Orca: Progressive Learning from Complex Explanation Traces of GPT-4
Mukherjee, Subhabrata, et al. "Orca: Progressive learning from complex explanation traces of gpt-4." arXiv preprint arXiv:2306.02707 (2023).
( https://arxiv.org/pdf/2306.02707 )
참고:
- https://aipapersacademy.com/orca/
Contents
- Imitation Learning
- Limitation of Imitation Learning
- Datasets used for Orca
- Explanation Tuning
- Task Diversity & Data Scale
1. Imitation Learning
Imitation learning = Fine-tune on data that was generated by a different model
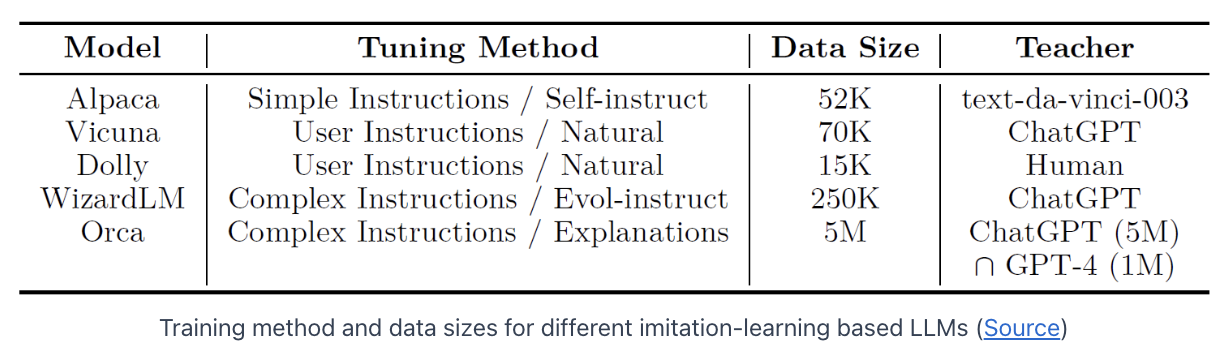
Various top LLMs (e.g., Vicuna, Alpaca and WizardLM)
- Step 1) Use base LLM (mostly LLaMA)
- Much smaller than the huge ChatGPT or GPT-4
- Step 2) Employ imitation learning
- Enhance the base model capability by fine-tuning it on a dataset that was created using responses from ChatGPT or GPT-4
2. Limitation of Imitation Learning
Proposal of Orca
With imitation learning as been done so far…
\(\rightarrow\) The models learn to imitate the “style” rather than the “reasoning process” of the huge models!!
