
Self-Rewarding Language Models
Yuan, Weizhe, et al. "Self-rewarding language models." ICML 2024
참고:
- https://aipapersacademy.com/self-rewarding-language-models/
- https://arxiv.org/pdf/2401.10020
Contents
- Motivation
- Background
- RLHF & RLAIF
- DPO
- Self-Rewarding Language Models
- Key Idea
- Datasets for Training Self-rewarding LLMs
- Improving the Model Iteratively
- Experiments
1. Motivation
Pre-trained LLMs
- Improved by getting feedback about the model output from humans
- Then, train on that feedback!
This paper
- In order to reach superhuman agents, future models require superhuman feedback!
Previous works
There are already methods that use LLMs to be the ones the provide the feedback
- e.g, RLAIF (Reinforcement Learning from AI Feedback)
Then, what’s novel with this work?
\(\rightarrow\) The model providing the feedback for the model outputs is actually the SAME model!
2. Background
Previous works
-
Reinforcement learning from human feedback (RLHF)
-
Reinforcement learning from AI feedback (RLAIF)
(1) RLHF & RLAIF
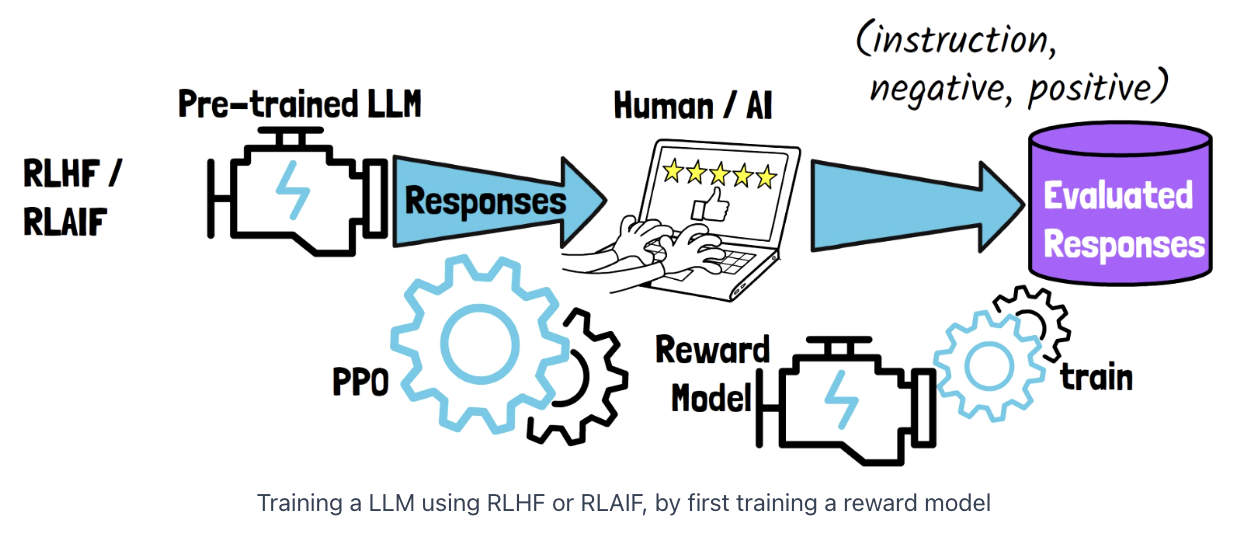
Procedure
-
Step 1) Pre-trained LLMs: Generate responses
-
Step 2) **Responses are evaluated **by human/AI (RLHF, RLAIF)
