Shepherd; A Critic for Language Model Generation
Wang, Tianlu, et al. "Shepherd: A critic for language model generation." arXiv preprint arXiv:2308.04592 (2023).
( https://arxiv.org/pdf/2308.04592 )
참고:
- https://aipapersacademy.com/shepherd-a-critic-for-language-model-generation/
Contents
- Refining LLM’s Output
- Shepherd Model
- Community Feedback
- Human-Annotated Feedback
- Experiments
1. Refining LLM’s Output
Motivation: LLM이 잘못된 정보를 말하면, refine할 수 있어야!
(i.e, new method to critique and refine models output )
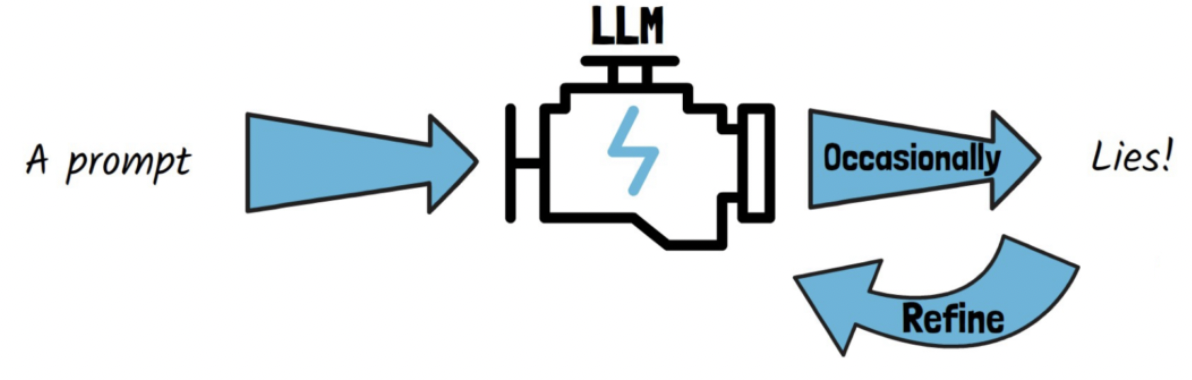
Example)

2. Shepherd Model
Shepherd Model은 어떠한 식으로 refine/critique를 하는가?
-
Model: LLaMa-7B
-
두 종류의 데이터셋에 대해 fine-tune
- (1) Community Feedback
- (2) Human-Annotated Feedback
(1) Community Feedback

Details
- Q&A data source
- 아래의 tuple을 구축한다 (Q,F,A)
- (Q) original question
- (A) top-level answer/comment
- (F) replies to the answer
- 유효한 tuple만을 남기기 위한 필터링
- 정답 & 오답 모두 의미있다!
- 정답 \(\rightarrow\) offer improvement
- 오답 \(\rightarrow\) highlight inaccuracies
- Step 1) Filter by keywords
- e.g., agree, indeed, wrong 등등
- Step 2) Filter by score
- 게시판에 달린 \(\uparrow\), 좋아요 수 등으로
- Step 3) Filter for diversity
- 1개의 포스트에 대해 1개의 샘플만!
- Step 4) Remove offensive content
- Step 5) Remove out of format samples
- e.g., Feedback이 추가적인 질문을 요구한다면
- 정답 & 오답 모두 의미있다!
(2) Human-Annotated Feedback

