
Introduction to sLM
Contents
- sLLM이란
- sLLM vs. LLM
- sLLM 예시
- LLaMA 3 (Meta)
- Gemma (Google)
- Phi-3 (Microsoft)
- Mixtral 8x7B (Mistral AI)
- 기타
1. sLLM이란
sLLM = “small” LLM
- # params: 수십억 ~ 수백억
- LLM에 비해 적은 리소스로 훈련 가능 + 그에 못지 않은 성능
- 범용으로 활용 보다는, “특정 요구사항을 충족”하는데에 focus
장점
- (1) Hardware 부담 감소
- (2) 높은 비용 효율성
활용 사례:
- (스캐터랩) Pingpoing-1, (삼성전자) Code.ISR, (네이버) HCX-대시, (업스테이지) 솔라 미니 …
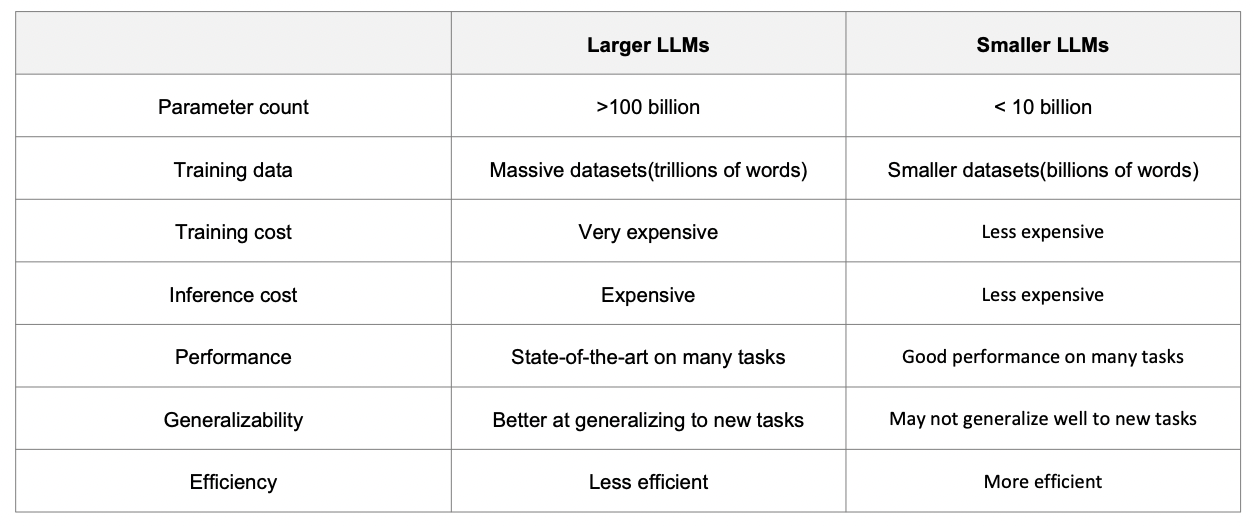
2. sLLM vs. LLM
