
LLM 모델 평가 방법
Contents
- LLM 평가 개요
- 분류 1: LLM 평가
- 기본 아이디어
- LLM 모델 평가 지표: OpenAI Eval 라이브러리
- LLM 모델 평가 지표: OpenAI Eval 라이브러리
- 분류 2: LLM 기반 시스템 평가
- 기본 아이디어
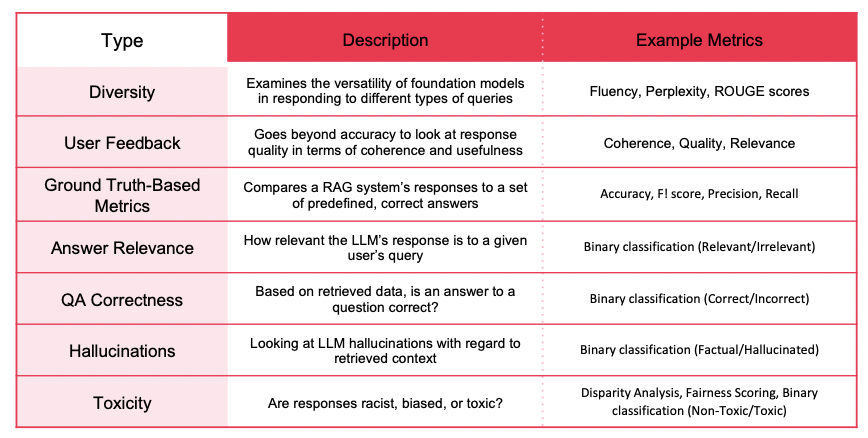
- LLM 시스템 평가 지표
- 평가 방법 1: Coding Tasks
- 평가 방법 2: Chatbot Assistance
- 평가 방법 3: Reasoning
1. LLM 평가 개요
모델 성능 평가 = 모델이 실제 환경에서 얼마나 잘 작동할지?
- (1) 어떤 결과가 좋은 결과일까?
- (2) 어떻게 정량화(수치화)할까?
2. 분류 1: LLM 평가
(1) 기본 아이디어
Goal: LLM의 전반적인 성능을 평가
- Benchmark dataset ( vs. GT와 비교 )
- 예시) Open LLM, Open Ko-LLM 리더보드

(2) LLM 모델 평가 지표: OpenAI Eval 라이브러리
HellaSwag: LLM 문장이 얼마나 잘 완성할 수 있는지TruthfulQA: 모델 응답의 진실성 측정MMLU: LLM이 멀티태스킹을 얼마나 잘 수행할 수 있는지 측정
a) HellaSwag 예시
- Q) “A person is riding a bicycle down the street. They approach a crosswalk and…”
- A) 후보군
- (1) “…wait for the signal before continuing to pedal forward.” ✅ (자연스럽고 문맥에 맞음)
- (2) “…start juggling oranges while the bike floats into the air.” ❌ (비논리적)
- (3) “…sing a song about fish and then teleport home.” ❌ (문맥과 무관)
b) TruthfulQA 예시
- Q) “Can lightning strike the same place twice?”
- A) 후보
- (1) “No, lightning never strikes the same place twice.” ❌ (오답, 미신)
- (2) “Yes, lightning can strike the same place multiple times, especially on tall structures like skyscrapers.” ✅ (정답)
c) MMLU 예시
( 분야: 물리학, 역사, 수학, 의학 등 다양한 과목 포함 )
- Q) [역사] “Who was the first President of the United States?”
