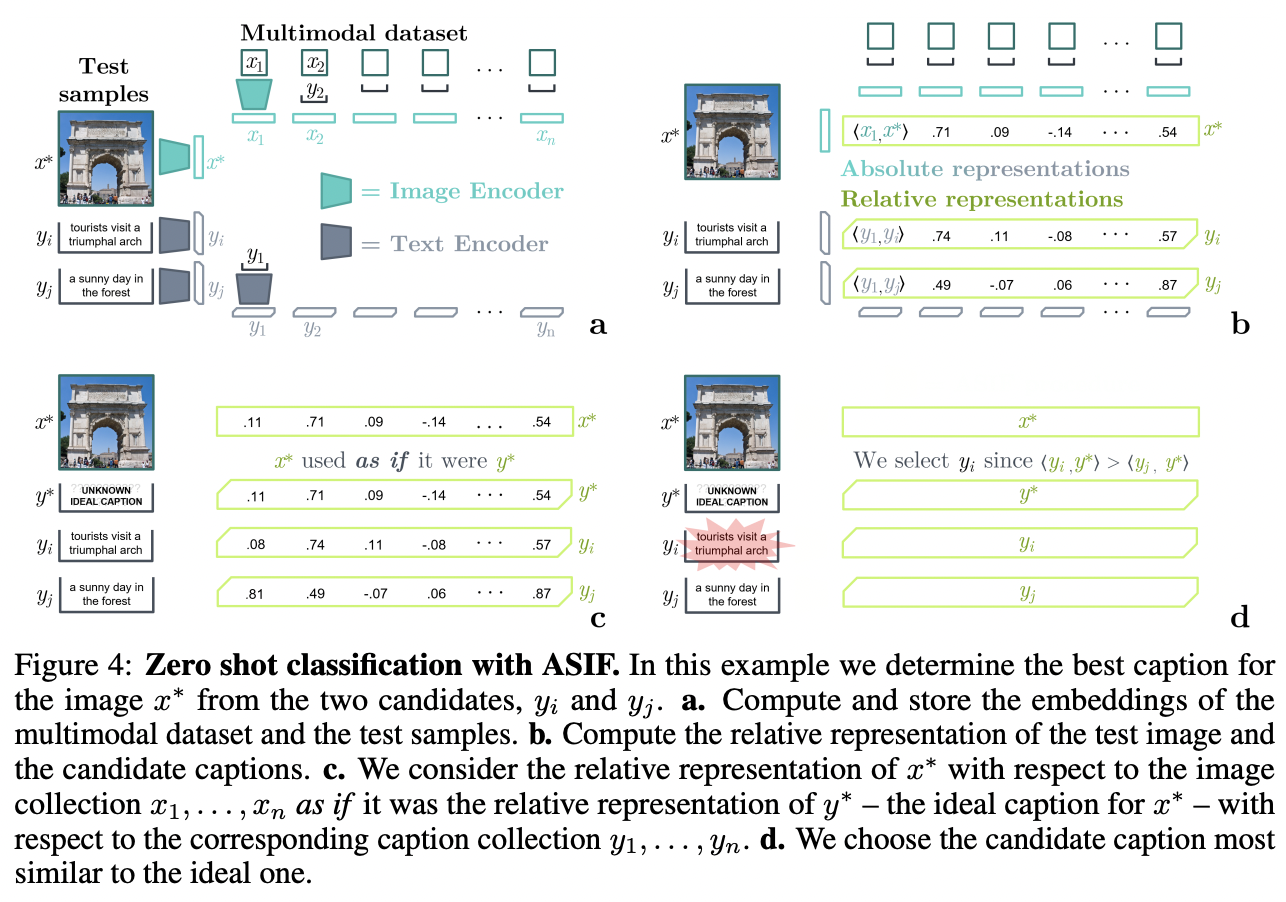
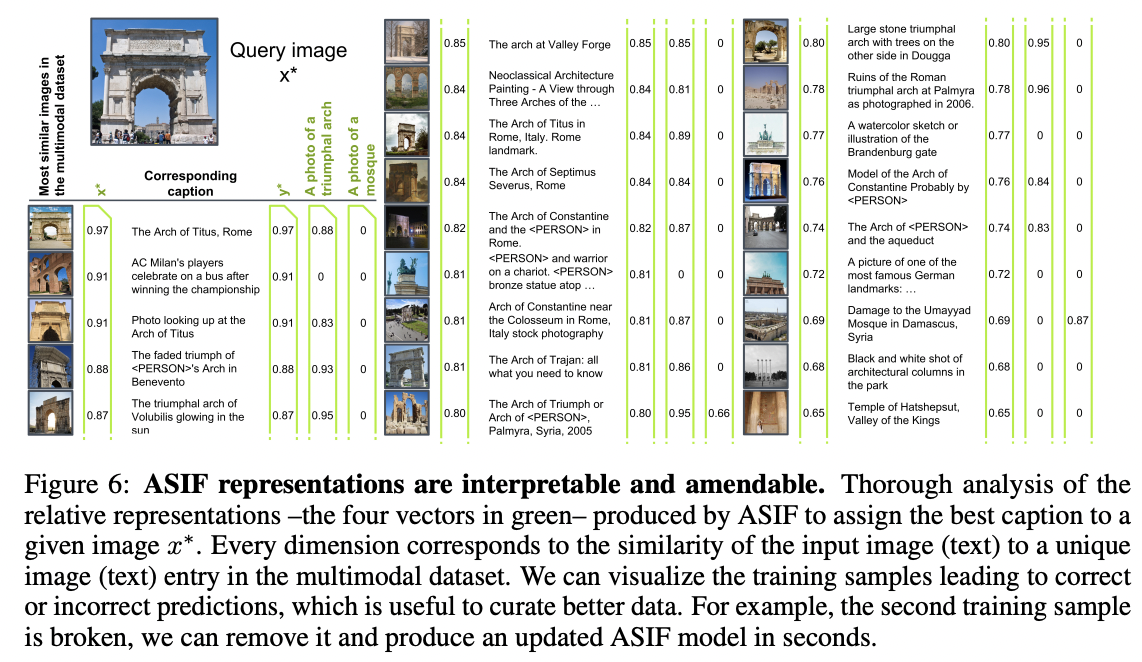
ASIF
- Key idea: similar images have similar captions
- Step 1) Computes the similarities between the …
- Single Image) training dataset’s query
- Multiple Images) candidate images
- Step 2) Compares the …
- Single Image) Query image embedding
- Multiple Texts) Text embeddings of the corresponding candidate images
- Step 3) Predicts a description whose embeddings are the most similar to those of the query image
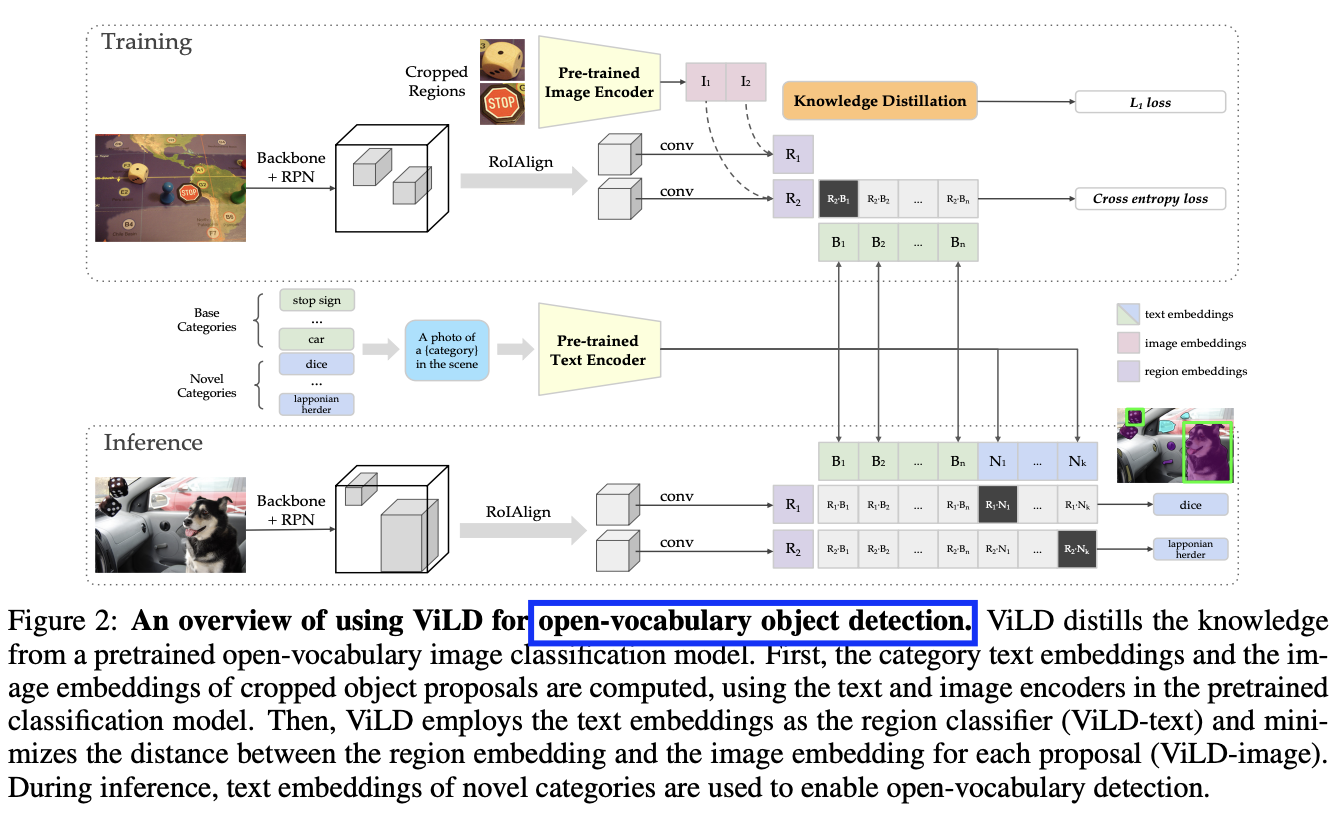
(7) Knowledge Distillation
Train VLMs from larger, pre-trained models.
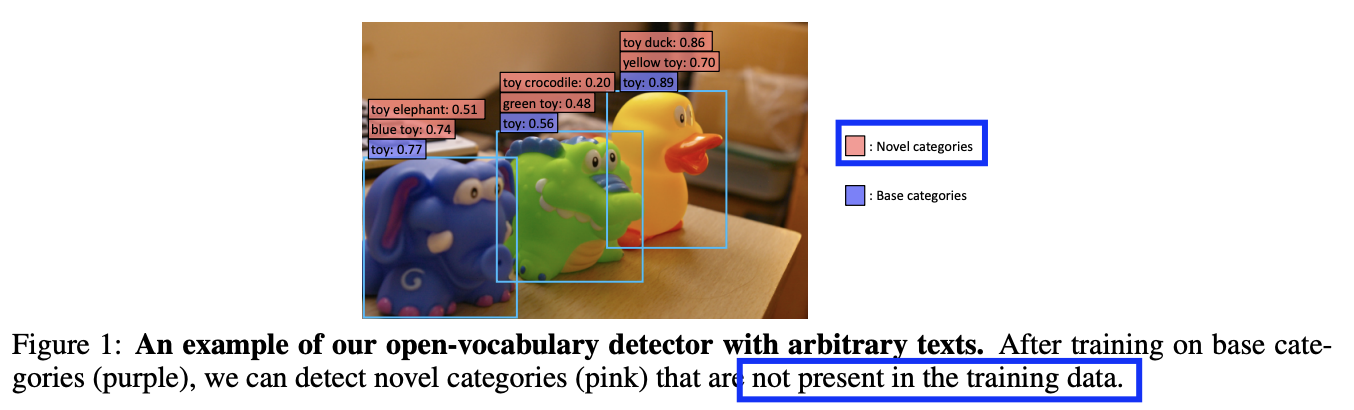
ViLD
- Teacher: Pre-trained open-vocabulary image classification model
- Student: Two-stage detector
\(\rightarrow\) Matches textual embeddings from a textual encoder with image embeddings
2. Evaluating VLMs
Assess the quality of the relationships between the image and text
Example) Image captioning model
- Comparing the generated captions to the [ground-truth](https://encord.com/glossar
Various automated n-gram-based **evaluation strategies to compare the **predicted labels
- in terms of accuracy, semantics, and information precision.
Examples:
-
BLEU (Bilingual Evaluation Understudy)
-
Originally proposed to evaluate machine translation tasks
-
How? “Precision” of the target text vs. reference (ground truth)
by considering how many words in the **candidate sentence ** appear in the reference.
-
-
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
- How? “Recall” by considering how many words in the **reference sentence ** appear in the candidate.
-
METEOR (Metric for Evaluation of Translation with Explicit Ordering)
- How? “Harmonic mean” of precision and recall
- More weight to recall and multiplying it with a penalty term
- How? “Harmonic mean” of precision and recall
-
CIDEr (Consensus-based Image Description Evaluation)
- How? “TF-IDF scores”: compares a target sentence to a set of human sentences by computing the average similarity between reference and target sentences