Training LLMs to Reason in a Continuous Latent Space (arxiv, 2024)
Hao, Shibo, et al. "Training large language models to reason in a continuous latent space." arXiv preprint arXiv:2412.06769 (2024).
참고: https://www.youtube.com/watch?v=0u3pxwO1dXw
( https://arxiv.org/pdf/2412.06769 )
Contents
- Tl; dr
- (1) Concept of CoT
- (2) Methods for training CoT
- (3) COCONUT
Tl;dr
CoT vs. COCONUT (proposed)
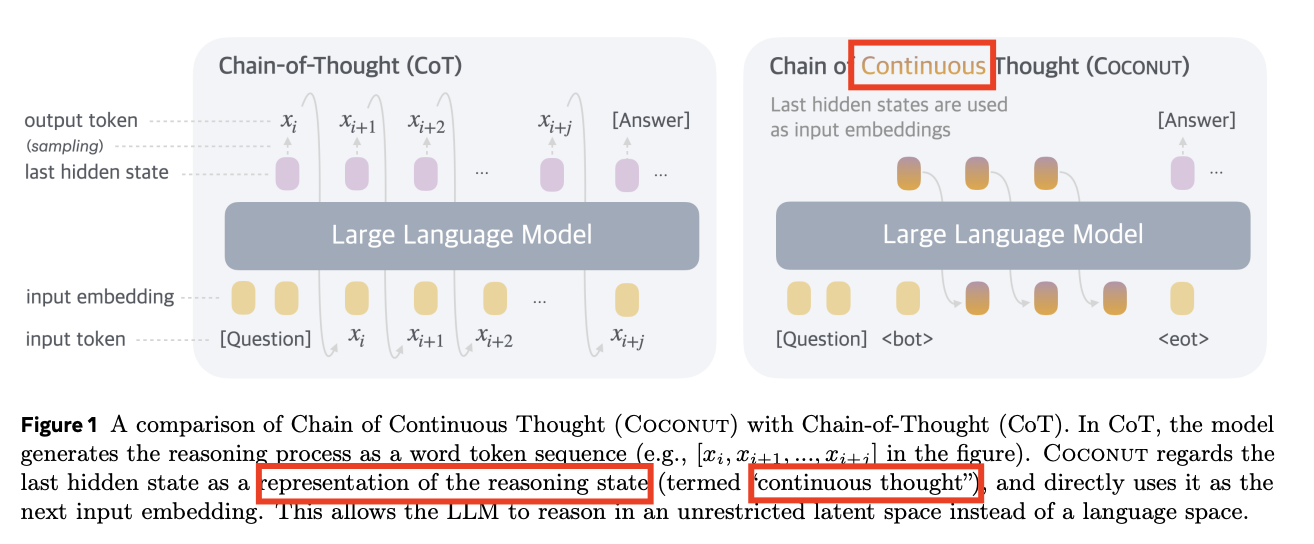
- (1) CoT: reasoning 과정을 “discrete”한 text로 표현
- 추론 시: 모든 reasoning step에 대한 token 필요 \(\rightarrow\) 비효율적
- (2) COCONUT (proposed): ~ “continous”한 representation ~