3. Experiments
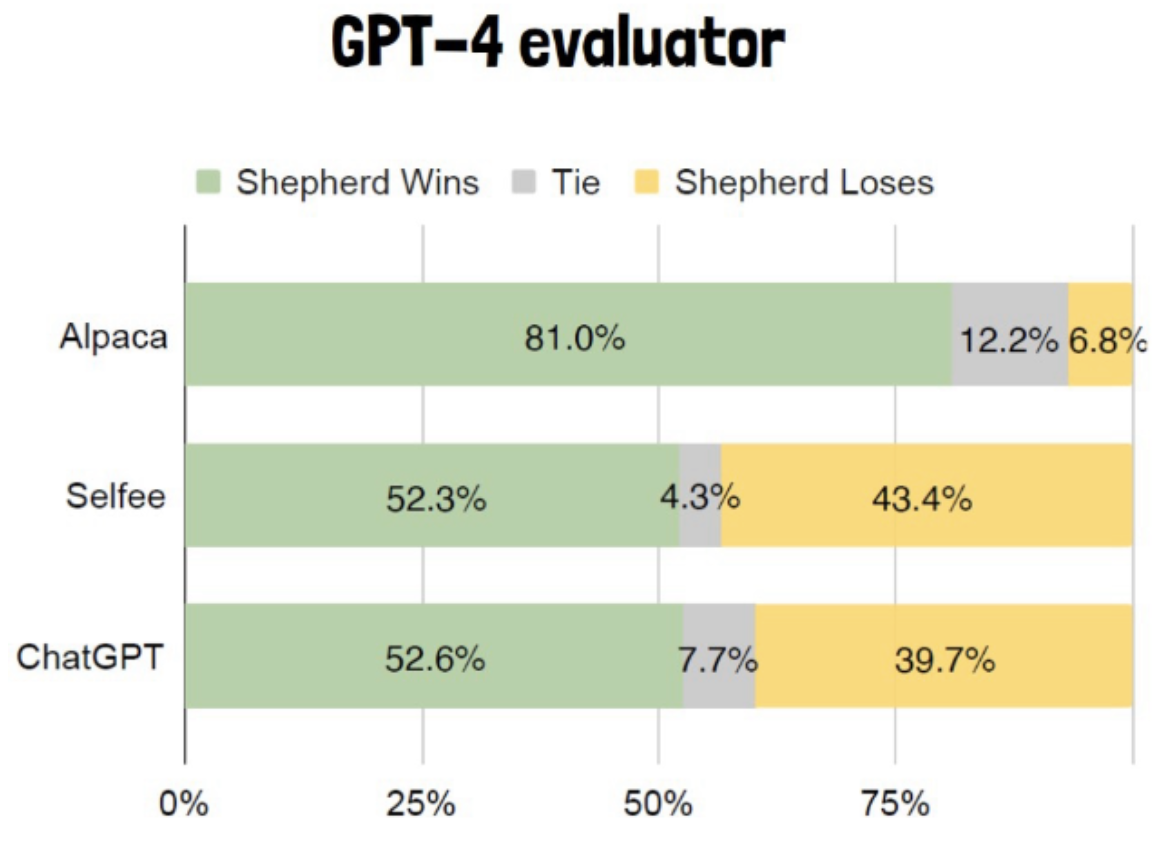
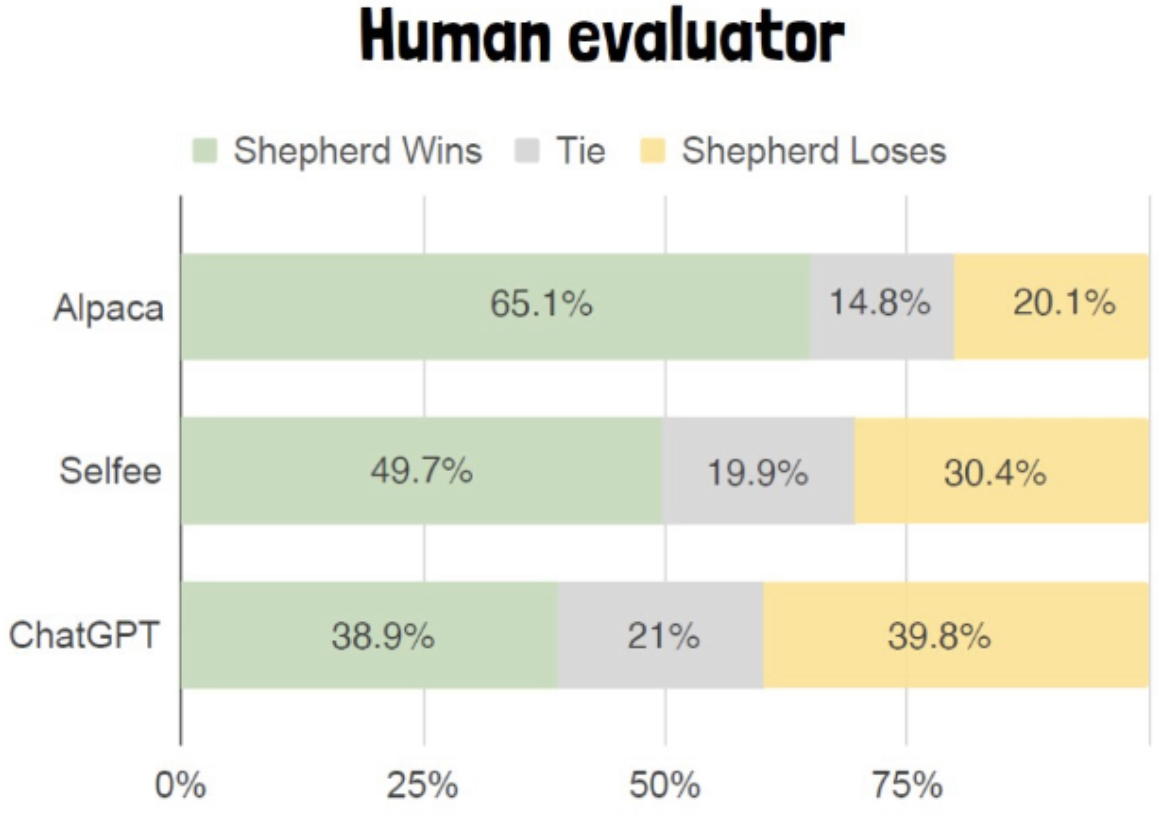
Evaluator: 내놓은 답들 중, 어느 답이 더 좋은지 평가하는 모델
(초록: Shepherd, 노랑:Alpaca)