
Active prompting (ACL, 2024)
Diao, Shizhe, et al. "Active prompting with chain-of-thought for large language models." ACL (2024)
참고: https://www.youtube.com/watch?v=OTP52AURAok&t=371s
Contents
- (1) Proposal
- (2) Various CoTs
- 2-1) Manual CoT
- 2-2) Zero-shot CoT
- 2-3) Auto-CoT
- 2-4) Complex CoT
- 2-5) Self-consistency
- (3) Active prompting with CoT for LLMs
- 3-1) Active Prompt
- 3-2) Chain-of-knowledge
1. Proposal
- Active Prompt
- 아이디어: Task별로 가장 적합한 CoT 예시를 선정
- 기준: uncertainty score
- Chain-of-knowledge
- 아이디어: 모델이 이해하기 쉽게 정보를 전달
2. Various CoTs
(1) Manual CoT
Pros & Cons
- pros) 정확함
- cons) requires human label
(2) Zero-shot CoT
“Let’s think step by step”
Pros & Cons
- pros) w/o human label
- cons) too simple
Pipeline
- Step 1) reasoning extraction
- LLM에 “Let’s think step by step”를 넣어줌으로써 나온 추론 과정 ( = reasoning path ) 생성
- Step 2) answer extraction
- 앞서 생성한 reasoning path를 함께 넣어줌
- 요약) 입력 prompt: (1) question + (2) let’s think step by step + (3) reasoning path
(3) Auto CoT = (1) + (2)
- (1)처럼 성능을 어느 정도 보장하면서도
- (2)처럼 자동으로 생성되도록!
Step 1) 모든 질문들을 K개의 cluster로 나눔
Step 2) 클러스터 별 1개씩 질문 선정 ( = 총 K개의 질문)
Step 3) K개의 질문에 대해 (Zero-shot CoT로) Reasoning path 생성
Step 4) 최종 prompt: (1) + (2) + (3)
- (1) question
- (2) let’s think step by step
- (3) K개의 질문에 대한
- (3-1) question
- (3-2) let’s think step by step
- (3-3) reasoning path
\(\rightarrow\) Few-shot CoT가 가능해짐!
(4) Complex CoT
어떤 추론 과정 (reasoning path)가 좋을까?
\(\rightarrow\) 기본 아이디어: 복잡한 추론 과정을 우선시하자!
- ( 복잡하다 = 추론 step이 많다 = # steps )
Procedure
-
Step 1) 동일한 질문에 대해 N개의 reasoning path를 생성 (with Zero-shot CoT)
-
Step 2) Step 수(=complexity)로 sorting & step이 많은 Top K개의 reasoning path를 선택
- Step 3) 이 K개 중, 다수결 (Majority)로써 answer를 판단
- Step 4) 이를 선택한 최종 reasoning path를 선정
(5) Self-Consistency
목적: 가장 일관성 있는 답을 도출하자!
Procedure
- Step 1) 동일한 질문에 대해 N개의 reasoning path를 생성 (with Zero-shot CoT)
- Step 2) 여러 답들 중, 가장 일관성 있는 ( = majority )를 최종 답으로 선정
요약: “하나의 경로”를 통해 나온 답이 아닌, “여러 경로”를 통해 나온 여러 답을 종합하여 선택!
5가지 기법 비교
| 기법 | 설명 | 장점 | 단점 |
|---|---|---|---|
| 1. Manual CoT | 사람이 직접 단계별 추론 경로를 설계하는 방식 | - 해석 가능성이 높음 (명시적 추론 경로 제공) | - 설계에 많은 수작업이 필요- 다양한 문제에 확장성이 낮음 |
| 2. Zero-shot CoT | 학습 없이 사전 학습된 모델의 일반화 능력을 활용해 즉석에서 추론 경로 생성 | - 주석이 없는 데이터로도 사용 가능- 새로운 작업에 빠르게 적용 가능 | - 생성된 추론 경로의 정확도나 일관성이 낮을 수 있음- 모델의 사전 학습 품질에 의존적 |
| 3. Auto-CoT | 데이터 기반 또는 모델 생성 예제를 통해 자동으로 추론 경로를 생성 | - Manual CoT에 비해 수작업 감소- 다양한 작업에 적응 가능 | - 최적화에 많은 계산 자원이 필요- 데이터 품질 및 학습 알고리즘에 의존적 |
| 4. Complex CoT | 복잡한 문제를 해결하기 위해 설계된 고급 체인 오브 사고 | - 고난도 문제를 처리할 수 있음- 여러 단계의 추론을 체계적으로 수행 | - 설계 및 구현이 어려울 수 있음- 계산량 증가 가능 |
| 5. Self-consistency | 모델이 다양한 추론 경로를 생성하고 최빈값 또는 가장 일관된 답변을 선택 | - 답변의 신뢰도를 높일 수 있음- 모델의 다중 경로 추론 능력을 활용 | - 계산량이 많아질 수 있음- 적절한 평가 기준이 필요 |
3. Active prompting with CoT for LLMs
(1) Proposal 1) Active Prompt
-
기존의 한계점: “Task에 대한 고려 없이” 샘플을 선택함
\(\rightarrow\) 최선의 샘플이라는 보장 X
-
아이디어: Task 별 최적의 샘플을 찾자!