- 추론 시: ~ latent space에서 ~ \(\rightarrow\) 효율적
1. Concept of CoT
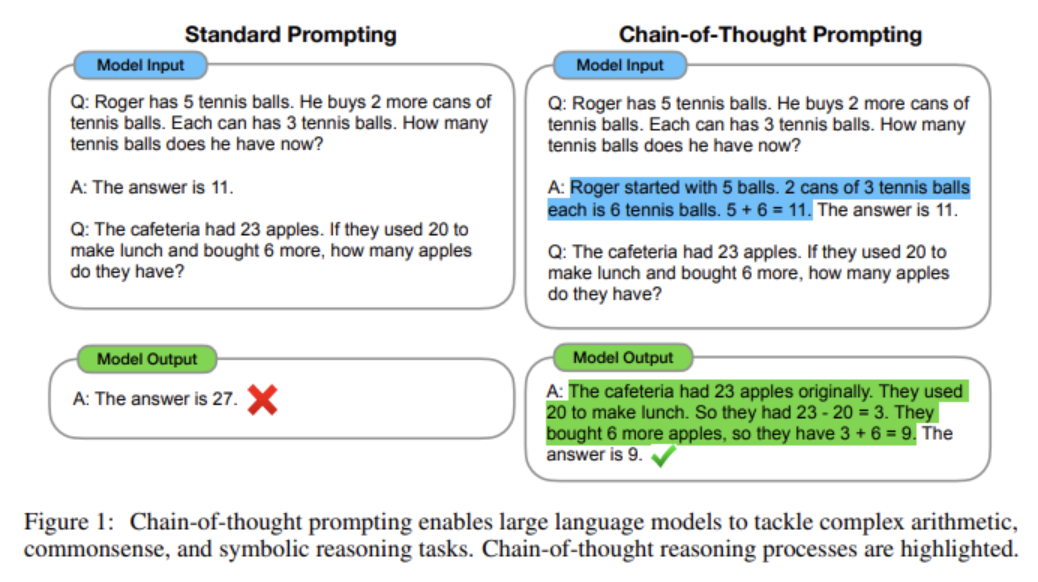
(a) Standard prompting vs. (b) CoT prompting
- (a): ICL을 통해 question
- (b): ICL을 통해 reasoning 과정 유도
When useful?
\(\rightarrow\) (추론 과정을 많이 요구하는) 복잡한 태스크 일 경우!
CoT in Agents
- Agent 연구에서 활발히 적용되고 있음.
- Why useful? 문제를 세분화해서 푸는 경우가 많기 때문에! (복잡한 step-by-step 추론 요구)
Limitations of previous methods
- 고작 하나의 질문을 위해, 수 많은 (Question-Thought-Answer pair) x K개의 수많은 불필요한 token을 prompt에 넣어줘야!
2. Methods for training CoT
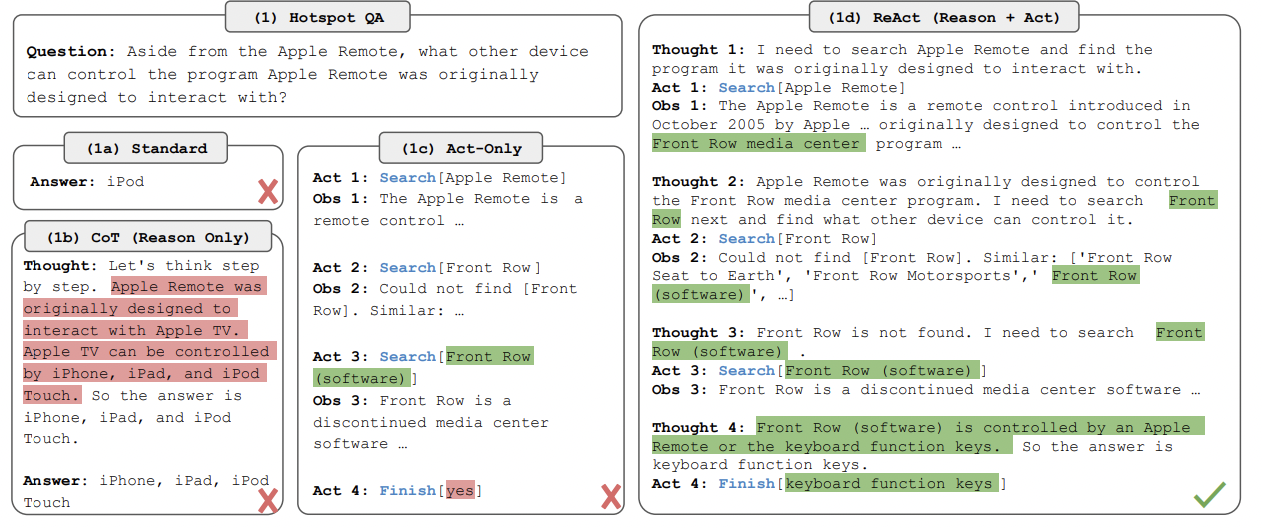
