
sLM 구축을 위한 기반 기술
Contents
-
Huggingface 기초
-
OLLama
- LangChain
- Vector DB
- RAG
1. Huggingface 기초
Huggingface 주요 기능
- 모델 & 데이터셋
- API token 발급받아서 write 기능 O
코드 예시
HF_API_KEY: Hugging Face (HF)의 API키 넣기
import requests
HF_API_KEY = 'hf_xxx'
BASE_URL = "https://api-inference.huggingface.co/models/{}"
headers = {"Authorization": f"Bearer {HF_API_KEY}"}
def get_url(BASE_URL, model_name):
return BASE_URL.format(model_name)
def query(API_URL, headers, payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
(1) Summarization task
API_URL = get_url(BASE_URL, 'facebook/bart-large-cnn')
payload = {
"inputs": "The tower is 324 metres (1,063 ft) tall, about the same height as an 81-storey building, and the tallest structure in Paris. Its base is square, measuring 125 metres (410 ft) on each side. During its construction, the Eiffel Tower surpassed the Washington Monument to become the tallest man-made structure in the world, a title it held for 41 years until the Chrysler Building in New York City was finished in 1930. It was the first structure to reach a height of 300 metres. Due to the addition of a broadcasting aerial at the top of the tower in 1957, it is now taller than the Chrysler Building by 5.2 metres (17 ft). Excluding transmitters, the Eiffel Tower is the second tallest free-standing structure in France after the Millau Viaduct.",
"parameters": {"do_sample": False},
}
output = query(API_URL, headers, payload)
(2) Question Answering task
API_URL = get_url(BASE_URL, 'deepset/roberta-base-squad2')
payload = {
"inputs": {
"question": "What's my name?",
"context": "My name is Clara and I live in Berkeley.",
}
}
output = query(API_URL, headers, payload)
(3) Sentence Similarity task
API_URL = get_url(BASE_URL, 'sentence-transformers/all-MiniLM-L6-v2')
payload = {
"inputs": {
"source_sentence": "That is a happy person",
"sentences": ["That is a happy dog", "That is a very happy person", "Today is a sunny day"],
}
}
output = query(API_URL, headers, payload)
(4) Text Classification task
API_URL = get_url(BASE_URL, 'distilbert-base-uncased-finetuned-sst-2-english')
payload = {"inputs": "I like you. I love you"}
output = query(API_URL, headers, payload)
(5) Translation task
API_URL = get_url(BASE_URL, 'Helsinki-NLP/opus-mt-ru-en')
payload = {"inputs": "Меня зовут Вольфганг и я живу в Берлине"}
output = query(API_URL, headers, payload)
(6) Audio Automatic Speech Recognition task
import json
def query_asr(API_URL, filename):
with open(filename, "rb") as f:
data = f.read()
response = requests.request("POST", API_URL, headers=headers, data=data)
return json.loads(response.content.decode("utf-8"))
API_URL = get_url(BASE_URL, 'facebook/wav2vec2-base-960h')
output = query_asr(API_URL, "sample1.flac")
2. OLLaMA
-
Open-source LLM을 로컬에서 쉽게 실행할 수 있게하는 도구
-
Modelfile 관리: 모델 가중치, 설정, 데이터셋 등을 하나의 ‘model file’로 관리함
코드 예시
pip install ollama
ollama pull mistral
import ollama
(1) 텍스트 생성
response = ollama.chat(model="mistral",
messages=[{"role": "user", "content": "Explain quantum computing"}])
output = response["message"]["content"]
(2) 대화 문맥 유지
- 아래와 같이, 대화의 흐름을 유지할 수 있음!
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is machine learning?"}
]
response = ollama.chat(model="mistral",
messages=messages)
messages.append(response["message"]) # 모델의 응답을 메시지 목록에 추가
messages.append({"role": "user",
"content": "Can you give me an example?"})
response = ollama.chat(model="mistral",
messages=messages)
output = response["message"]["content"]
3. LangChain
LLM을 쉽게 활용할 수 있도록 도와주는 라이브러리
- 단순히 프롬프트를 넣고 답변을 받는 게 아니라, 더 복잡한 작업을 수행할 수 있도록 도와줌
LangChain의 핵심 개념
- LLM: 다양한 모델을 연결
- Prompt Templates: 프롬프트를 체계적으로 관리
- Chains: 여러 개의 단계를 연결해서 더 복잡한 흐름을 만들 수 있음
- Memory: 대화의 맥락을 유지 가능 (챗봇 만들 때 유용!)