( = 태스크마다 가장 중요하고 유용한 샘플을 선택하자! )
( = 샘플에 대한 “모델 예측의 불확실성이 가장 높은” 샘플을 찾자! )
-
Procedure
- Step 1) Uncertainty estimation
- K번 답변을 생성 후, 이들을 기반으로 metric 계산
- Uncertainty metric: (1) disagreement & (2) entropy
- Step 2) Selection
- Uncertainty 기준으로 sorting & Top N개 선정
- Step 3) Annotation
- Top N개에 대해 annotation을 인간이 달기
- Step 4) Inference
- Step 1) Uncertainty estimation
(2) Proposal 2) Chain-of-knowledge
-
기존의 한계점: Textual reasoning chain을 바탕으로 태스크 수행
\(\rightarrow\) 외부 지식 활용 X, 오로지 학습된 정보만을 사용 O
\(\rightarrow\) Hallucination 문제 ( 검증 X )
-
아이디어: Triple의 구조로 추론을 수행 & 결과 검증을 하자
( = 추론 결과에 대한 “신뢰성 점수” 계산 후, 이를 개선시키도록! )
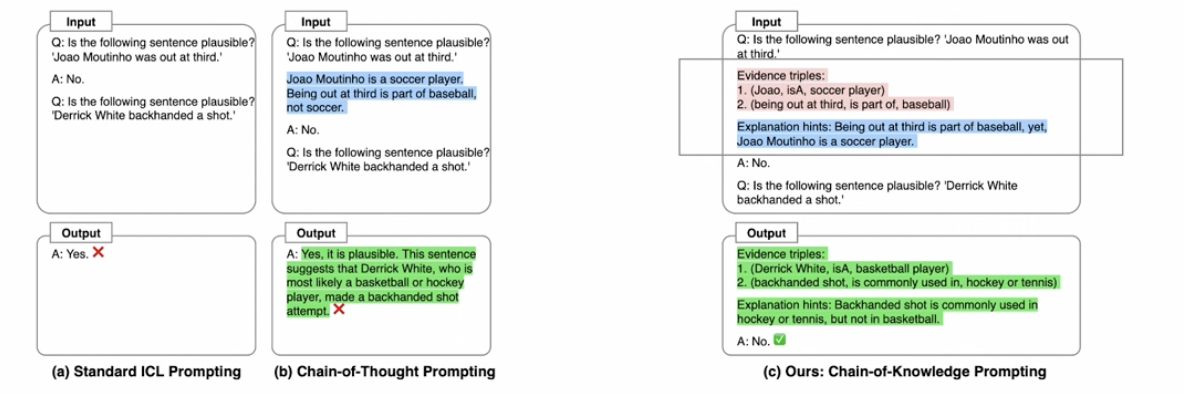
Components
- (1) Evidence triples (ET): 추론 증거
- ex) (Joao, isA, soccer player)
- ex) (being out at third, is part of, baseball)
- (2) Evidence hints (EH): ET에 대한 설명
How to obtain?