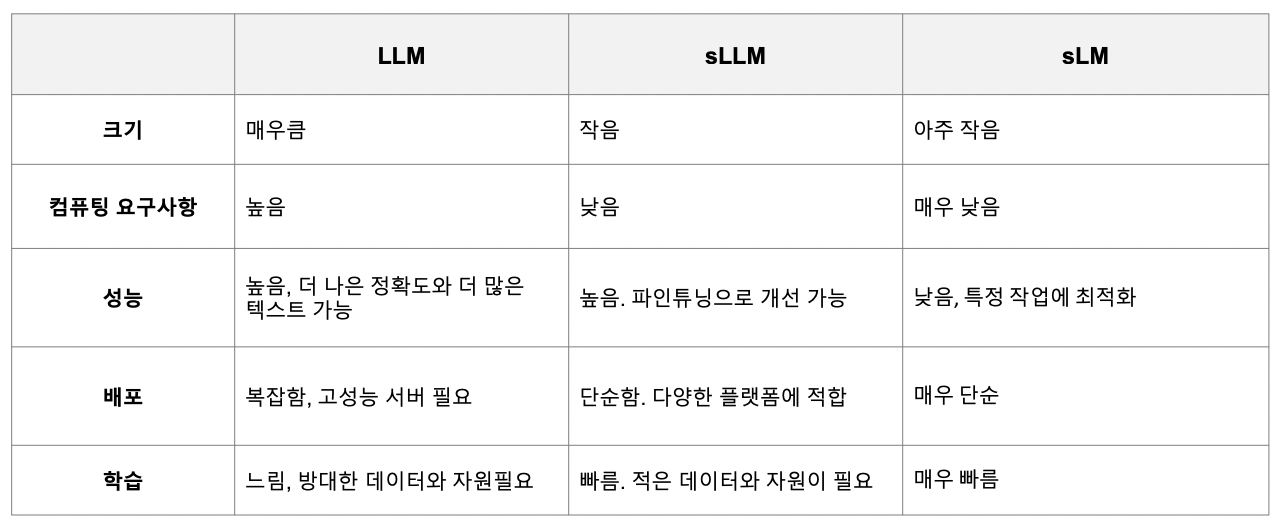
3. sLLM 예시
개요
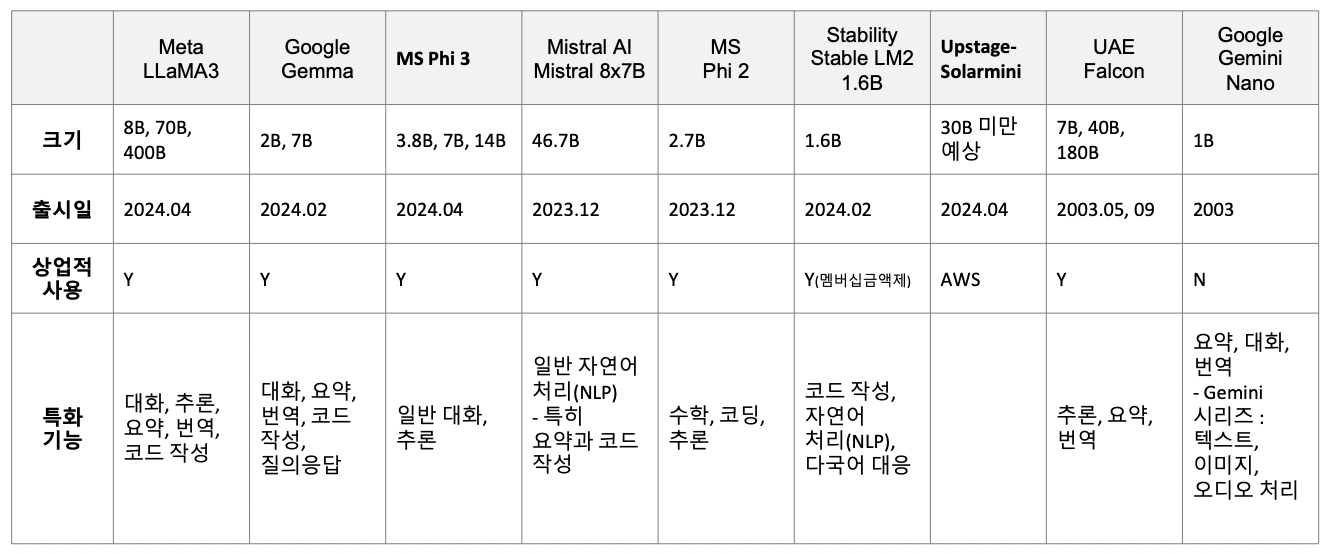
(1) LLaMA 3 (Meta)
a) 기본 정보
- LLaMA: Meta에서 출시한 open-source LLM
- Versions: # params
- LLaMA 1 (2023.02): 7B, 65B
- LLaMA 2 (2023.07): 7B, 700B
- LLaMA 3 (2024.04): 8B, 700B
- # tokens: 1.4조개
- Facebook, Instragram, Web, LaTeX …
- Input & Output
- Input: Text
- Output: Text & Code
- Tuning: SFT + RLHF
b) 자체 성능 비교
[w/o instruction tuning]
