
Byte Latent Transformer: Patches Scale Better Than Tokens (FAIR 2024)
Pagnoni, Artidoro, et al. "Byte Latent Transformer: Patches Scale Better Than Tokens." arXiv preprint arXiv:2412.09871 (2024).
( https://arxiv.org/pdf/2412.09871 )
참고: https://www.youtube.com/watch?v=jjwkjYEbejk
Contents
1. Abstract
Byte Latent Transformer (BLT)
-
Byte-level LLM architecture
-
Performance: Matches tokenization-based LLM performance at scale
( with significant improvements in inference efficiency and robustness )
-
-
Details
-
Encodes bytes into dynamically sized patches
( = primary units of computation )
-
Patches are segmented based on the entropy of the next byte
-
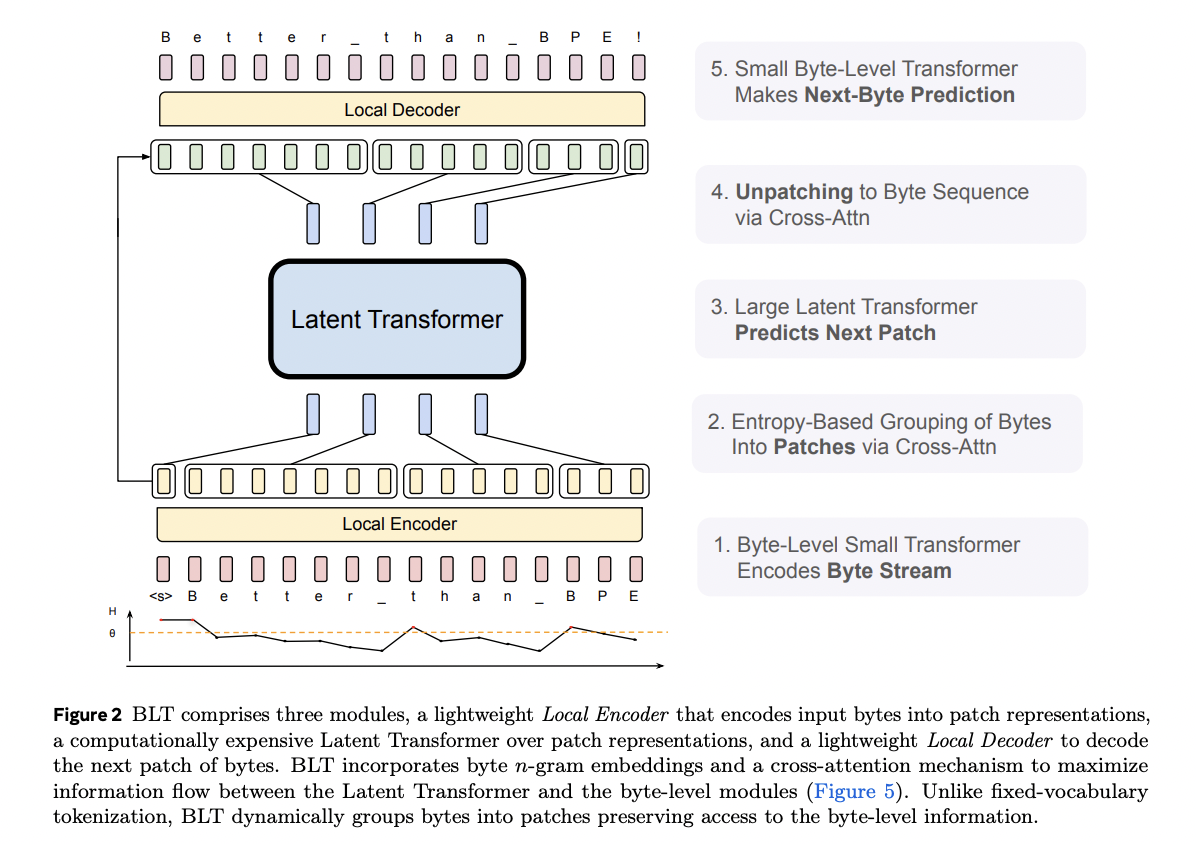
2. Overall Architecture
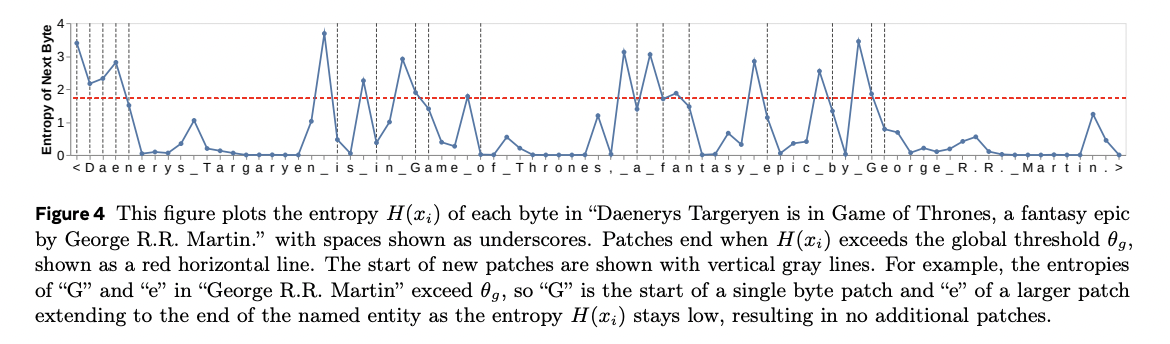
3. Various patching techniques

Entropy Patching
Using Next-byte entropies from a small byte LM
\(\rightarrow\) 새로운 patch의 시작점이 되는 경계: Entropy 기반으로 결정한다!