\(\rightarrow\) Produce a dataset of “evaluated responses”
- Step 3) Train a reward model based on that data
- A model that learns to rank the LLM responses
- Step 4) LLM is trained using the reward model
- Mostly via PPO (to yield outputs with high ranking)
(2) DPO
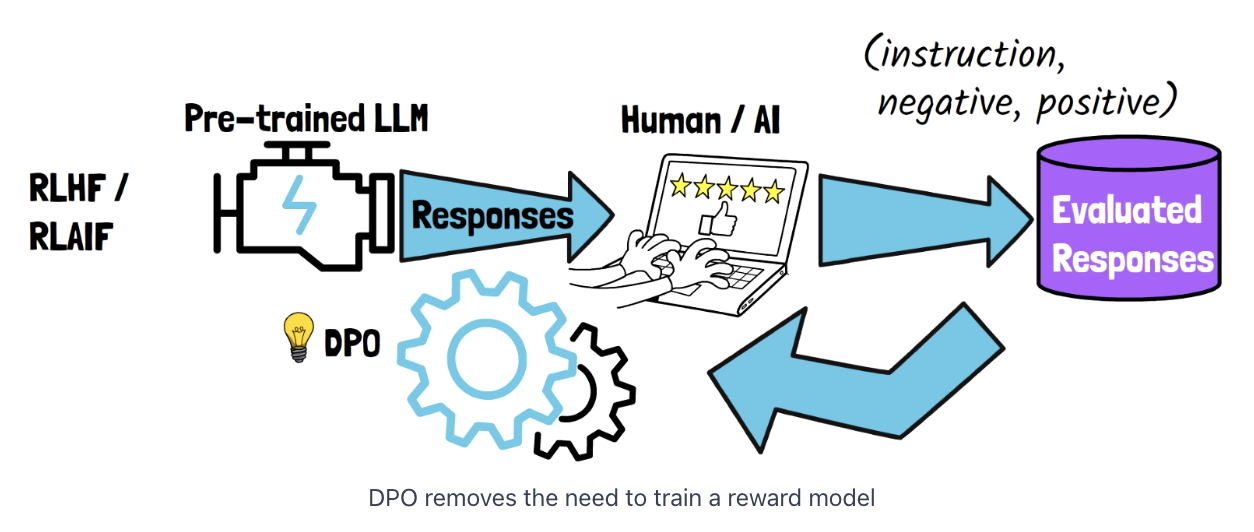
Direct Preference Optimization (DPO)
-
The need for the reward model is removed
\(\rightarrow\) Train the LLM using the feedback data directly (w/o reward model)
3. Self-Rewarding Language Models
(1) Key Idea
Self-rewarding LLM : should both learn to ..
- (1) Follow instructions
- (2) Act as a reward model
\(\rightarrow\) That is, the LLM is used to generate responses and their evaluations,
( Keeps on training on these evaluated responses iteratively )
(2) Datasets for Training Self-rewarding LLMs
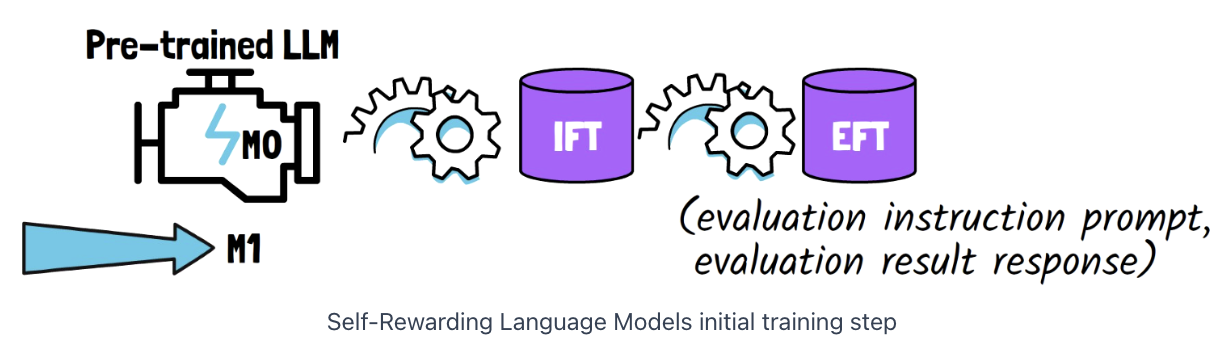
Start with..
- (1) Pre-trained LLM = \(M_0\)
- (2) Two initial small datasets = IFT + EFT
a) Instruction fine-tuning (IFT)
Instruction following dataset
- Crafted by humans
b) Evaluation fine-tuning (EFT)
Samples that have an …
- (1) Evaluation instruction prompt
- Prompt that asks the model to evaluate the quality of a given response to a particular instruction.