- Agents & Tools LLM이 검색, 데이터베이스, API 호출 등을 직접 할 수 있음
코드 예시
pip install langchain
pip install -qU langchain-openai
import os
from langchain_openai import ChatOpenAI
os.environ["OPENAI_API_KEY"] = "xxxxx"
model = ChatOpenAI(model="gpt-3.5-turbo")
요청 사항
SystemMessage: 역할 (Task) 부여HumanMessage: 요청 내용
from langchain_core.messages import HumanMessage, SystemMessage
messages = [
SystemMessage(content="Translate the following from English into Italian"),
HumanMessage(content="hi!"),
]
(1) LM 사용하기
model.invoke(messages)
AIMessage(content='Ciao!', response_metadata={'token_usage': {'completion_tokens': 3, 'prompt_tokens': 20, 'total_tokens': 23}, 'model_name': 'gpt-3.5-turbo-0125', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None}, id='run-c3907c33-ca0f-46ff-a502-fa46a181b84b-0', usage_metadata={'input_tokens': 20, 'output_tokens': 3, 'total_tokens': 23})
(2) OutputParsers
- 위 (1)의 출력 결과는 AIMessage이다.
- 이 대신에, string response를 원한다면,
StrOutputParserparser를 사용하자!
from langchain_core.output_parsers import StrOutputParser
parser = StrOutputParser()
result = model.invoke(messages)
parser.invoke(result)
'Ciao!''
(3) Prompt Templates
- Template활용을 통해 보다 편리하게 관리할 수 있음!
from langchain_core.prompts import ChatPromptTemplate
system_template = "Translate the following into {language}:"
prompt_template = ChatPromptTemplate.from_messages(
[("system", system_template), ("user", "{text}")]
)
result = prompt_template.invoke({"language": "italian", "text": "hi"})
result
ChatPromptValue(messages=[SystemMessage(content='Translate the following into italian:'), HumanMessage(content='hi')])
result.to_messages()
[SystemMessage(content='Translate the following into italian:'),
HumanMessage(content='hi')]
(4) Vector stores and retriever
LangChain에서 vector store(벡터 저장소)와 retriever(검색기)는 데이터를 효과적으로 검색하는 기능을 제공함
- 특히 RAG (Retrieval-Augmented Generation) 에서 중요
- 필요성: LLM이 답변을 생성 시, 기존의 지식만으로는 부족할 수 있음. 따라서, 외부 DB나 문서를 참고!
- Vector stores (벡터 저장소)
- 문서를 숫자로 변환(벡터화)해서 저장하는 공간
- Ex) FAISS, Chroma등의 DB
- Retrievers (검색기)
- 질문과 관련 있는 문서를 벡터 저장소에서 찾아주는 역할
- 사용자가 질문하면, retriever가 적절한 문서를 찾아 LLM에게 전달함
pip install langchain langchain-chroma langchain-openai
Step 1) 참고할만한 문서(내용)을 직접 입력함
from langchain_core.documents import Document
documents = [
Document(
page_content="Dogs are great companions, known for their loyalty and friendliness.",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="Cats are independent pets that often enjoy their own space.",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="Goldfish are popular pets for beginners, requiring relatively simple care.",
metadata={"source": "fish-pets-doc"},
),
Document(
page_content="Parrots are intelligent birds capable of mimicking human speech.",
metadata={"source": "bird-pets-doc"},
),
Document(
page_content="Rabbits are social animals that need plenty of space to hop around.",
metadata={"source": "mammal-pets-doc"},
),
]
Step 2) 문서를 벡터화 한 이후, 저장하기!