- (1) EH: Query + “Let’s think step by step” \(\rightarrow\) 출력 결과인 reasoning chain
- (2) ET: External knowledge base에서 EH와 관련 있는 triple 검색
추론 결과 검증 = Reasoning chain의 신뢰성 평가, with 2개의 요소
- (1) Factuality (사실성): 추론에 활용한 증거 vs. 실제 지식
- (2) Faithfulness (충실성): 추론에 활용한 증거 + 텍스트 설명 vs. 최종 답변
Framework
-
Step 1) Exemplars 구축 ( with ET + EH )
-
Step 2) Chain-of-Knowledge reasoning ( with Exemplars )
-
Step 3) F\(^2\) verification 통해 신뢰성 판단 ( 낮은 경우, rethinking process )
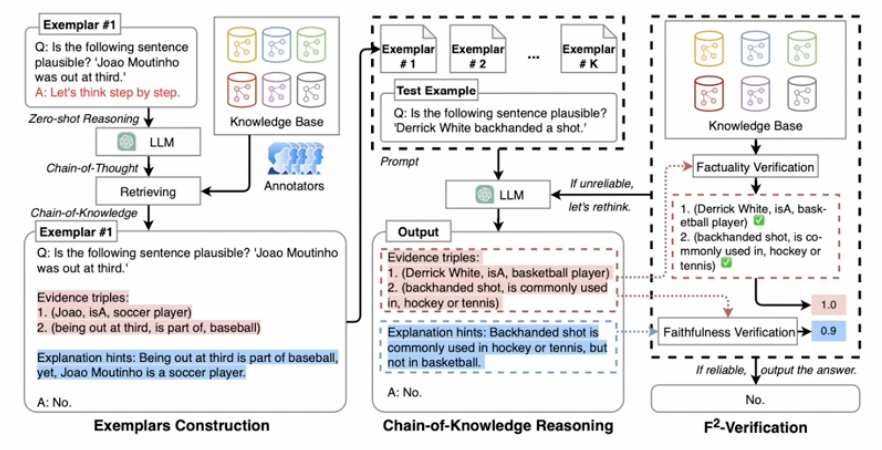
Step 1) Exemplars Construction
K개 질문 랜덤 선택 & exemplar 구축
- Step 1-1) EH 생성 (with Zero-shot CoT)
- Step 1-2) ET 생성
- KB에서 EH와 관련 있는 Triples 검색
- 그 중 적절한 것 선정 후 annotation
- Step 1-3) Exemplars = EH + ET
Exemplar #1 예시
(1) Question: xxx
(2) Evidence triples:
- a) (xx,xx,xx)
- b) (xx,xx,xx)
(3) Evidence hints: xxxxxxx
(4) Answer: xxxxx.
Step 2) Chain-of-Knowledge Reasoning
K개의 exemplars를 함께 활용하여, 최종 답 도출
입력으로 넣을 Prompt 예시:
Exemplar #1
Exemplar #2
..
Exemplar #K
(Test Example)
Q: xxxxxxx
Output:
(1) Evidence triples:
- (yyy,yyy,yyy)
- (yyy,yyy,yyy)
(2) Evidence hints: xxxxx
(3) Answer: xxxx
Step 3) F\(^2\) Verification (w/ rethinking process)
CoK reasoning으로 도출한 답에 대한 신뢰성 점수 (=Factuality & Faithfulness) 계산
(1) Factuality (0~1)
-
Why: (LLM이 생성한) ET가 사실인지 검증! (팩트 체크)
-
How: Triples가 KB에 존재하는지 여부 ( = if 존재 1, 부재 0 )
-
존재 안한다고해서, 반드시 거짓? No
\(\rightarrow\) “Triple의 타당성”을 점수로써 사용
- (Knowledge graph embedding 모델 사용하여) subject & object를 relation에 대해 투영 & 벡터 간의 거리를 점수로써 활용 (짧을수록 타당)
(2) Faithfulness (0~1)
-
Why: (LLM이 생성한) 추론이 답과 연결되는지를 검증!
-
How: EH이 (Question, ET, Answer)와 같은 맥락인가?
\(\rightarrow\) SimCSE 인코더를 통해 유사도 측정
신뢰성 점수 = (1) + (2)
재검토 (Rethinking process)
신뢰성 점수가 낮은 reasoning chain에 대해 수정
- Step1) CoK prompt 수정
- KB에서 triples를 다시 똑바로 찾자!
- Step 2) (수정된 prompt로) 새로운 reasoning chain 생성 (with Zero-shot CoT)
- Step 3) 신뢰성 점수 계산