
ORPO: Large Language Models As Optimizers
참고:
- https://aipapersacademy.com/large-language-models-as-optimizers/
- https://arxiv.org/pdf/2309.03409
Contents
- Improving the Prompt
- ORPO
- OPRO Overview for Prompt Optimization
- Meta-prompt Structure
- Summary
- Experiments
1. Improving the Prompt
OPRO (Optimization by PROmpting)
( by Google DeepMind)
- New approach to leverage LLMs as optimizers
LLMs: (Input) Prompt \(\rightarrow\) (Output) Response
Extension: Better performance by extending the prompt with a carefully human crafted addition of an instruction
- e.g., “let’s think step by step”
\(\rightarrow\) Manually crafting the prompt can be tedious!
2. ORPO
ORPO = Extension to improve the prompt “automatically”
(1) OPRO Overview for Prompt Optimization
(a) Goal = Maximize the accuracy over a dataset with prompts and responses
- e.g., GSM8K dataset: word math problems
(b) How? By automatically yielding an instruction that will be added to the prompts in the dataset
- e.g, “let’s think step by step” or “break it down” …
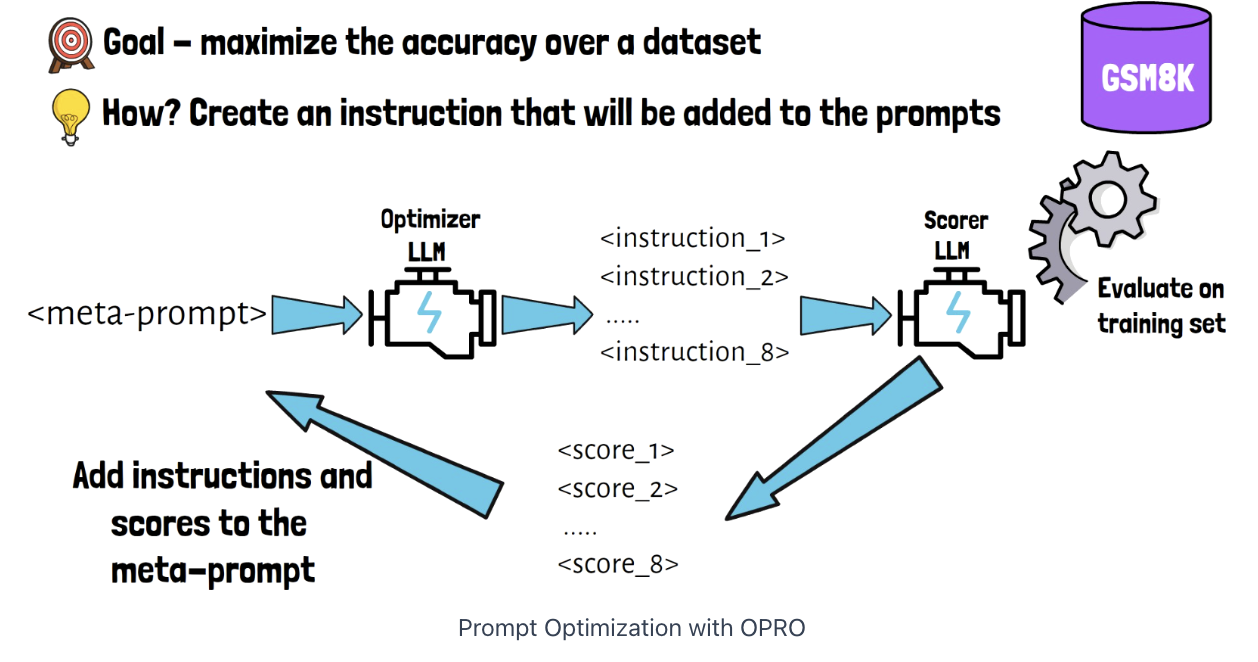
a) Optimizer LLM
(Input) Meta-prompt
- Meta-prompt instructs the optimizer LLM to yield few instructions
(Output)
- Yields 8 candidate instructions
b) Scorer LLM
Can be same as the optimizer LLM or a different one
(Input) Instructions
- Created by Optimizer LLM
(Output) Scores
-
Get 8 accuracy scores
\(\rightarrow\) Add (instruction, scores) to the meta-prompt again!
If we do not observe any improvement in the accuracy anymore …
\(\rightarrow\) End with the optimized instruction!
