ReFT: Representation Finetuning for Language Models
Wu, Zhengxuan, et al. "Reft: Representation finetuning for language models." NeurIPS 2024
참고:
- https://aipapersacademy.com/reft/
- https://arxiv.org/pdf/2404.03592
Contents
- Introduction
- Motivation
- Proposal
- ReFT
- Previous works: LoRA
- Idea of ReFT
- LoReFT
- Experiments
1. Introduction
ReFT
- Promising novel direction for fine-tuning LLMs
- Excel at # params & performance
(1) Motivation
Finetuning a Pre-trained Transformer is expensive
\(\rightarrow\) Parameter-efficient finetuning (PEFT)
Parameter-efficient finetuning (PEFT)
- Only update a small number of weights!
- e.g., LoRA
- Add small adapter weights to the model layers
- Only update the added weights

(2) Proposal
ReFT = Representation Fine-Tuning
- LoReFT: Requires 10-50 times less parameters than LoRA
2. ReFT
(1) Previous works: LoRA
LoRA weights are baked into the Transformer
- Train small number of adapter weights
- Once trained, the weights are baked into the model
\(\rightarrow\) Representations are impacted by the added LoRA weights
( & Not the original representations obtained from the pre-trained transformer )
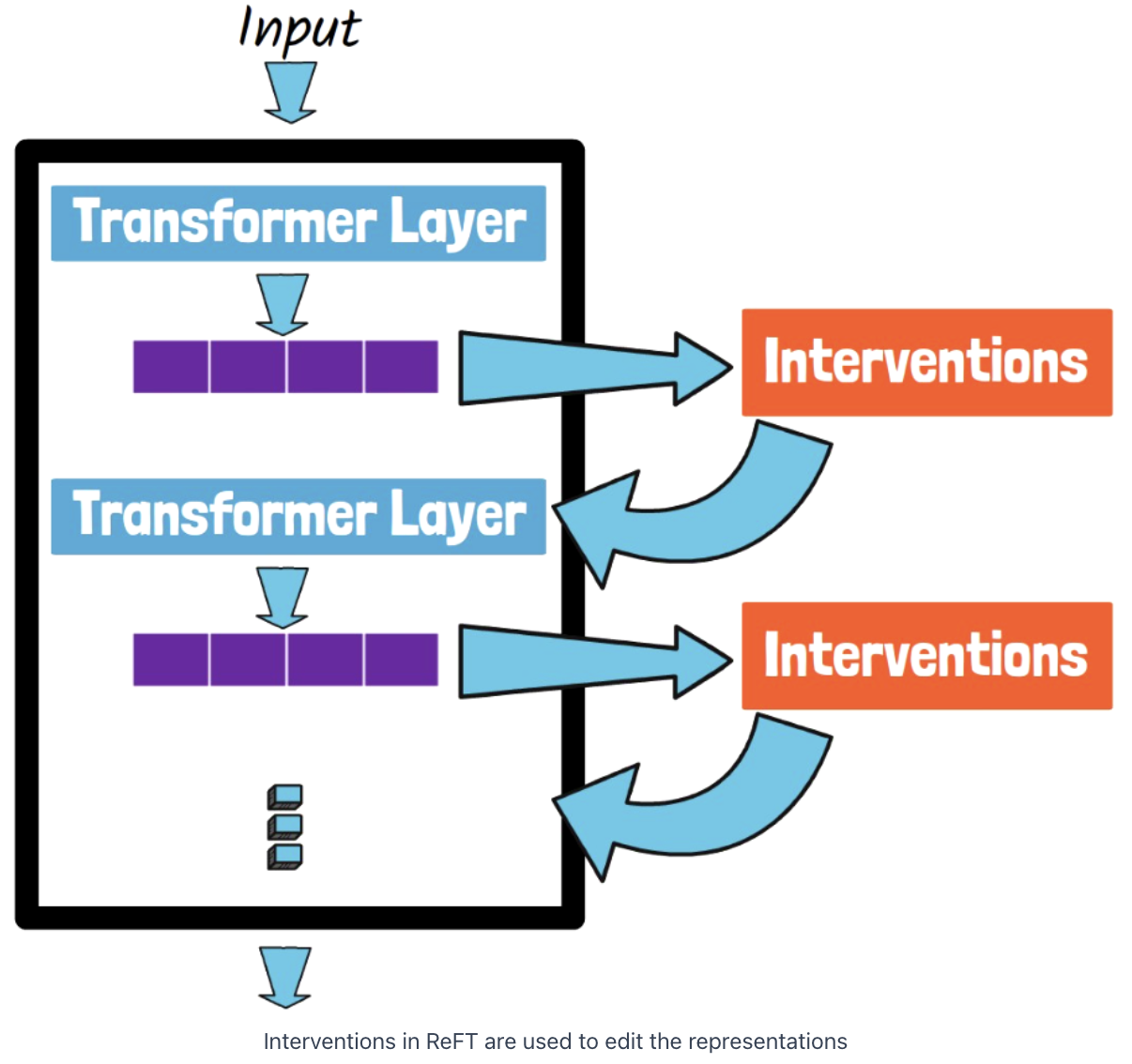
(2) Idea of ReFT
Why not directly edit the representaiton?