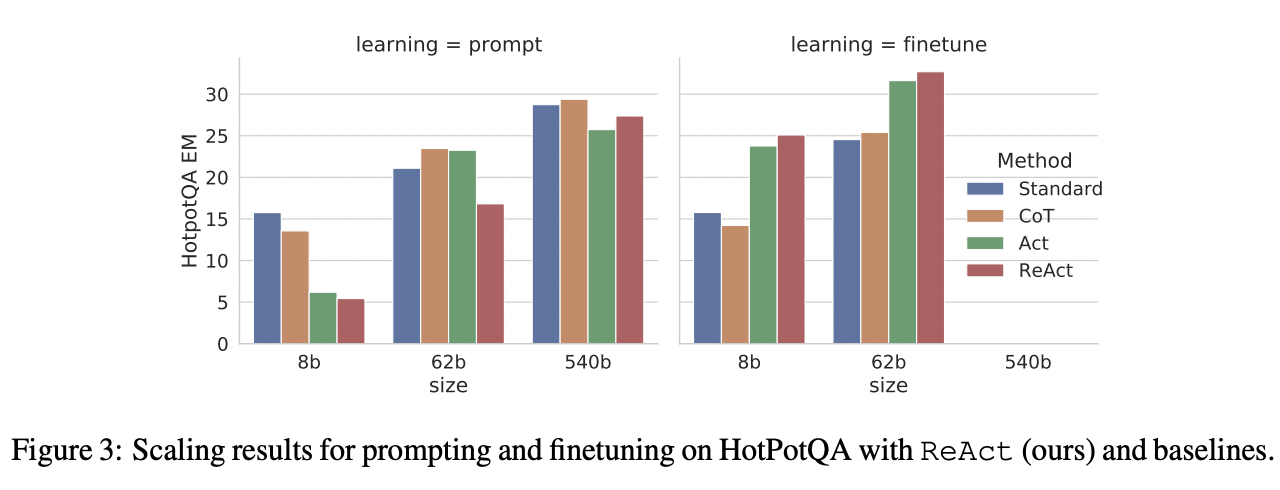
(1) ReAct
https://arxiv.org/abs/2210.03629
CoT를 (ICL로 하는 대신) 직접 학습하면 되지 않을까? (e.g., ReAct)
- 장점: few shot의 K개 샘플로 인한 입력 길이가 길어지는 것을 방지!
Comparison
- Standard: Q \(\rightarrow\) A
- CoT: Q \(\rightarrow\) thought \(\rightarrow\) A
- Act: Q \(\rightarrow\) tool \(\rightarrow\) A
- ReAcT: Q \(\rightarrow\) reasoning with tool \(\rightarrow\) A
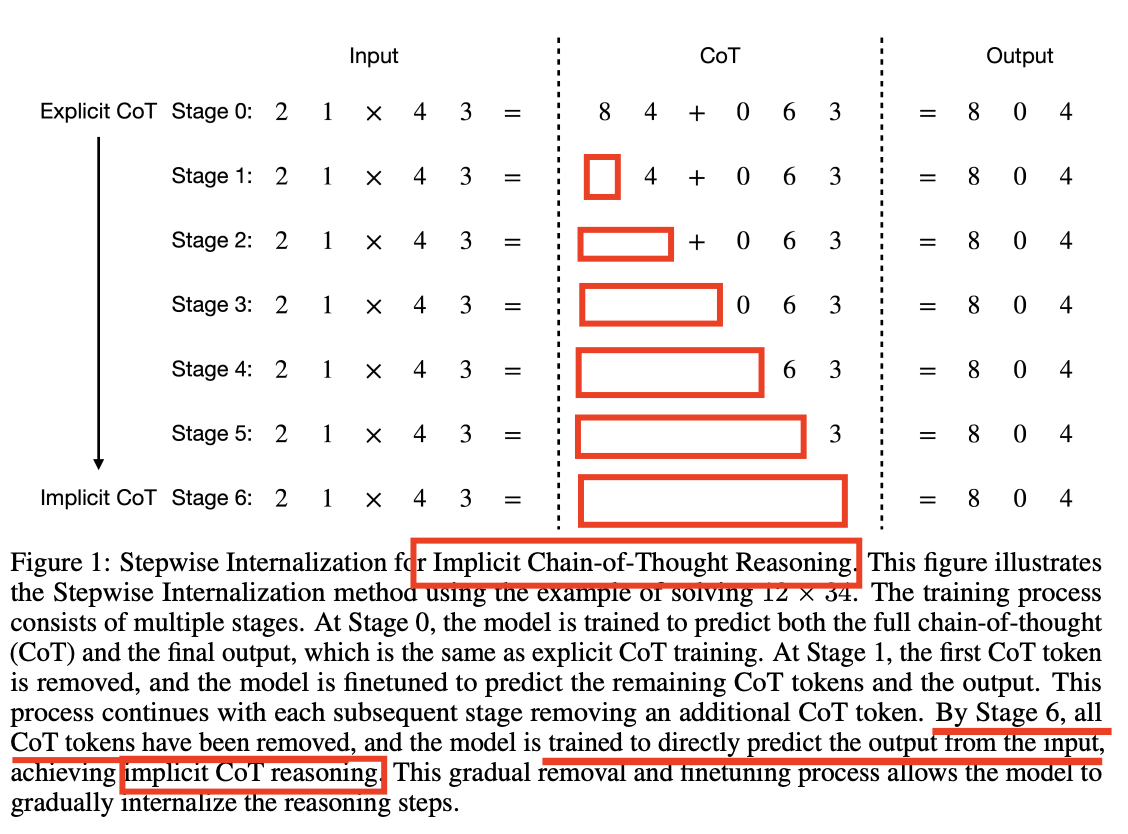
(2) Implicit CoT
ICoT: Why not Internalize CoT??
- (1) CoT: “ICL을 통한” reasoning 유도
- (2) Training: “Training을 통한” reasoning 유도
- (3) ICoT: “Training을 통한” reasoning 과정 내재화