- (2) Evaluation result response
- Determines the score of the response, with reasoning for that decision.
\(\rightarrow\) Serves as training data for the LLM to fill the role of a reward model
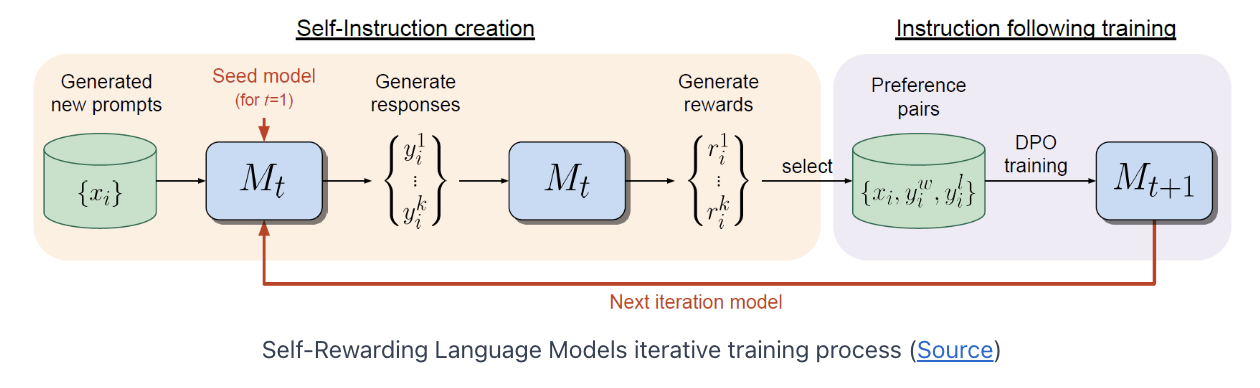
(3) Improving the Model Iteratively
Self-alignment process that consist of iterations
- Each iteration has two phases
4. Experiments
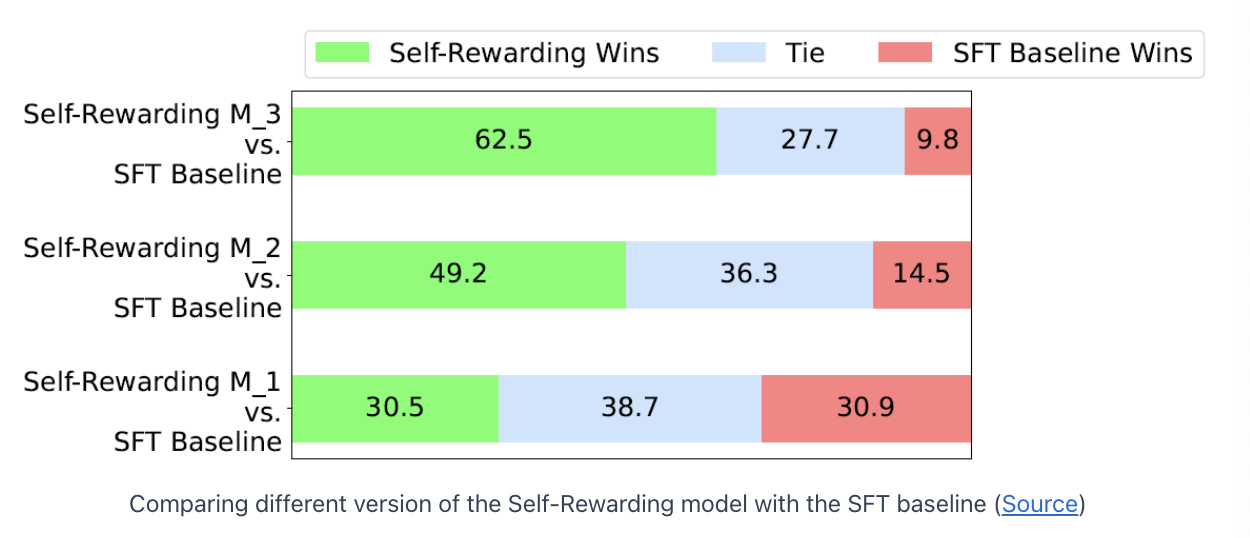

\(\rightarrow\) The more advanced versions win previous versions of the model!