Code Llama Paper Explained
Roziere, Baptiste, et al. "Code llama: Open foundation models for code." arXiv preprint arXiv:2308.12950 (2023).
참고:
- https://aipapersacademy.com/code-llama/
- https://arxiv.org/abs/2308.12950
Contents
- Background
- Pipeline
- Experiments
1. Background
Code Llama (by Meta AI)
= Family of open-source LLMs for code
Three types of models
- Foundation models: Code Llama
- Python specialization models: Code Llama – Python
-
Instruction-following models: Code Llama – Instruct
- Each type: 7B, 13B and 34B params.
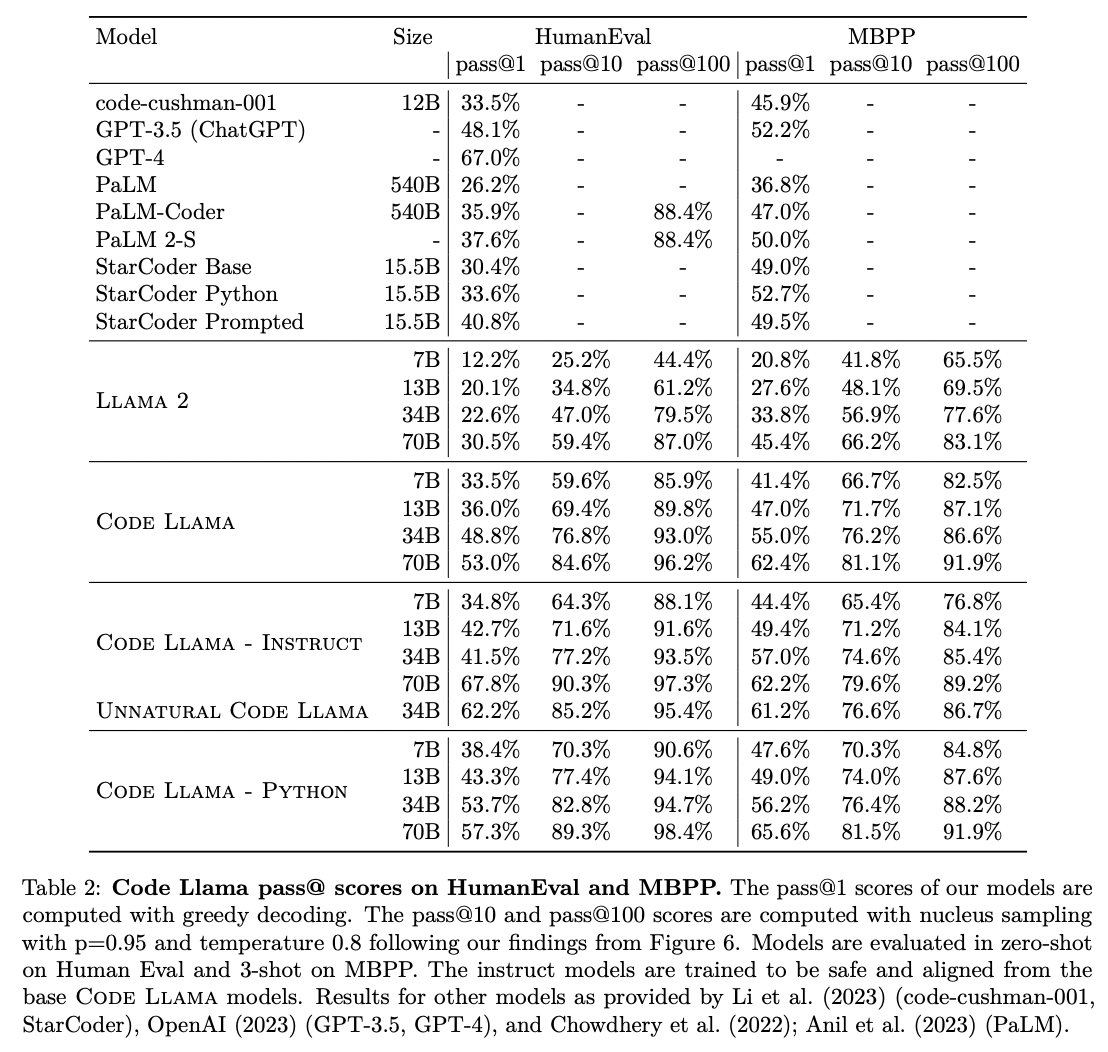
2. Pipeline
(Step 1) Pretrained model
Step 1) Starts with Llama 2 (trained on general purpos text & code data)
- (\(\leftrightarrow\) StarCoder: trained on code only)
(Step 2) Code Training & Infilling Code Training
[1] Code Training
-
Finetune on a code dataset (500B token)

-
Why natural language?