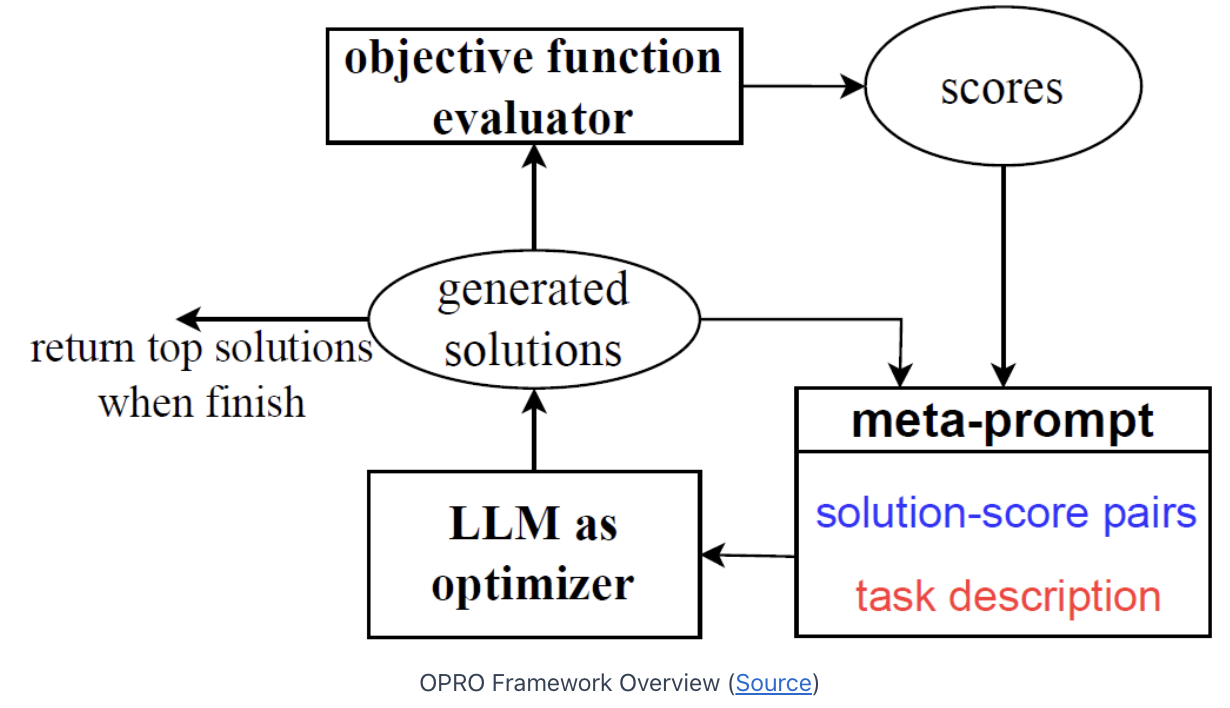
(2) Meta-prompt Structure
How is the meta-prompt is constructed??

(3) Summary
3. Experiments

- Outperforms the hand-crafted prompts!
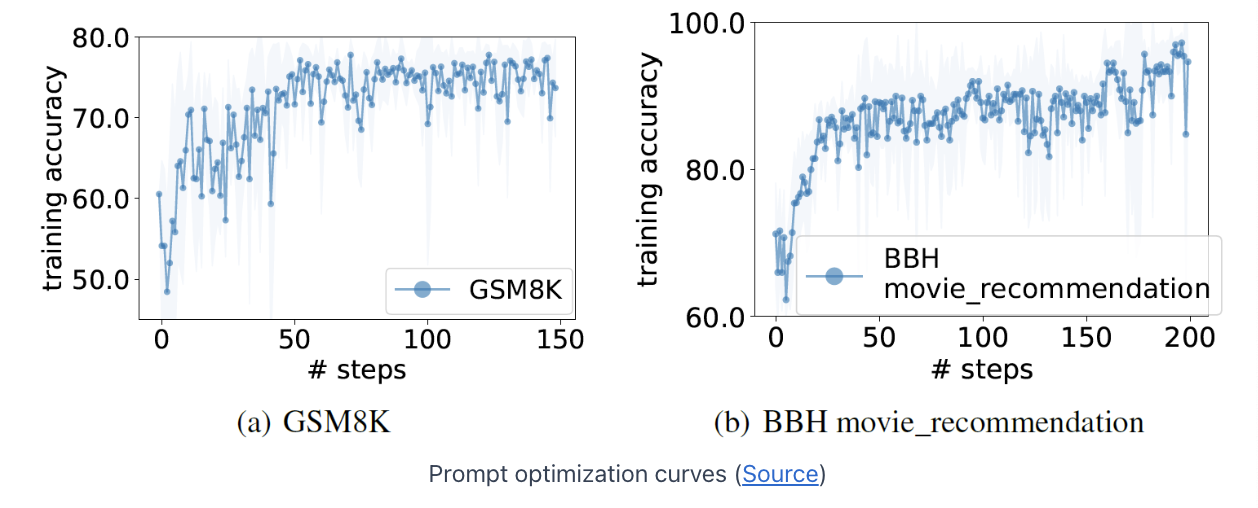
- The accuracy is increased when we make progress with the iterations