
DALL-E; Zero-Shot Text-to-Image Generation
Ramesh, Aditya, et al. "Zero-shot text-to-image generation." International conference on machine learning. Pmlr, 2021.
참고: https://www.youtube.com/watch?v=-e-vW1j132A&t=2257s
Contents
- Introduction
- DALL-E
- Visualization
1. Introduction
- GPT-3의 확장형태 (Auto-regressive), 12B params.
- CV + NLP \(\rightarrow\) Text-to-Image task
- Zero-shot performance
2. DALL-E
Text & Image token을 “single stream”으로 모델링
Issues
- (1) Memory issue (pixel-level)
- (2) Short-range dependence
(1) Stage 1
Image token 생성
- (1) Discrete VAE 사용
-
(2) (256x256) \(\rightarrow\) (32,32) image token으로 압축
- (3) (codebook 내의) # Token = 8192
- (4) context size 192배 줄임
- (256x256x3) \(\rightarrow\) (32x32)
픽셀을 순차적으로 생성하는 것보다 효율적!
- 나름, (디테일은 사라질지라도) 핵심 요소들은 잘 유지가 됨!

(2) Stage 2
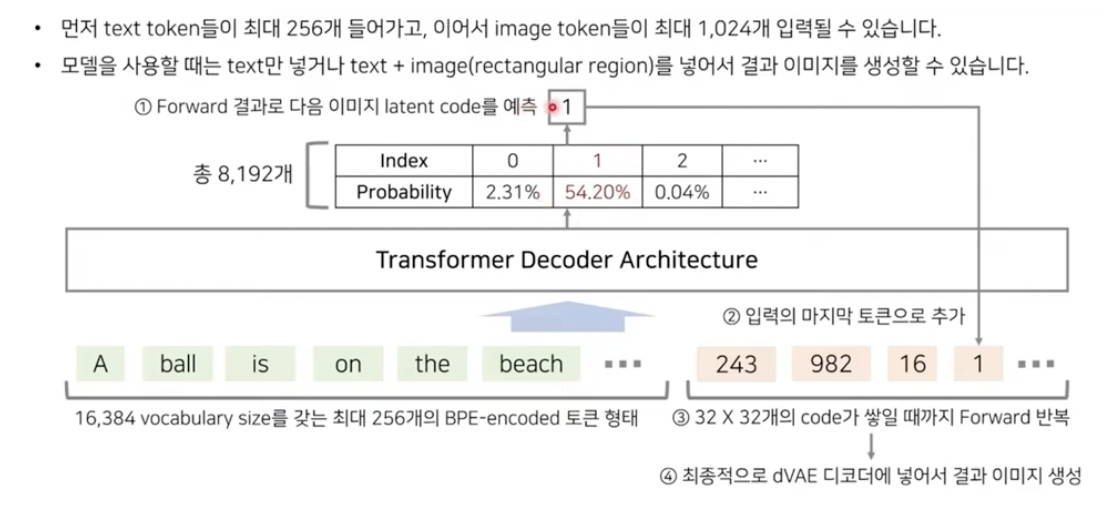
Text token & Image token 합치기
Concatenate (a) & (b)
- (a) (최대) 256 BPE-encoded text token
- (b) (32x32) image token
\(\rightarrow\) Text & Image token의 joint distribution을 학습한다
아래의 과정을 1024개의 image token이 다 채워질때까지 autoregressive하게 반복한다!
(3) Interpretation
\(p_{\theta, \psi}(x, y, z)=p_\theta(x \mid y, z) p_{\varphi}(y, z)\).
- (1) \(p_{\varphi}(y, z)\): Transformer
- (2) \(p_\theta(x \mid y, z)\): Discrete VAE decoder
- Notation
- \(x\): image
- \(y\): text ( = caption )
- \(z\): image의 token
Maximizing ELBO
\(\ln p_{\theta, v}(x, y) \underset{z \sim q_\phi(z \mid x)}{\mathbb{E}}\left(\ln p_\theta(x \mid y, z)-\beta D_{\mathrm{KL}}\left(q_\phi(y, z \mid x), p_\psi(y, z)\right)\right)\).
- \(p_{\theta}\): dVAE decoder ( image token으로 image 예측)
- \(q_{\phi}\): dVAE encoder ( image로 image token 예측)
- \(p_{\varphi}\): Transformer ( image token & text token의 joint distn 모델링 )
(4) Details
Stage 1. Learning the visual code book
- dVAE encoder & decoder 학습
- 즉, \(\theta, \phi\)에 대해 ELBO를 maximize
- 오직 image와 관련된 부분 (text (X))
Stage 2. Learning prior
- Transformer 학습
- 즉, (\(\theta, \phi\)는 고정해둔 채) \(\varphi\)에 대해 ELBO를 maximize
- Text token & Image token에 대한 prior를 학습함
Transformer: decoder-only model
- (1) Text-to-text ATT: standard causal mask
- (2) Image-to-Image ATT: row/col/convolutional attention mask

3. Visualization