\(\rightarrow\) To keep its natural language understanding skills
-
[2] Infilling Code Training

( Only for the 7B and 13B versions of Code Llama and Code Llama – Instruct )
- LLM: Pretrained with Next Token Prediction
- Infilling: The model can get a surrounding context and predict the missing information. \(\rightarrow\) How??

(Step 3) Python Code Training
( Only for the Code Llama – Python model )
- Continue training on another dataset of 100B tokens which is targeted for python

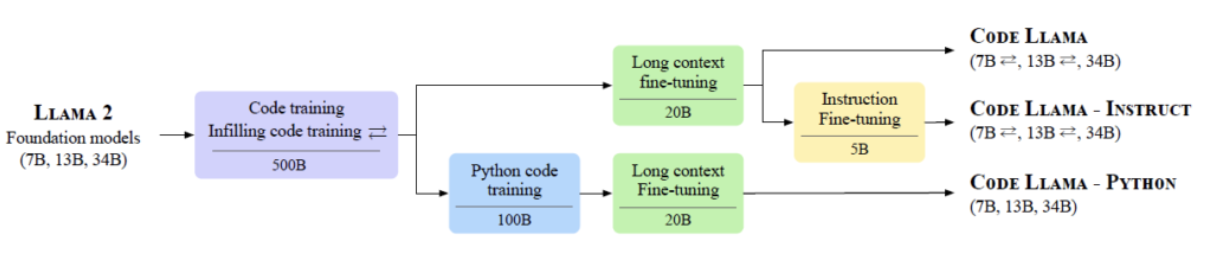
(Step 4) Long Context Fine-tuning
( Llama 2: supports a context length of 4,096 tokens )
\(\rightarrow\) With such context length, enable file-level reasoning
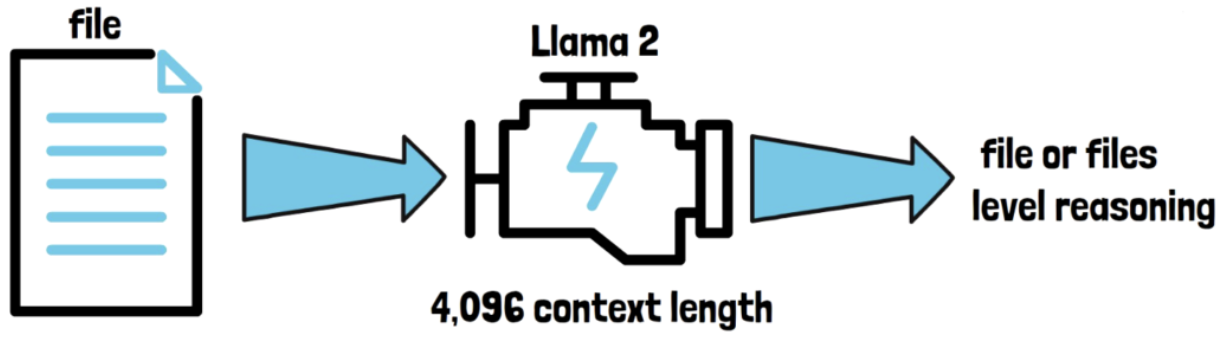
But with long context fine-tuning… the context length is increase to 100k
\(\rightarrow\) Feed the model with a full code repository and get repository-level reasoning
-
Actually fine-tuned with 16k length sequences and not 100k
