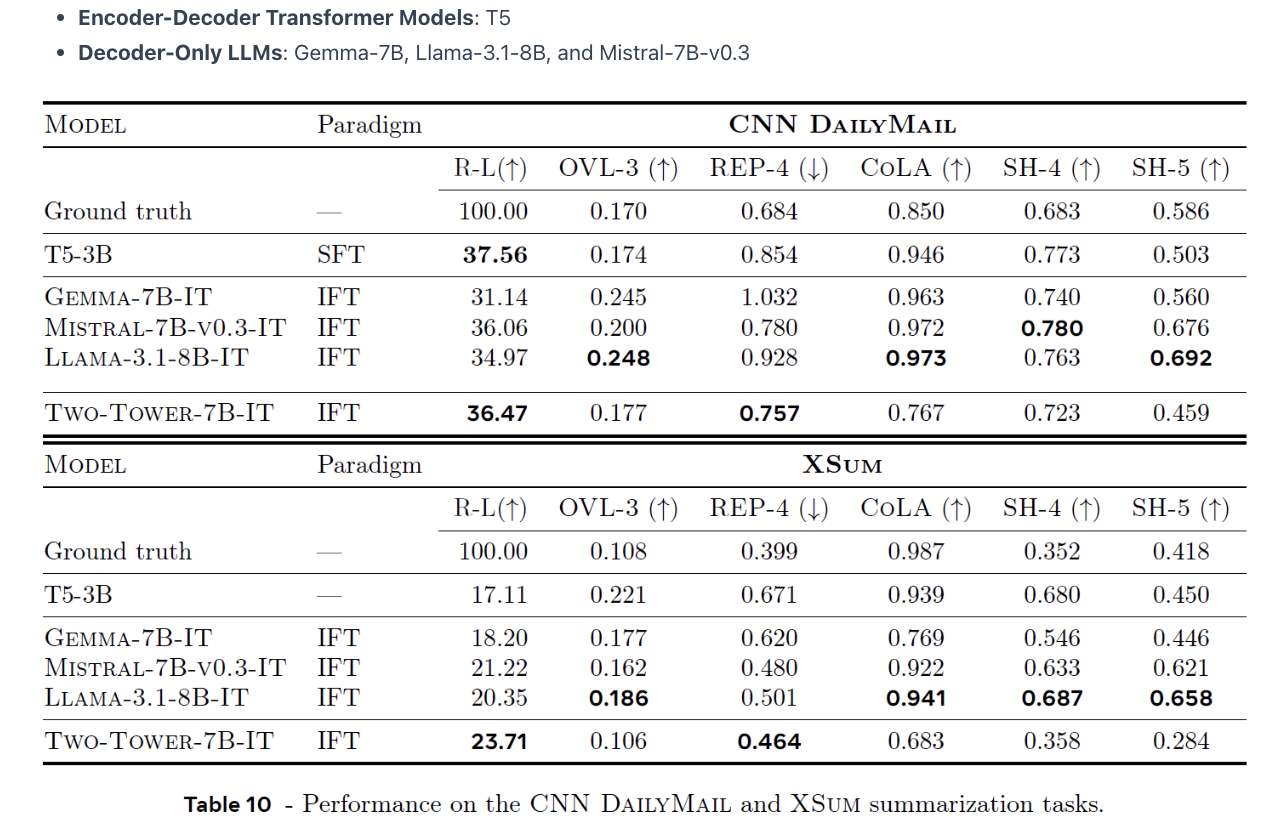
Large Concept Models: Language Modeling in a Sentence Representation Space
McLeish, Sean, et al. "Transformers Can Do Arithmetic with the Right Embeddings." NeurIPS 2024
참고:
- https://aipapersacademy.com/large-concept-models/
- https://arxiv.org/pdf/2412.08821
Contents
- Tokenizer
- Large Concept Models (LCMs)
- LLM vs. LCMs
- Tokens vs. Concepts
- Example of Concept-Based Reasoning
- High-level Architecture of LCMs
- Concept Encoder (SONAR)
- Large Concept Model (LCM)
- Concept Decoder (SONAR)
- Others
- Inner Architecture of LCMs
- Base-LCM: LCM Naive Architecture
- Diffusion-based LCM: Improved LCM
- Experiments
1. Tokenizer
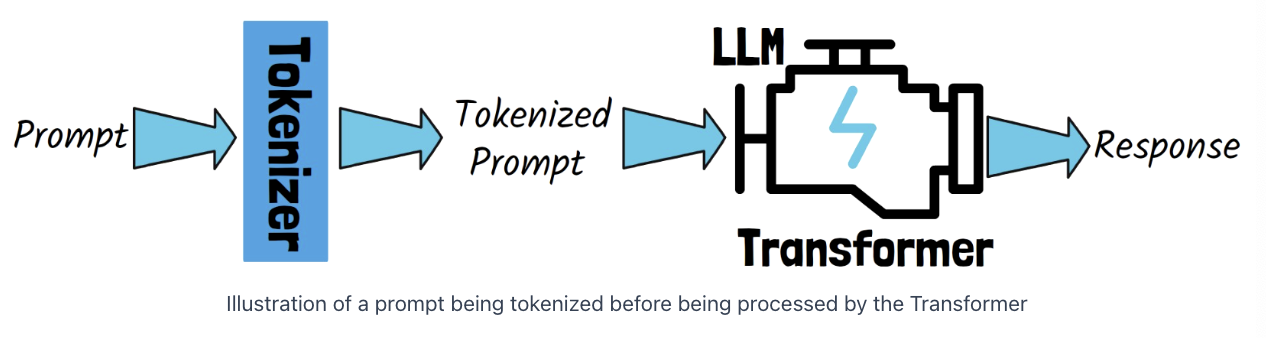
Transformer = Main component of LLM
Another crucial componen? Tokenizer
\(\rightarrow\) Converts the prompt into tokens!!
Example

-
Mostly assign one token per word
( except for the word “tokenization” )
-
LLM = processes this tokenized input
However, this method differs significantly from how humans analyze information and generate creative content
( \(\because\) Humans operate at multiple levels of abstraction, far beyond individual words )
2. Large Concept Models (LCMs)
(1) LLM vs. LCMs
-
(Traditional) LLMs: Process tokens
-
LCMs: Process concepts
(2) Tokens vs. Concepts
Concepts = Semantics of higher-level ideas or actions
\(\rightarrow\) Not tied to specific single words
- Ex) Same content, but with different languages! Even different modalities! (voice, action..)
Then, why process in concepts?
-
(1) Better Long Context Handling
-
\(\because\) Concept sequence is much shorter than the token sequence for the same input!
\(\rightarrow\) Significantly reduces the challenge of managing long sequences
-
-
(2) Hierarchical Reasoning
-
Processing concepts (rather than subword tokens) allows for better hierarchical reasoning.
-
Example) 15 minute talk
-
(X) Detailed speech by writing out every single word!