- (2)와의 차이점? reasoning을 표면적으로 생성 X
How? 학습 과정에서, Q\(\rightarrow\)A를 단계적으로 생성
Curriculum learning을 통해!
- (기본) Training data: (Q\(\rightarrow\) reasoning \(\rightarrow\) A)
- 위 데이터를 통해 reasoning을 직접 학습함!
- (추가) 일정 epoch마다 초기 K개의 토큰을 생략!
- 일종의 더 “빡센” 환경을 유도
- 결국, 마지막에는 “reasoning 없이” ( = reasoning 과정/실력이 내재화되어서 이미 학습되어 있음 ) 직접 answer를 내뱉음
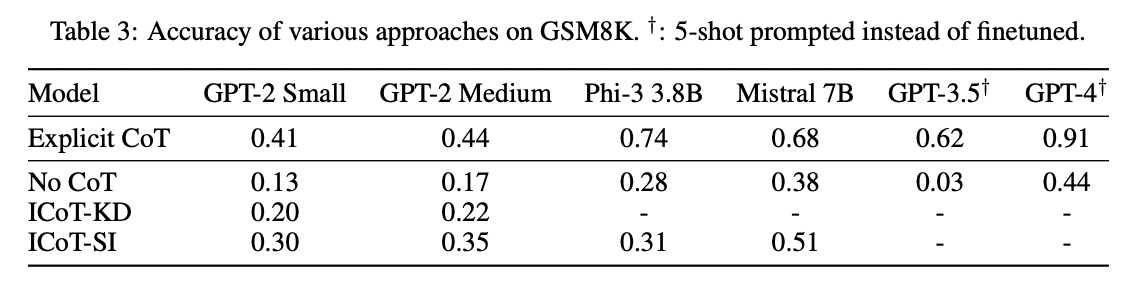
Reasoning의 역할
- (1) 학습 과정: Answer에 대한 “보조적 정보” 역할
- (2) 추론 과정: Answer에 대한 “단계적 정보” 역할

3. COCONUT
Summary of (previous CoT)
- CoT: reasoning의 중요성 발견
- ICL을 통한 reasoning 유도
- ReACT: CoT를 “학습”하자!