( But it extrapolates well for sequences up to 100k tokens )
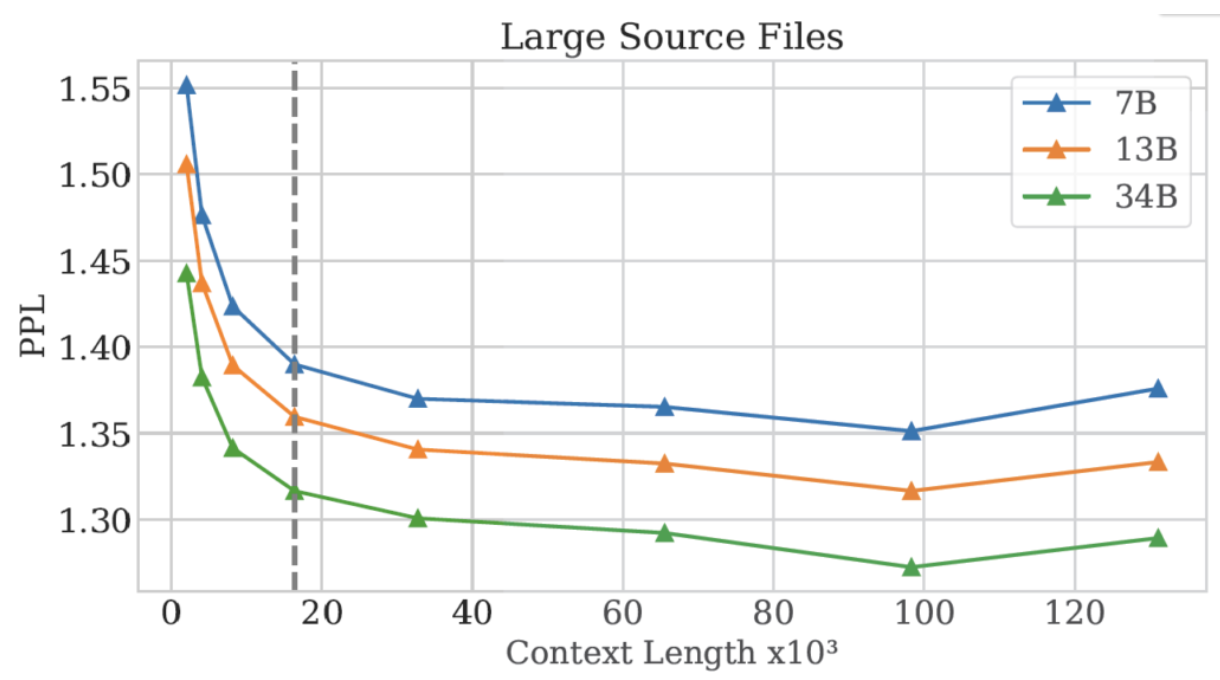
- X axis = context length
-
Y axis = perplexity of the models (PPL)
-
Dotted line = Context length in fine-tuning which is 16k
\(\rightarrow\) The perplexity keeps going down up to 100k tokens and then starts to go up.
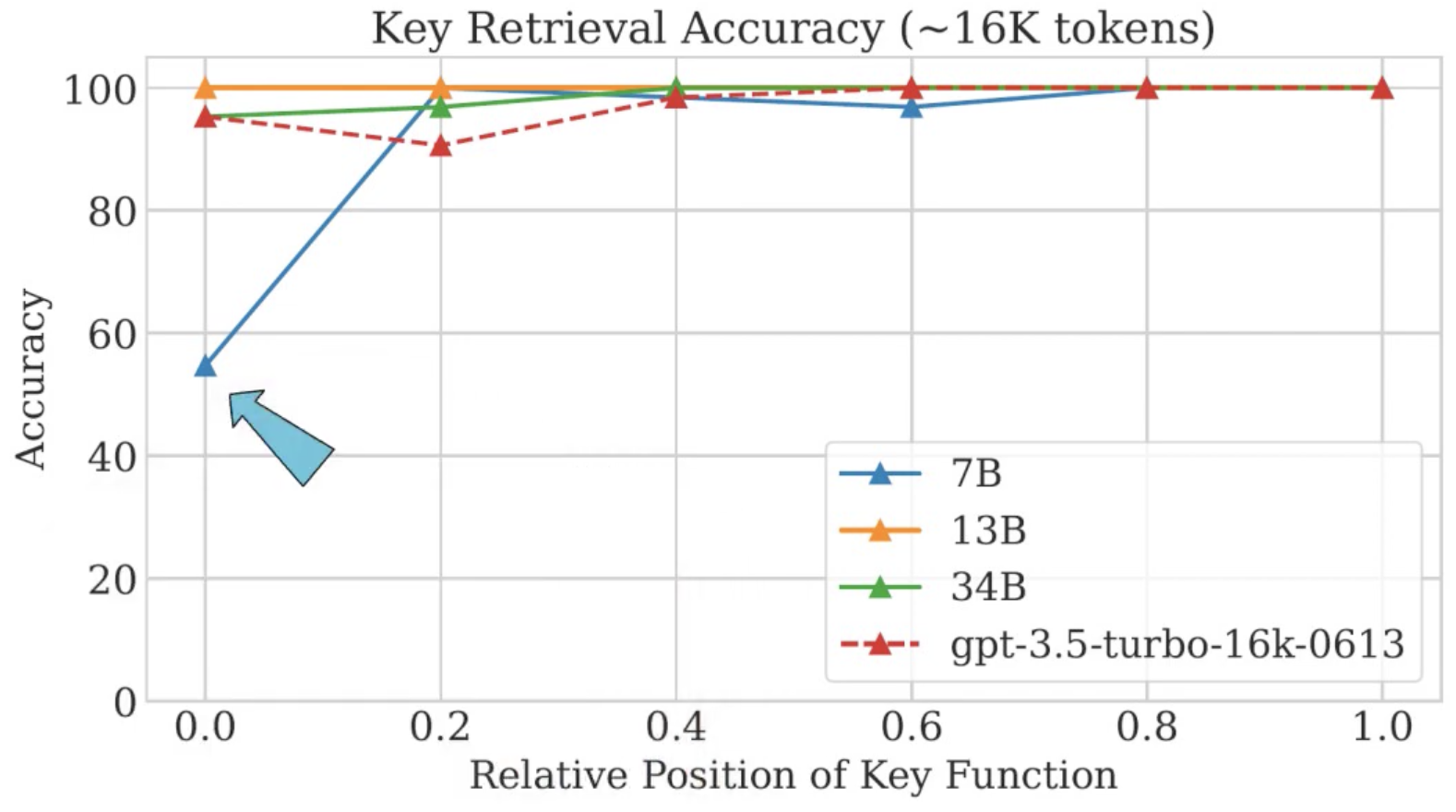
“Lost in the Middle: How Language Models Use Long Contexts” paper
- Abstract = It is harder for LLMs to reason based on information in the middle of the context, comparing to information in the beginning/end of the context
\(\rightarrow\) Only the 7B version seems to have a significant drop, when the answer sits in the beginning of the context
(Step 5) Instruction Fine-tuning

( Rather than providing a code context to complete or fill … )
Provide the model with prompt to create a Bash command (with few conditions)
Then, the model yields
- (1) the proper command
- (2) explanation about each part of the command
\(\rightarrow\) How does this work?