-
(O) Outline a flow of higher-level ideas
( + May be spokein in different languages, but higher-level abstract ideas will remain same! )
-
-
(3) Example of Concept-Based Reasoning
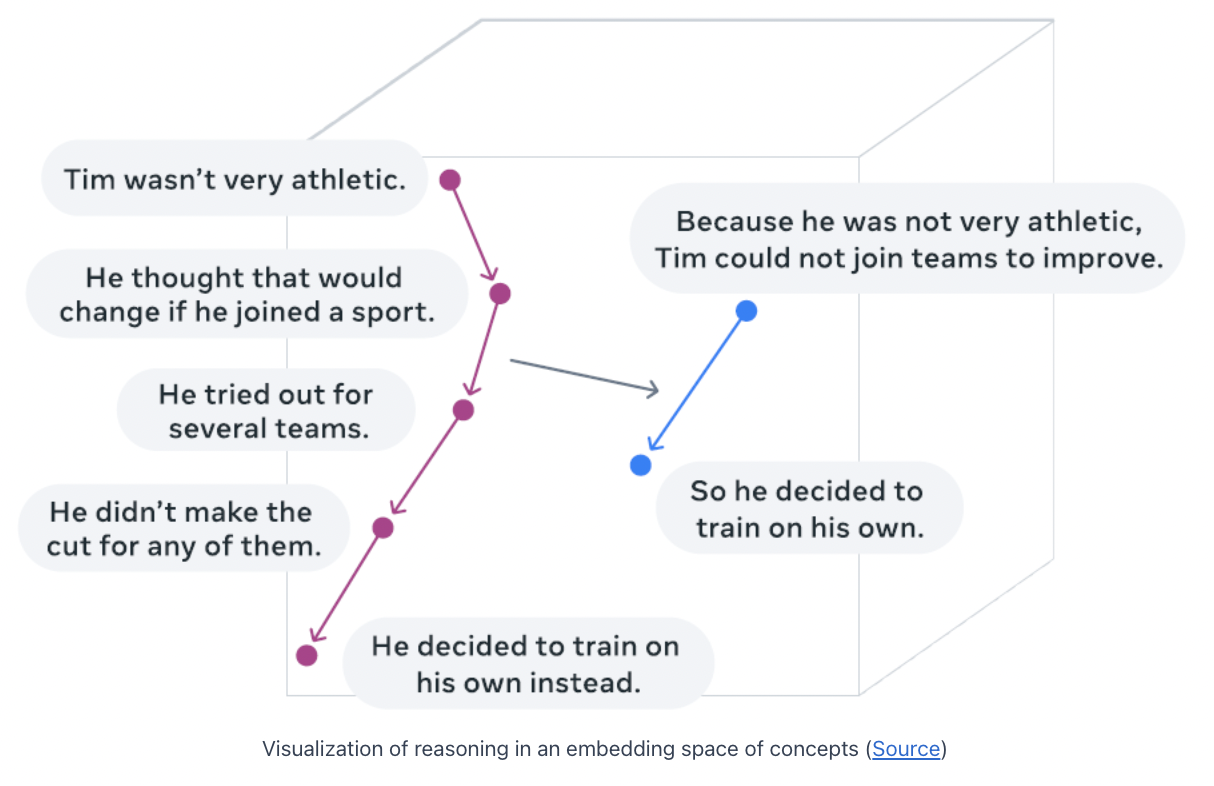
Reasoning in an embedding space of concepts for a summarization task
-
(Left) Embeddings of 5 sentences ( = concepts )
-
(Right) 2 concept representations
The concepts are mapped into two other concept representations ( = summary )
3. High-level Architecture of LCMs
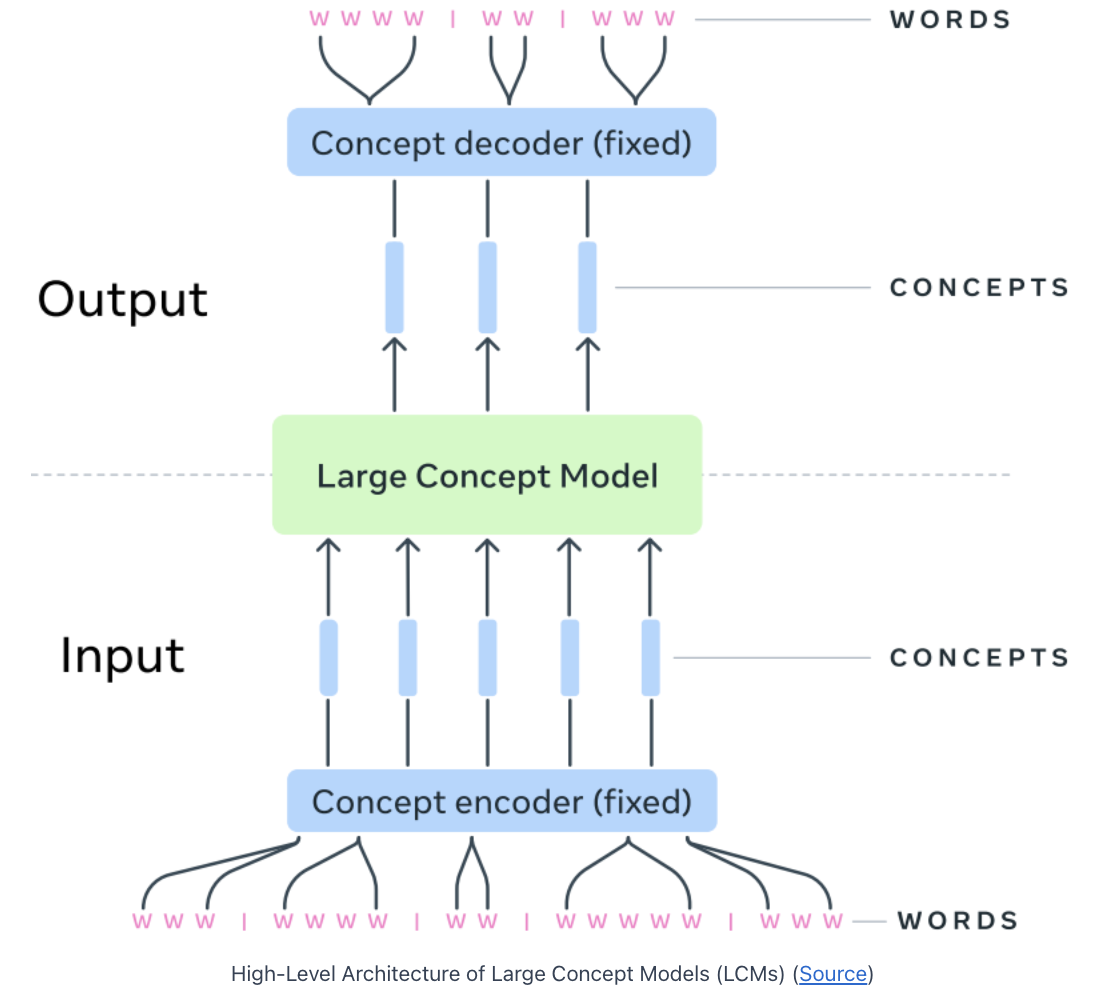
Begins with an input sequence of words divided into sentences
( = Basic building blocks representing concepts )
(1) Concept Encoder (SONAR)
-
Input) Sentences
-
Encoder) SONAR
-
Supports 200 languages as text input and output
( & 76 languages as speech input )
-
-
Output) Concept embeddings
(2) Large Concept Model (LCM)
-
Input) Concept embeddings
-
Encoder) Large Concept Model
-
Generate a new sequence of concepts at the output.
-
Operates solely in the embedding space
\(\rightarrow\) Independent of any specific language or modality.
-
(3) Concept Decoder (SONAR)
- Input) Concept Embeddings
- Decoder) SONAR
- Decoded back into language
- Can convert the output of the LCM into…
- more than one language
- more than one modality
(4) Others
Hierarchical structure
- Hierarchical structure is explicit in the architecture
- Extracting concepts
- Reasoning based on these concepts
- Generating the output
Resembles JEPA
- Concept of predicting information in an abstract representation (latent) space is not NEW!
- Joint Embedding Predictive Architecture (JEPA)
4. Inner Architecture of LCMs
(1) Base-LCM = First attempt of LCM
(2) Diffusion-based LCMs = Improved LCM architecture.