\(\rightarrow\) Their capabilities are overestimated
Example 1
-
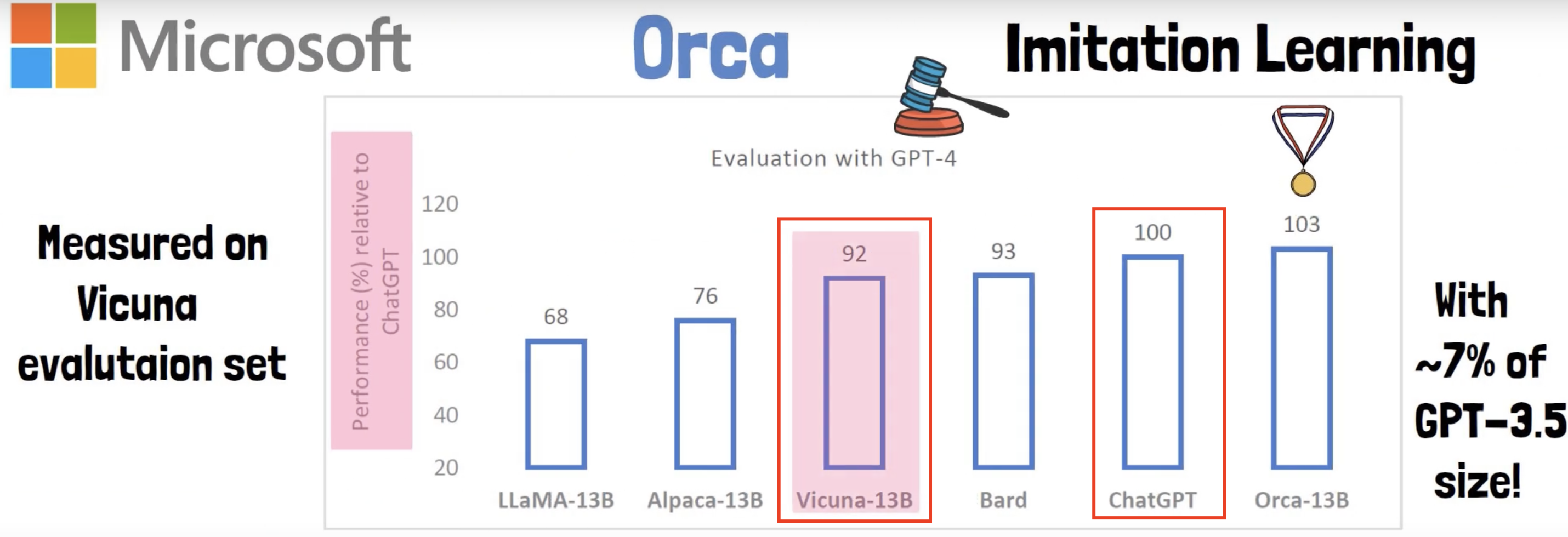
Vicuna reach 92% of ChatGPT quality, when GPT-4 is the judge
\(\rightarrow\) Problematic because GPT-4 may prefer responses from models that were fine-tuned on GPT responses
Example 2

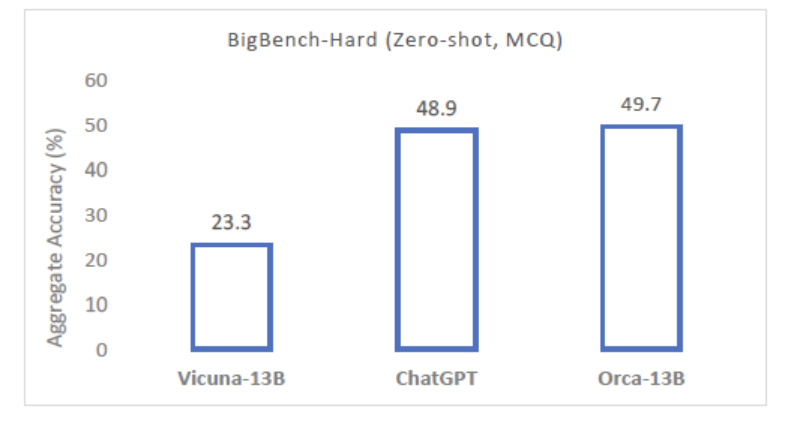
- # 1) Vicuna struggles with hard tasks
- # 2) Orca outperforms even ChatGPT, and improves over Vicuna by more than 100%!
3. Datasets used for Orca
Then, which dataset to use??
Orca = (1) Explanation Tuning + (2) Task Diversity and Data Scale
(1) Explanation Tuning
New approach for imitation learning
\(\rightarrow\) To allow the model to learn the thought process of the teacher model
Why current imitation-learning based models fail?
\(\rightarrow\) The responses they use for fine-tuning are mostly simple and short!
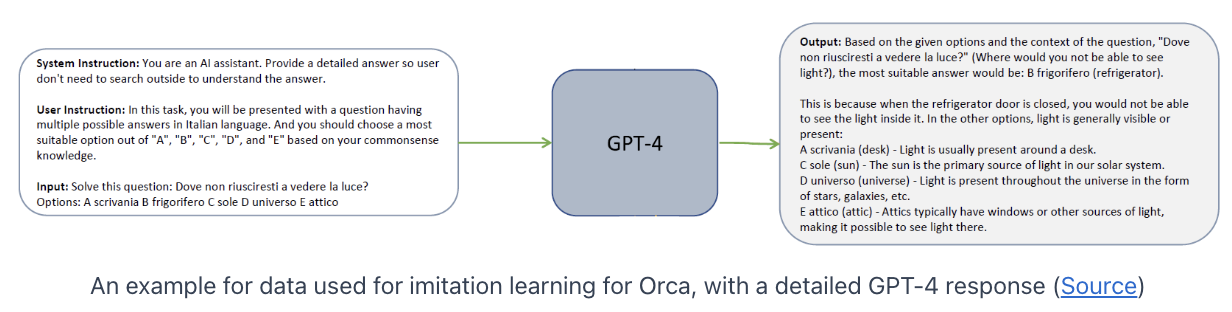
Orca dataset
- Use detailed responses from GPT-4 and ChatGPT
- that explain the reasoning process of the teacher as it generates the response.
- How? Add a “system instruction”

(2) Task Diversity & Data Scale