- ICoT: Reasoning 과정을 학습을 통해 “내재화”하자!
- curriculum learning의 중요성 제시
Proposed Methods
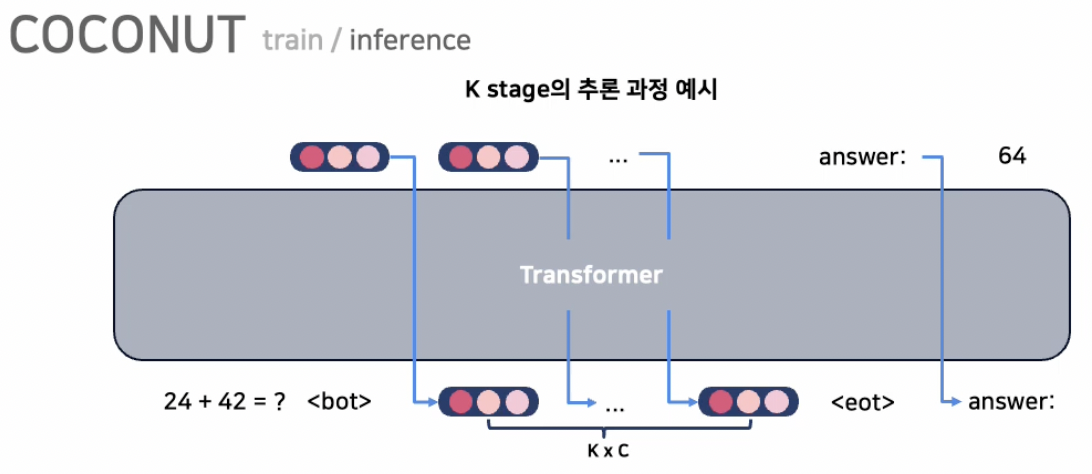
Key point: Reasoning을 내재화할 때, latent representation에서 학습하자!
Two modes
-
(1) Language mode (discrete, text)
- “언어 형태”로 표현됨
- 이전 토큰 \(\rightarrow\) 다음 토큰 예측
-
(2) Latent mode (continuous)
-
“잠재 공간 상”에 표현됨
-
이전 respresentation \(\rightarrow\) 다음 representation
( = continous thought )
-
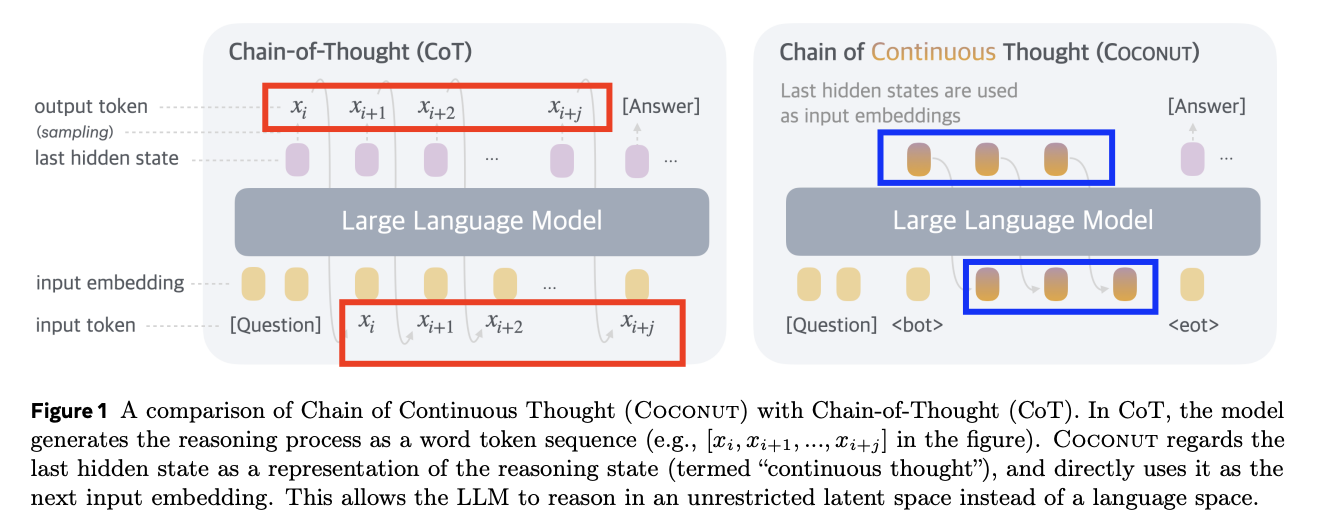
필요성 예시

- 위에서, 우리는 색깔로 칠해진 숫자 부분 외에는 필요한 것이 없다!