(1) Base-LCM: LCM Naive Architecture
a) LLM vs. LCM
-
LLM: next TOKEN prediction
-
LCM: next CONCEPT prediction,
\(\rightarrow\) Within the concepts embedding space
b) Next Concept Prediction (NCP)
- Input: Sequence (excluding the last concept)
-
Output: Prediction of the last (next) concept
- Loss (MSE): Actual next concept vs. Predicted concept
c) Components
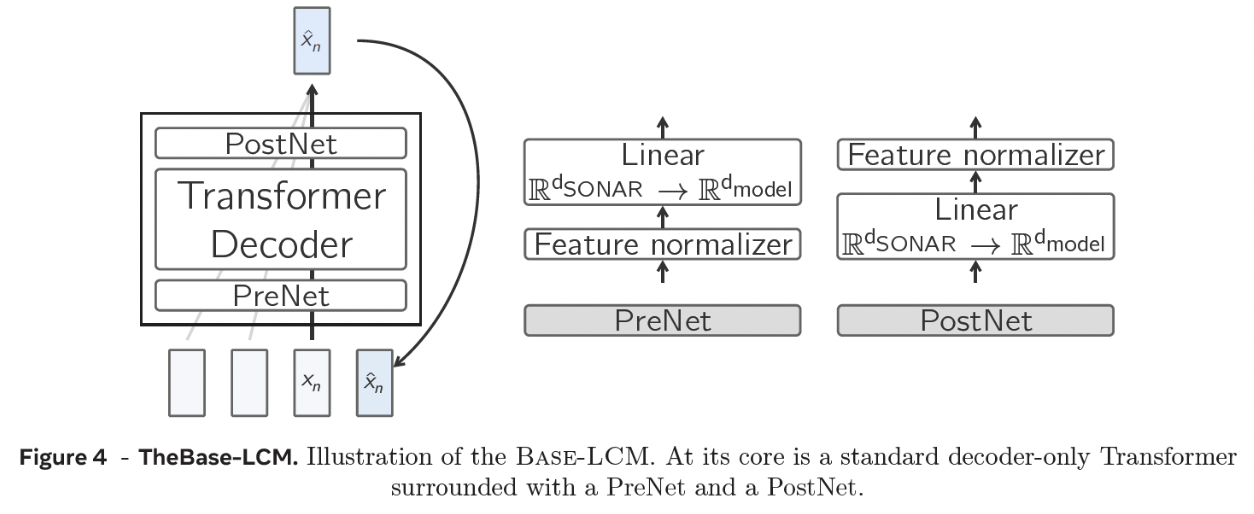
(1) PreNet:
- 1-1) Normalizes the concept embeddings (received from SONAR)
- 1-2) Maps them into the Transformer’s dimension
(2) PostNet:
- 2-1) Projects the model output back to SONAR’s dimension.
d) Limitation
Base-LCM: Trained to output a very specific concept.
\(\rightarrow\) However, there are likely many other concepts that could make sense in a given context.
Ex)
- Concept 1) I am very hungry!
- Concept 2)
- 2-1) What should I eat now?
- 2-2) But I should wait for 2 hours.
\(\rightarrow\) Next version of LCM architecture!
(2) Diffusion-Based LCM: Improved LCM
a) Diffusion model
Image generation model
-
Prompt: Generate a cute cat!
-
Results: There could be various images!