-
Chroma: 벡터 저장소를 사용하기 위한 모듈 -
OpenAIEmbeddings: 문서를 벡터로 변환하는 임베딩 모델
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
vectorstore = Chroma.from_documents(
documents,
embedding=OpenAIEmbeddings(),
)
Step 3) 특정 내용 기반으로 similarity search
vectorstore.similarity_search("cat")
[Document(page_content='Cats are independent pets that often enjoy their own space.', metadata={'source': 'mammal-pets-doc'}),
Document(page_content='Cats are independent pets that often enjoy their own space.', metadata={'source': 'mammal-pets-doc'}),
Document(page_content='Dogs are great companions, known for their loyalty and friendliness.', metadata={'source': 'mammal-pets-doc'}),
Document(page_content='Dogs are great companions, known for their loyalty and friendliness.', metadata={'source': 'mammal-pets-doc'})]
vectorstore.similarity_search_with_score("cat")
[(Document(page_content='Cats are independent pets that often enjoy their own space.', metadata={'source': 'mammal-pets-doc'}),
0.375326931476593),
(Document(page_content='Cats are independent pets that often enjoy their own space.', metadata={'source': 'mammal-pets-doc'}),
0.375326931476593),
(Document(page_content='Dogs are great companions, known for their loyalty and friendliness.', metadata={'source': 'mammal-pets-doc'}),
0.4833090305328369),
(Document(page_content='Dogs are great companions, known for their loyalty and friendliness.', metadata={'source': 'mammal-pets-doc'}),
0.4833090305328369)]
Retriever
- 단순히 저장하는 것만 하는 VectorStore와 다르게, Retrievers는 직접 실행 가능한(Runnable) 객체
- 따라서, LangChain Expression Language (LCEL)에서 체인으로 쉽게 연결할 수 있음
from typing import List
from langchain_core.documents import Document
from langchain_core.runnables import RunnableLambda
방법 1
retriever = RunnableLambda(vectorstore.similarity_search).bind(k=1)
방법 2
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 1},
)
retriever.batch(["cat", "shark"])
[[Document(page_content='Cats are independent pets that often enjoy their own space.', metadata={'source': 'mammal-pets-doc'})],
[Document(page_content='Goldfish are popular pets for beginners, requiring relatively simple care.', metadata={'source': 'fish-pets-doc'})]]
VectorStoreRetriever는 검색할 때 3가지 방법을 지원
- (1) Similarity (기본값)
- 입력된 쿼리와 가장 유사한 문서를 찾음.
- (2) MMR (Maximum Marginal Relevance)
- 유사한 문서 중에서도 서로 다른 정보를 포함한 문서를 다양하게 선택함.
- (3) Similarity Score Threshold
- 유사도가 일정 기준(Threshold) 이상인 문서만 반환함.
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
message = """
Answer this question using the provided context only.
{question}
Context:
{context}
"""
prompt = ChatPromptTemplate.from_messages([("human", message)])
rag_chain = {"context": retriever, "question": RunnablePassthrough()} | prompt | llm
response = rag_chain.invoke("tell me about cats")
response.content
'Cats are independent pets that often enjoy their own space.''