\(\rightarrow\) via Intervention
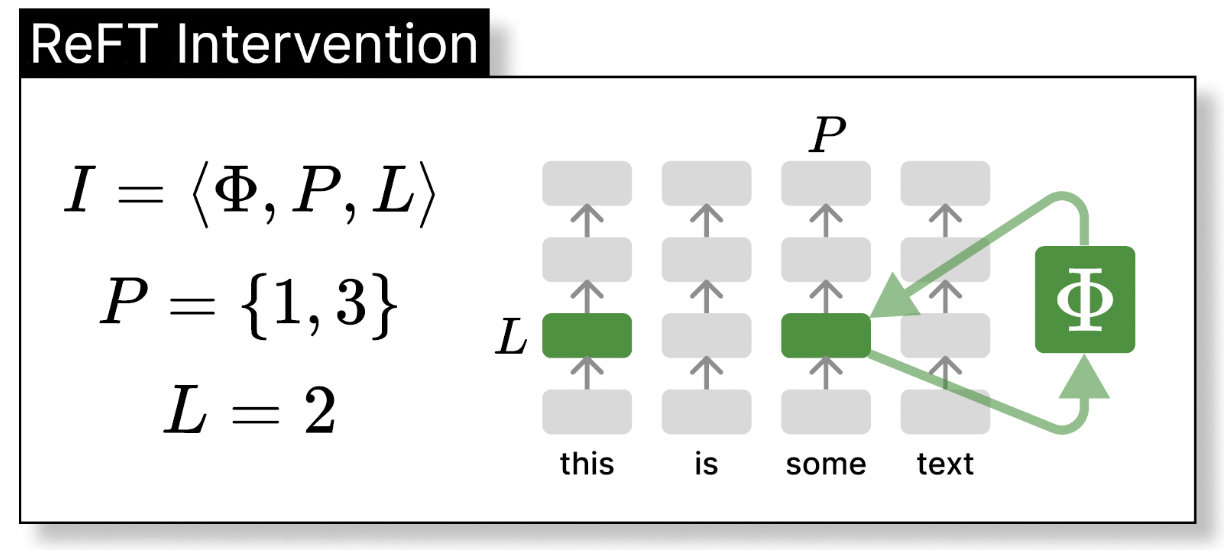
(3) LoReFT
\(\Phi_{\text {LoReFT }}(\mathbf{h})=\mathbf{h}+\mathbf{R}^{\top}(\mathbf{W h}+\mathbf{b}-\mathbf{R h})\).