\(\rightarrow\) Inspired by this, diffusion-based architecture is also explored for LCMs

b) Components
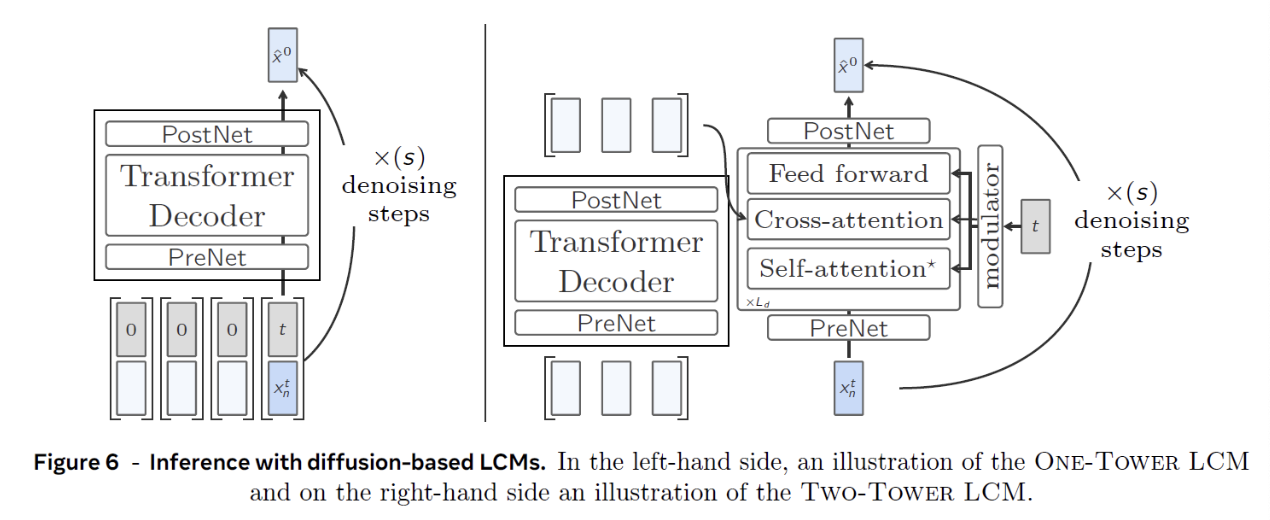
One-Tower LCM
-
(Bottom) Input sequence of concepts
( + Number representing the noisening timestamp )
-
Zero (0) = Clean concepts (w/o noise)
-
Only the last concept is noisy (\(t\))
\(\rightarrow\) Needs to be cleaned to get the clean next concept prediction
-
-
Similar to Base-LCM, but differes in that it runs multiple times
Two-Tower LCM
-
Main difference from the One-Tower version?
\(\rightarrow\) Separates the (a) encoding (of the preceding context) from the (b) diffusion (of the next concept embedding)
-
(a) Clean concept embeddings
- Decoder-only Transformer.
-
(b) Denoiser
-
Outputs of (a) are fed to the denoiser
( + Also receives the noisy next concept )
- Iteratively denoises it to predict the clean next concept
- Consists of Transformer layers
- With a cross-attention block (to attend to the encoded previous concepts)
-
5. Experiments
Comparing Different Versions of LCMs
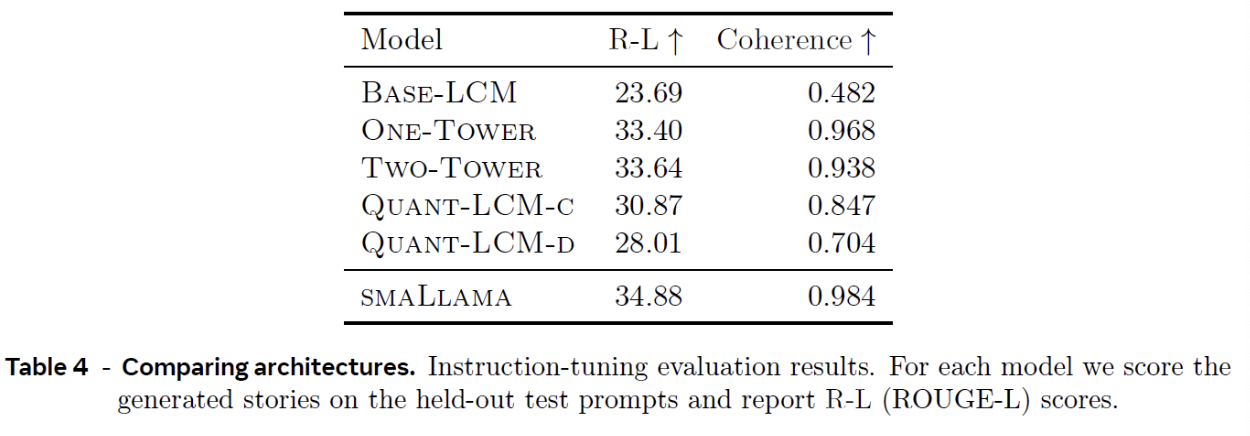
Higher Scale Evaluation of LCMs