4. Byte Latent Transformer (BLT)
핵심: Byte & Patch 단위를 모두 사용!
- Local: Byte
- Global: Patch ( = Byte의 묶음 )
요약:
- (1) Byte단위로 Language Modeling
- (2) Encoder에서 진행되는 무거운 연산은, 묶어서 Patch 단위로써 진행!
\(\rightarrow\) Consists of Global & Local Model
(1) [Local] Local Encoder & Decoder
Byte단위의 입/출력을 받음/뱉음
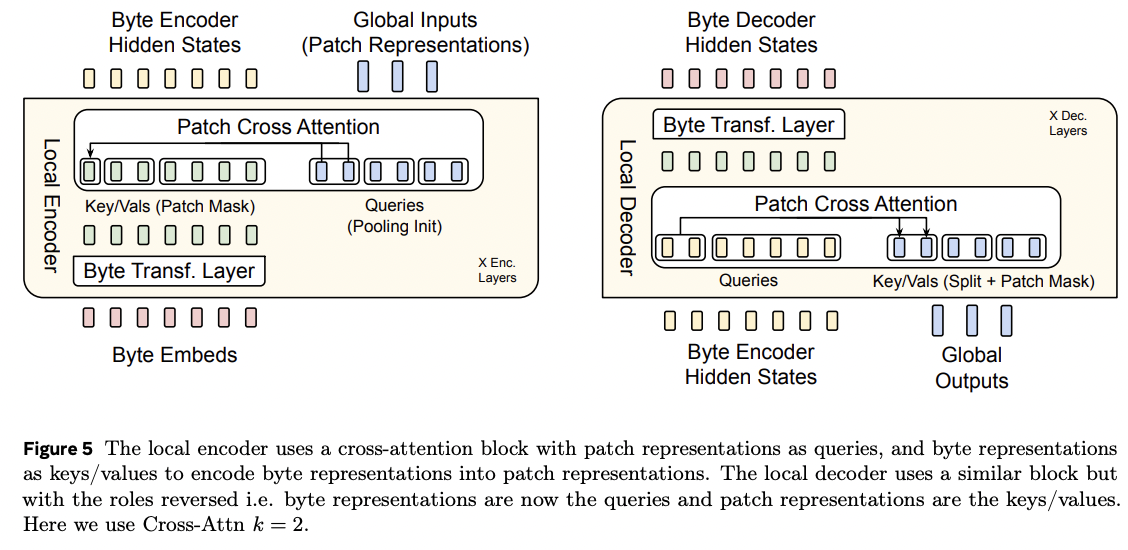
Encoder & Decoder
- Encoder:
- Query: patch
- Key/Values: byte
- Decoder:
- Query: byte
- Key/Values: patch
Encoder hash n-gram Embeddings
\(e_i=x_i+\sum_{n=3, s_8} E_n^{\text {hash }}\left(\operatorname{Hash}\left(g_{i, n}\right)\right)\).
해석: \(i\) 번재 byte의 최종 임베딩 = (1) + (2)
- (1) i번째 byte의 unigram embedding
- (2) i번쨰 byte까지의 n-gram embedding의 합
(2) [Global] Latent Global Transformer
내재적인 Next Patch prediction
여기서 Transformer 모델에서 representation이 잘 생성되어야, Local decoder가 잘 예측할 수 있을 것임!
기타: Entropy Model
entropy가 높은 Token \(\rightarrow\) 새로운 patch의 경계