- Learnable weights: \(\mathbf{W}, \mathbf{b}, \mathbf{R}\)
Examples)
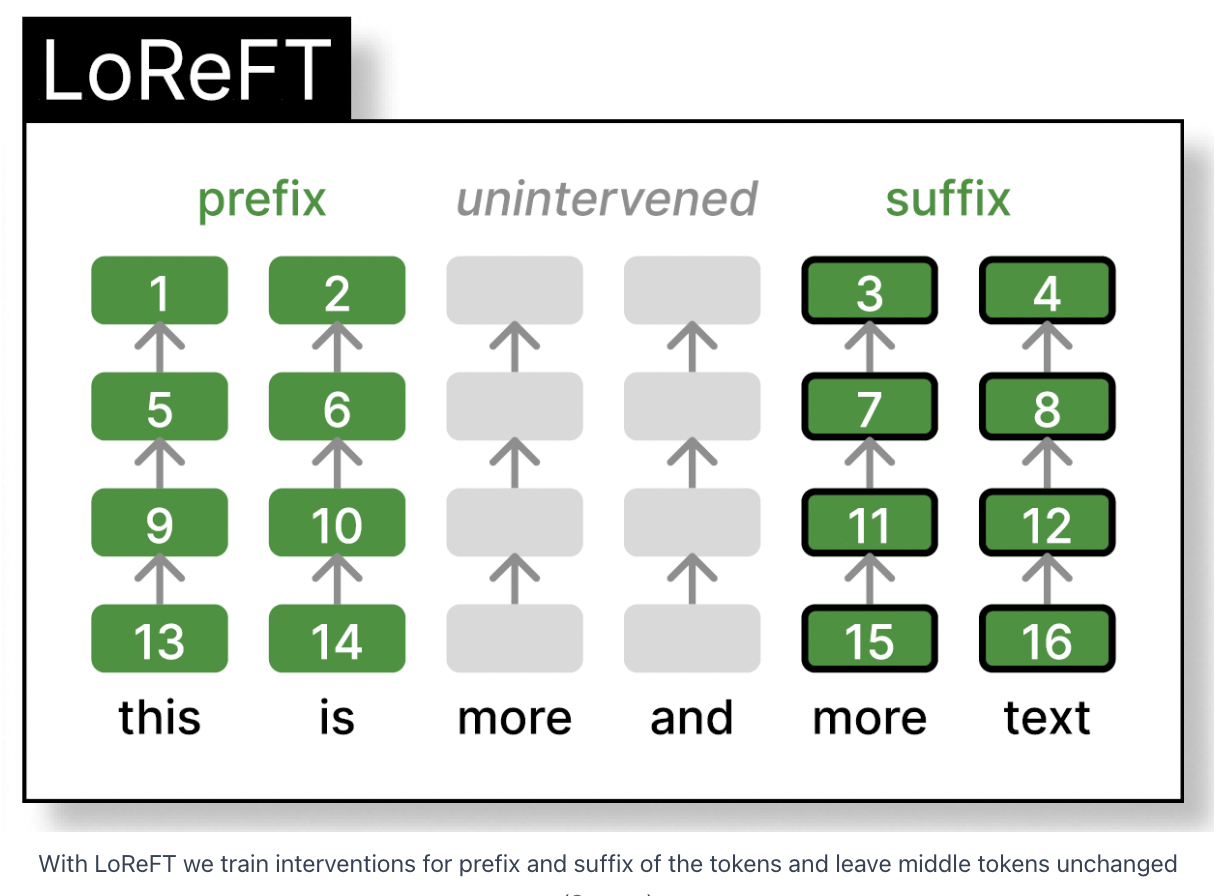
- Train interventions for prefix and suffix of the tokens
- Exact size of prefix and suffix are hyperparameters