Instruction Fine-tuning with Self-Instruct
Three datasets
- (1) Same dataset used for instruction tuning of Llama 2
- Inherit Llama 2’s instruction-following and safety properties
- Does not contain many examples of code-related tasks
- (2) Dataset constructed using self-instruct method
Self-instruct?
-
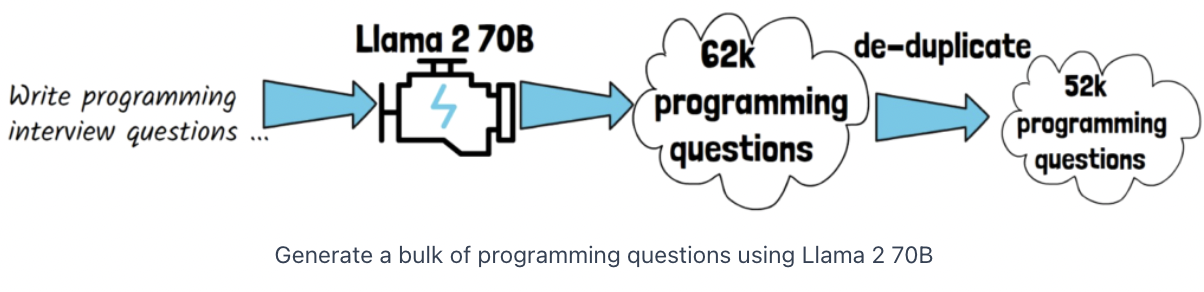
Step 1) Provide Llama 2 70B with a prompt to write programming interview questions
-
Step 2) Get 62,000 interview-style programming questions
( \(\rightarrow\) After removing exact duplicates we end with 52,000 questions )
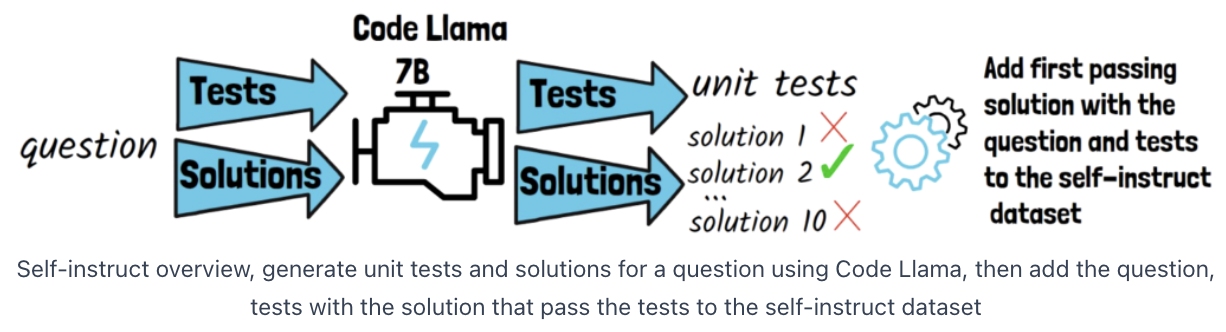
- Step 3) For each question, we pass it twice via Code Llama 7B
- (1) Prompt to generate unit tests for the question
- (2) Prompt to generate 10 solutions for the question
- Step 4) Run the unit tests on the generated solutions
- Accept the first passing solution
- Put the (question, answer) of the test to self-instruct dataset
3. Experiments