- 즉, 나머지는 불필요한 discrete 텍스트
- 필요한 것은, 그것이 담긴 continuous한 의미일 뿐!
- 따라서, 그 외에 생성되는 모든 정보/토큰들은 다 불필요. 낭비다!
요약: Continous thought 활용 시의 이점
- (1) Efficient: 더 적은 reasoning 비용
- (2) End-to-end: 어떠한 reasoning이 좋은 reasoning인지 end-to-end로 학습 가능
Details
(1) 학습 과정: curriculum learning (feat. ICoT)
- 공통점: step이 지날 수록 앞의 정보를 단계적으로 삭제
- 차이점: 삭제하는 대상이 token (X) representation (O)
(2) 학습 목표:
-
Question \(\rightarrow\) Continuous thought \(\rightarrow\) Answer의 추론 과정을 내재화
( end-to-end로 continous thought이 학습이 될 것! )
(3) Special token
<bot>,<eot>: latent mode의 시작과 끝을 알리는 latent space 상에서의 토큰

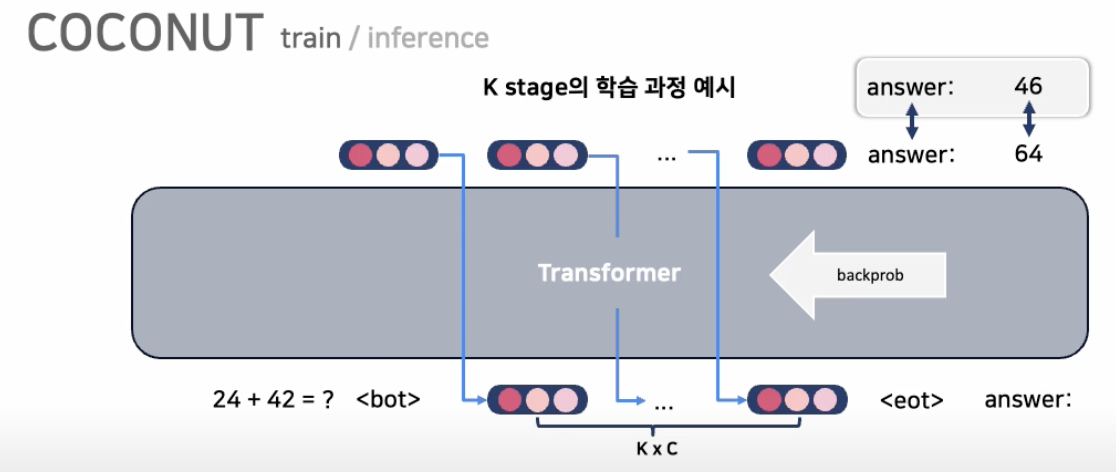
Q) (inference 시) latent mode의 길이는?
-
즉, 언제 thought을 끝내고 (<eot> 토큰 생성) 나와서 answer를 내뱉을지?
( <bot>는 그냥 질문 시작과 함께 넣으면 되는데 … )
-
방법: 고정된 길이만큼의 latent mode 사용을 강제함