4. Vector DB
Vector DB: 정보를 벡터로 저장하는 DB
Top 5: Chorma, Weaviate, Qdrant, Milvus, Faiss


Step 1) 설치하기 & Client instance 생성
pip install chromadb
pip install sentence_transformers
import chromadb
chroma_client = chromadb.Client()
Step 2) 나만의 DB 생성
collection = chroma_client.create_collection(name="my_collection")
Step 3) Langchain 활용하기
pip install langchain-chroma
pip install langchain-community
pip install langchain-text-splitters
from langchain_chroma import Chroma
from langchain_community.document_loaders import CSVLoader
from langchain_community.embeddings.sentence_transformer import (
SentenceTransformerEmbeddings,
)
from langchain_text_splitters import CharacterTextSplitter
# Step 1) 문서 불러오기
loader = CSVLoader("/content/naver-news-summarization-ko/test_10row.csv", encoding='cp949')
documents = loader.load()
# Step 2) Chunking
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
# Step 3) Embedding 모델 불러오기
embedding_function = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
# Step 4) Embedding 후에 DB에 저장하기
db = Chroma.from_documents(docs, embedding_function)
# Step 5) query 기반으로 DB에서 search
query = "코오롱 수소 밸류체인 플랫폼"
docs = db.similarity_search(query)
# Step 6) 결과 확인
print(docs[0].page_content)
5. RAG
RAG(Retrieval-Augmented Generation)
- 검색 부분(Retrieval Component) : 정보 찾기
- 사용자의 질문 입력에 대해, 관련된 정보를 대규모 DB에서 검색
- 생성 부분(Generation Component) : 답변 생성
- 검색된 정보를 기반으로 자연스러운 언어의 답변 생성
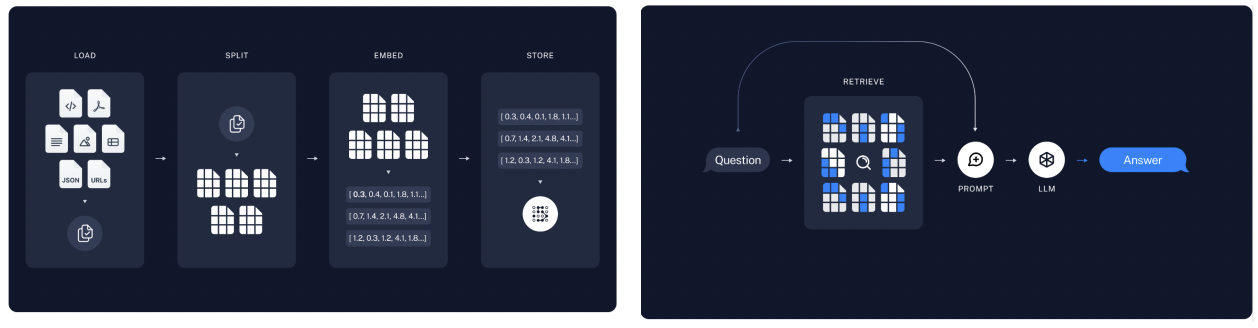
코드 실습
pip install --upgrade --quiet langchain langchain-community langchainhub langchain-openai langchain-chroma bs4
pip install -qU langchain-openai
pip install bitsandbytes==0.40.0 einops==0.6.1
pip install accelerate
관련 패키지 로드
import bs4
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_chroma import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
import os
hf_auth = 'xxxx'
os.environ["OPENAI_API_KEY"] = hf_auth
from torch import cuda, bfloat16
import transformers
device = f'cuda:{cuda.current_device()}' if cuda.is_available() else 'cpu'
Step 1) 모델 불러오기
# Step 1) Model 설정
model_id = 'meta-l정ama/Meta-Llama-3-8B'
# Step 2) Q-LoRA configuration
bnb_config = transformers.BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type='nf4',
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=bfloat16
)
# Step 3) Model 불러오기
model_config = transformers.AutoConfig.from_pretrained(
model_id,
use_auth_token=hf_auth
)
model = transformers.AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
config=model_config,
quantization_config=bnb_config,
device_map='auto',
use_auth_token=hf_auth
)
Step 2) Web으로부터 데이터 불러오기
bs4_strainer = bs4.SoupStrainer(class_=("post-title", "post-header", "post-content"))
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs={"parse_only": bs4_strainer},
)
docs = loader.load()
# print(docs[0].page_content[:500])
Step 3) 불러온 데이터 chunking하기
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200, add_start_index=True
)
all_splits = text_splitter.split_documents(docs)
Step 4) 저장하기
Chroma: Chroma DB에 저장할 것이다!OpenAIEmbeddings: 어떤 Embedding function을 사용할 지
from langchain_chroma import Chroma
from langchain_community.embeddings import FastEmbedEmbeddings
from langchain_openai import OpenAIEmbeddings
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
Step 5) 유사도 기반으로, DB에서 검색하고 불러오기
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 6})
retrieved_docs = retriever.invoke("What are the approaches to Task Decomposition?")
len(retrieved_docs) # Top6이므로 6개
print(retrieved_docs[0].page_content)
Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.
Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.
Reference
- [패스트캠퍼스] 8개의 sLM모델로 끝내는 sLM 파인튜닝