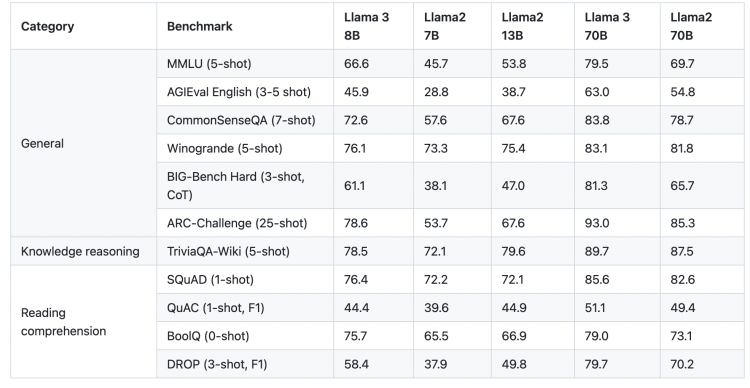
[w/ instruction tuning]
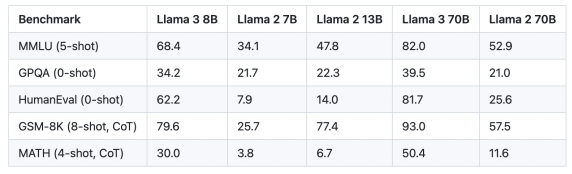
c) 다른 모델과의 성능 비교
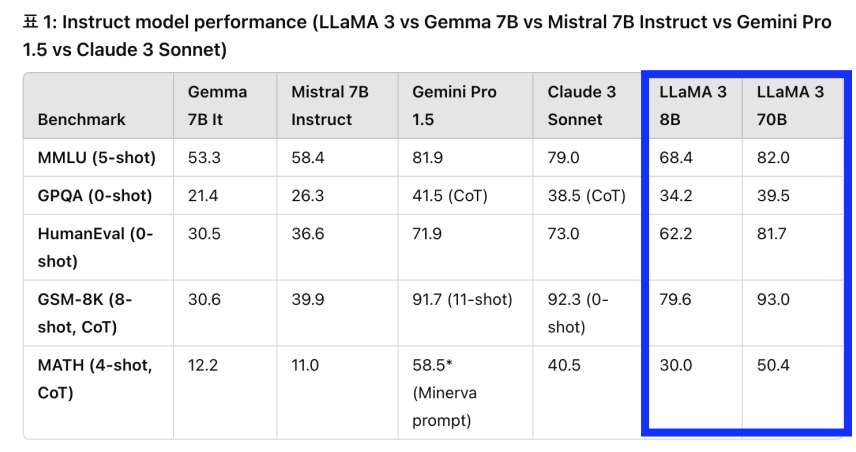
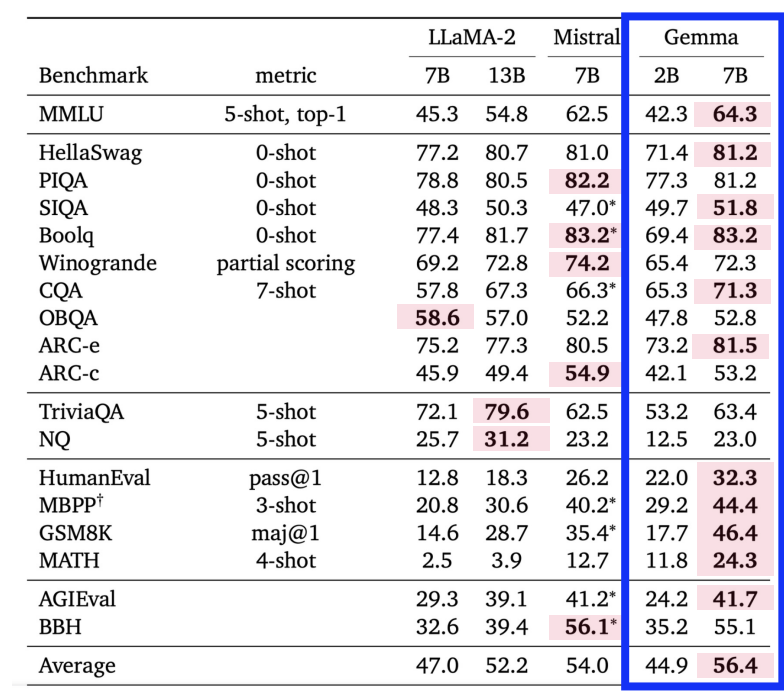
(2) Gemma (Google)
a) 기본 정보
- Gemini 모델 기술 + 상대적으로 작은 크기로 인해 노트북, 데스크톱 또는 자체 클라우드 인프라와 같이 리소스가 제한된 환경에 배포 가능
- 3개의 version: 2B, 7B, 7B + Instruct
b) 성능 비교
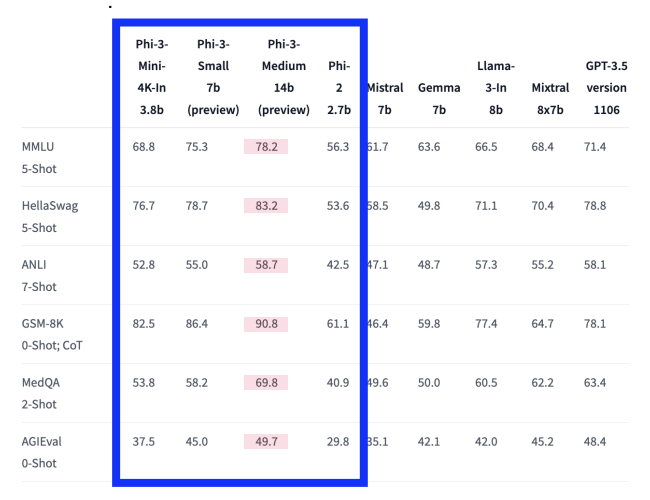
(3) Phi-3 (Microsoft)
a) 기본 정보
- Microsoft가 개발한 소형 개방형 모델