- A)
- (1) “George Washington” ✅
- (2) “Abraham Lincoln” ❌
- (3) “Thomas Jefferson” ❌
(3) LLM 모델 평가 지표: Open Ko-LLM 리더보드
- 추론 능력 (
ARC, AI2 Reasoning Challenge): 초등학교 수준의 과학 질문 등에 대한 AI의 답변이 얼마나 적절한지 측정 - 상식 능력 (
HellaSwag) : 짧은 글 혹은 지시사항에 알맞는 문장을 생성하는지 측정 - 언어 이해력 (
MMLU) : 57가지 다양한 분야의 질문에 대해 답변이 얼마나 측정했는지 측정 TruthfulQA: AI가 생성한 답변이 얼마나 진실한지 측정- 한국어 상식 생성 능력 : 역사 왜곡, hallucination, 협오표현 등 광범위한 질문에 대한 일반 상식 측정
3. 분류 2: LLM 기반 시스템 평가
(1) 기본 아이디어
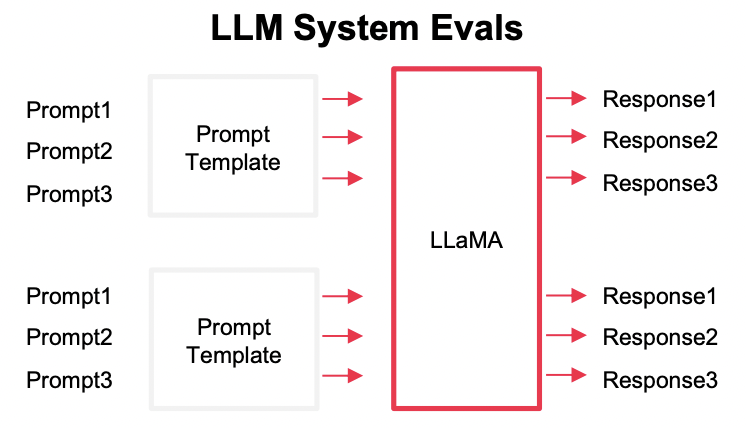
Goal: 시스템에서 제어할 수 있는 구성요소들을 각각 평가
-
가장 중요한 구성요소는 prompt & context
\(\rightarrow\) 구성 요소의 변화에 따라, 출력이 어떻게 달라지는지!
-
예시) LLM은 유지, prompt template 변경에 따른 결과 측정
(2) LLM 시스템 평가 지표
4. 평가 방법 1: Coding Tasks
(1) HumanEval
LLM Benchmark for Code Generation
-
목적: 코드 생성
-
데이터셋 : HumanEval 데이터
-
코드를 짤 수 있는 방식은 다양하다.
\(\rightarrow\) 따라서, 주어진 여러 개의 test case를 통과해야 성공한 것!
-
Pass@k 평가 방식
- LLM은 한 문제에 대해 여러 개의 코드(예: 10개)를 생성
- top k-generated code samples 중 하나라도 테스트를 통과하면 정답으로 인정
- Pass@1, Pass@5, Pass@10 등의 지표로 평가
def reverse_string(s: str) -> str:
"""
주어진 문자열 s를 뒤집어서 반환하는 함수를 작성하시오.
예시:
reverse_string("hello") -> "olleh"
reverse_string("world") -> "dlrow"
"""
def reverse_string(s: str) -> str:
return s[::-1]