- Intervention parameters:
- Either shared or not shared between different tokens of the same layer
- Different between the different layers
3. Experiments
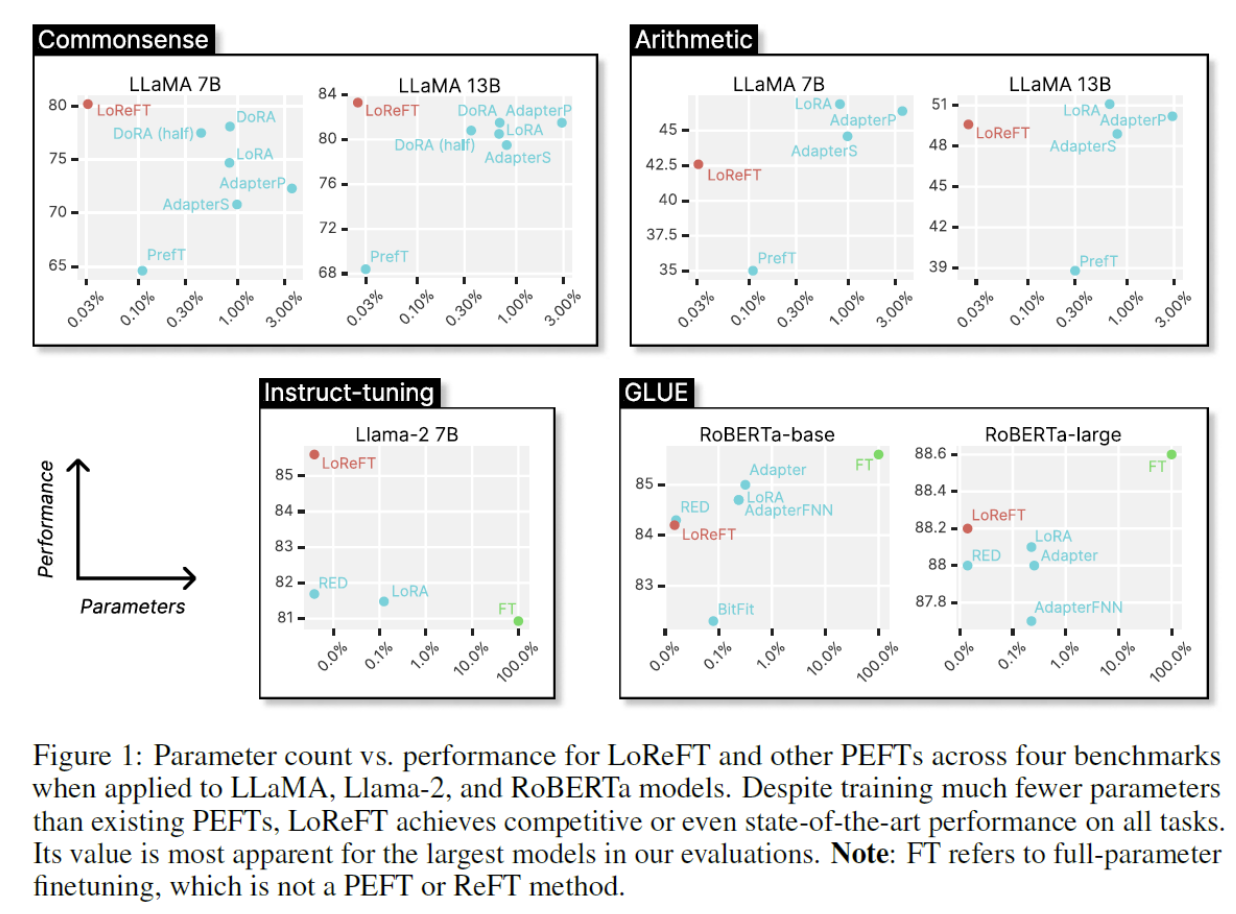