- 언어/추론/코딩/수학 벤치마크 등에서, (동일 크기 모델 대비) 뛰어난 성능
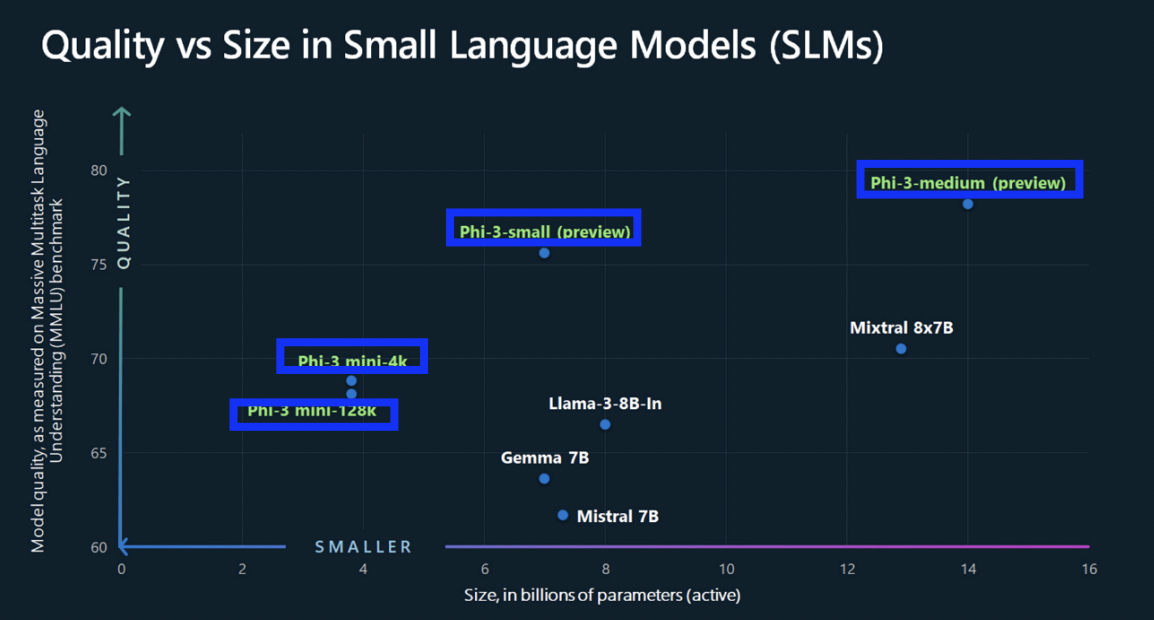
b) 성능 비교
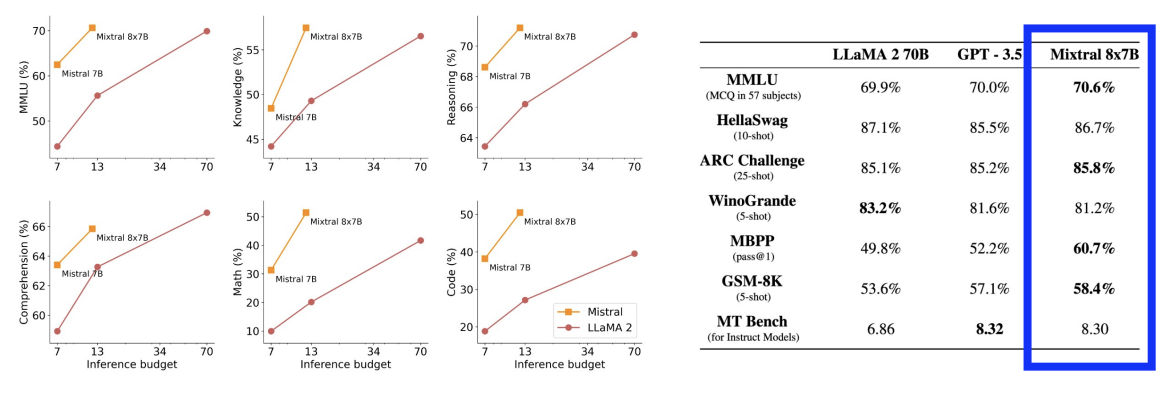
(4) Mixtral 8x7B (Mistral AI)
a) 기본 정보
- MoE 구조: 7B 모델 x 8개
- 각 모델이 특정 작업/도메인에 최적화
- 모델 분할 및 최적화
- 앙상블 결합
- 병렬 처리
b) 성능 비교
(5) 기타
Stable LM2 (Stability)
- 1.6B의 경량화된 모델
- 다국어 데이터에 대한 훈련
Falcon (UAE)
- 11B의 경량화된 모델
Solar-mini (Upstage)
Gemini nano (Google)
Reference
- [패스트캠퍼스] 8개의 sLM모델로 끝내는 sLM 파인튜닝