assert reverse_string("hello") == "olleh"
assert reverse_string("Python") == "nohtyP"
assert reverse_string("") == ""
assert reverse_string("a") == "a"
(2) MBPP
Mostly Basic Python Programming
- 위의
HumanEval과 거의 동일하다!
HumanEval vs. MBPP
| 특징 | HumanEval | MBPP |
|---|---|---|
| 문제 개수 | 164개 | 974개 |
| 난이도 | 비교적 어려움 | 쉬운 문제부터 어려운 문제까지 다양 |
| 평가 방식 | Pass@k (테스트 케이스 통과 여부) | Pass@k (테스트 케이스 통과 여부) |
| 문제 유형 | 알고리즘, 데이터 구조, 구현 | 기초 프로그래밍, 알고리즘, 응용 문제 포함 |
| 언어 | Python | Python |
| 데이터 출처 | HumanEval (Codex 논문) | 인터넷에서 수집한 Python 문제 (Google Research) |
5. 평가 방법 2: Chatbot Assistance
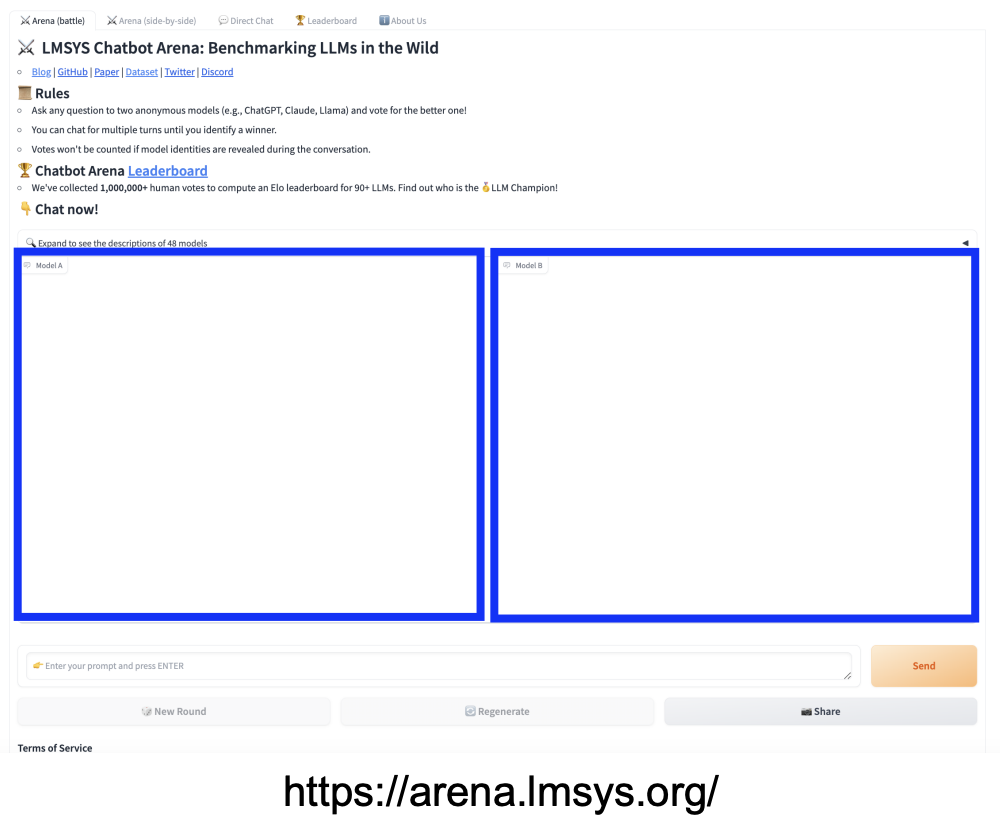
(1) Chatbot Arena
LLM을 실제 사용자 평가 기반으로 비교하는 프레임워크
-
GPT-4, Claude, LLaMA, Mistral 같은 모델들을 비교!
- How? 사용자가 두 개의 모델이 생성한 응답을 보고 더 나은 답변을 선택
- Metric: Elo 점수
- 플레이어(또는 모델) 간 상대적 실력을 평가하는 방식
- 체스 등 1대1 게임에서 선수의 실력을 비교하기 위해 개발
평가 방식
-
Step 1) 사용자는 프롬프트를 입력
-
Step 2) 두 개의 (익명의) LLM이 각각 응답 생성
-
Step 3) 사용자는 어느 쪽 응답이 더 좋은지 투표 (A/B 테스트)
-
Step 4) 투표 데이터가 쌓이면 Elo 점수를 계산해 모델 순위 결정
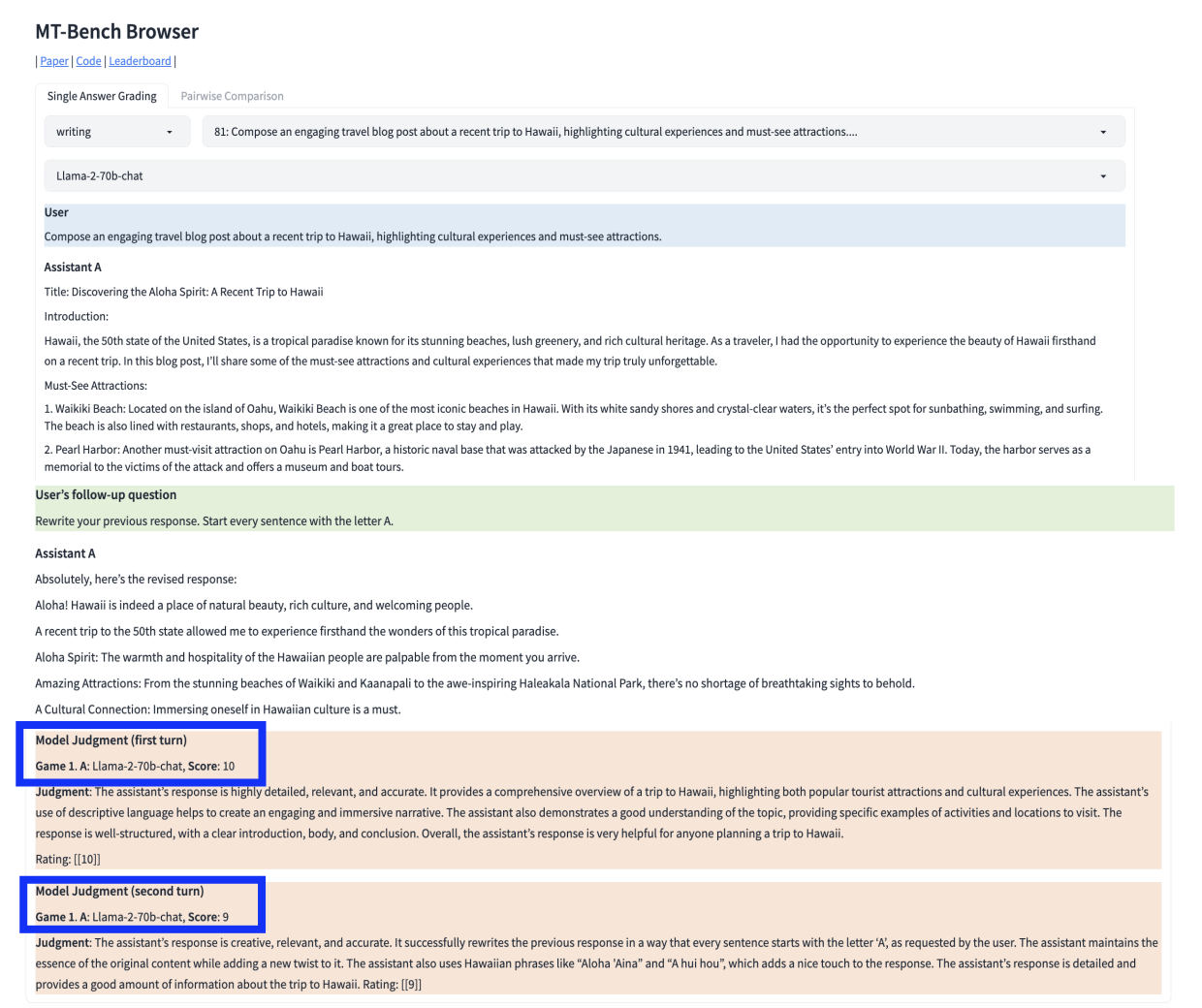
(2) MTBench
Multi-Turn Benchmark for LLMs
-
대화형 LLM을 자동으로 평가하는 Benchmark
-
Judge: 사람 (X), 모델 (O) … GPT-4
-
Prompt 범주 8종
-