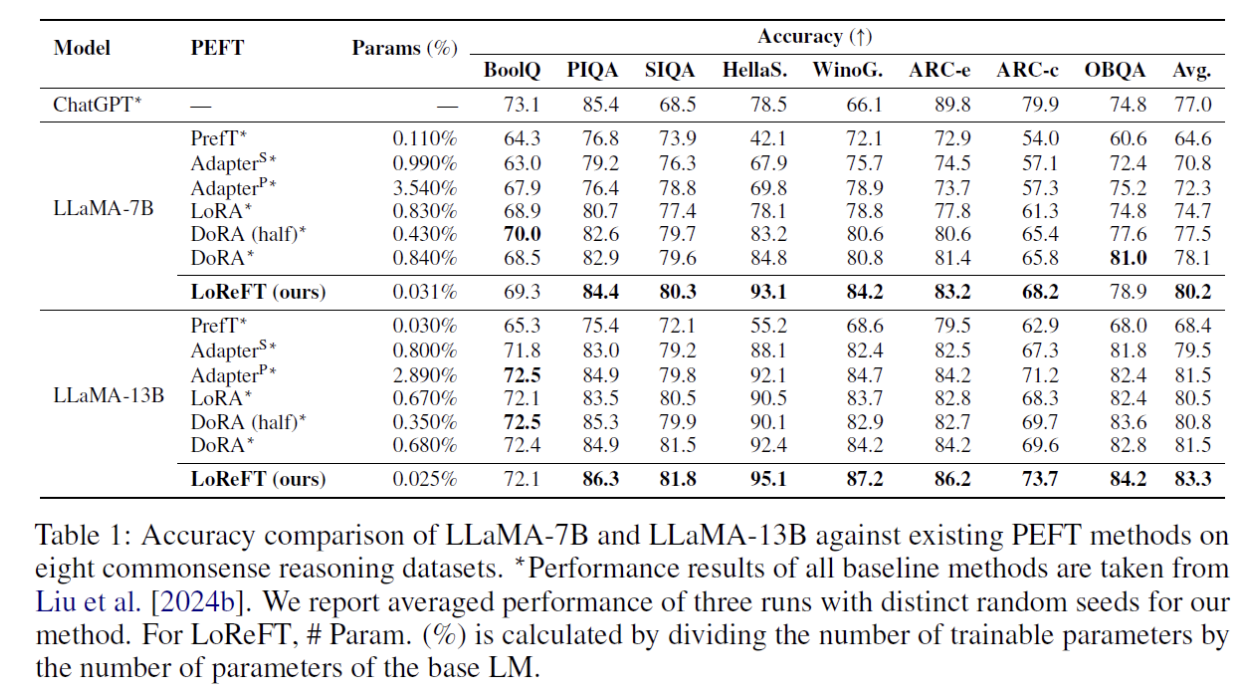
(1) Common sense Reasoning
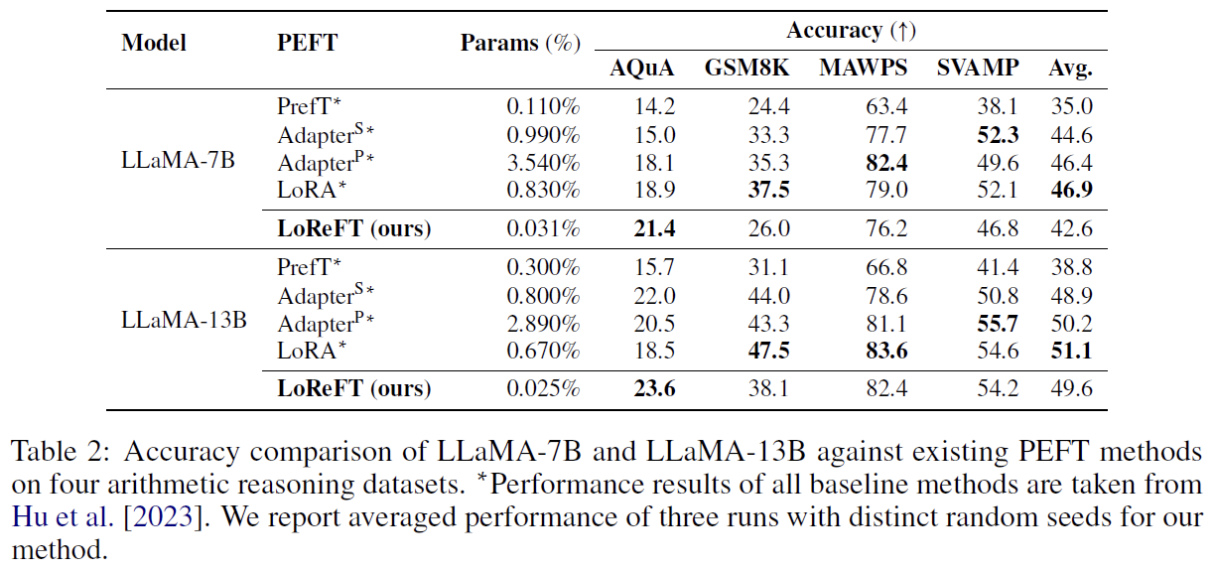
(2) Arithmetic Reasoning
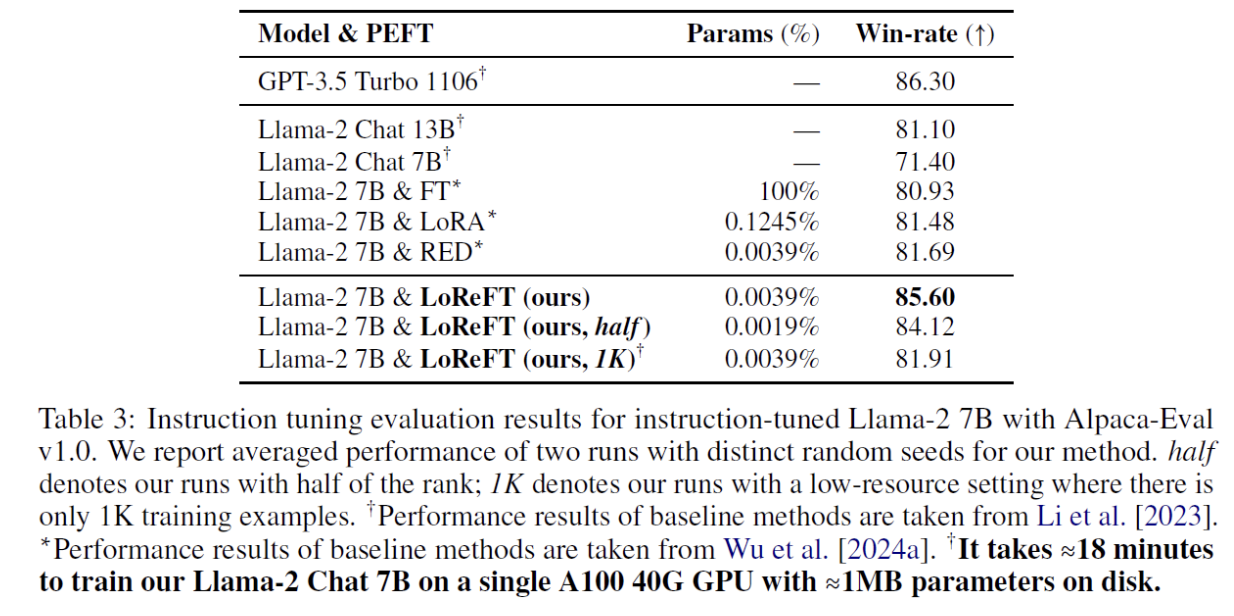
(3) Instruction Following