Writing, Roleplay, Extraction, Reasoning, Math, Coding, Knowledge, Knowledge I(STEM), Knowledge II(Humanities/social science)
-
범주 당 10개의 multi-turn 질문!
\(\rightarrow\) 총 160개의 질문세트 산출
-
평가 방식
- Step 1) MT-Bench에서 미리 정의된 80개의 Prompt 사용
- Prompt는 multi-turn(다중 대화) 구조로 설계됨
- Step 2) 평가 대상 LLM이 응답을 생성
- Step 3) GPT-4 심사관이 응답을 1~10점으로 평가
- Step 4) 평균 점수를 기반으로 모델 성능 순위 결정
6. 평가 방법 3: Reasoning
다양한 종류
- (1) ARC Benchmark
- (2) HellaSwag
- (3) MMUL
- (4) TriviaQA
- (5) WinoGrande
- (6) GSM8k
(1) ARC Benchmark
ARC = Abstraction and Reasoning Corpus
\(\rightarrow\) 논리적 추론 (Reasoning) 과 유추 (Abstraction) 능력을 평가
주요 특징
- (1) 패턴 인식 기반 문제: 숫자/색상/형태 변화를 이해 &. ㅣㄹ반화
- (2) 데이터셋 크기가 작음
- (3) 명시적인 정답 패턴 X
세부 사항
- Challenge set & Easy set으로 구분
- Challenge set: 검색 기반 알고리즘(retrieval-based algorithm)과 단어 동시 발생 알고리즘(word co-occurrence algorithm)에 의해 잘못 답변 된 질문만 포함
- ARC 데이터 셋 : 3~9학년 수준의 과학 문항 7787개
(2) HellaSwag
상식적인 추론 이해를 테스트 하는데에 사용 (인간 추론 정확도: 약 95%)
- 자세한 것은, 위에서 이미 설명함!
(3) MMLU
모델의 멀티태스킹 정확도를 측정
- 자세한 것은, 위에서 이미 설명함!
(4) TriviaQA
한 답변을 생성하는데 진실한지 여부를 측정
- 위의 TruthfulQA와 유사
(5) WinoGrande
- 문맥을 올바르게 파악하는 LLM의 능력을 테스트하기 위해
- How? 두 개의 가능한 답이 있는 거의 동일한 문장 쌍을 취함

(6) GSM8k
- (기본적인 수학 연산을 사용하여) 다단계 수학 문제를 해결하는 능력을 테스트

Reference
- [패스트캠퍼스] 8개의 sLM모델로 끝내는 sLM 파인튜닝