LLaMA-Mesh: Unifying 3D Mesh Generation with Language Models
Wang, Zhengyi, et al. "LLaMA-Mesh: Unifying 3D Mesh Generation with Language Models." arXiv preprint arXiv:2411.09595 (2024).
참고:
- https://aipapersacademy.com/llama-mesh/
- https://arxiv.org/pdf/2411.09595
Contents
- Background
- Introduction
- LLaMA-Mesh (by NVIDIA)
- OBJ format
- Quantization
- Building LLaMA-Mesh
- Experiments
1. Background
Active research domain:
-
Try to harness LLM’s strong capabilities for other modalities
(e.g., understand images)
\(\rightarrow\) This paper: Generating 3D mesh with LLM!
2. Introduction
Llama-Mesh
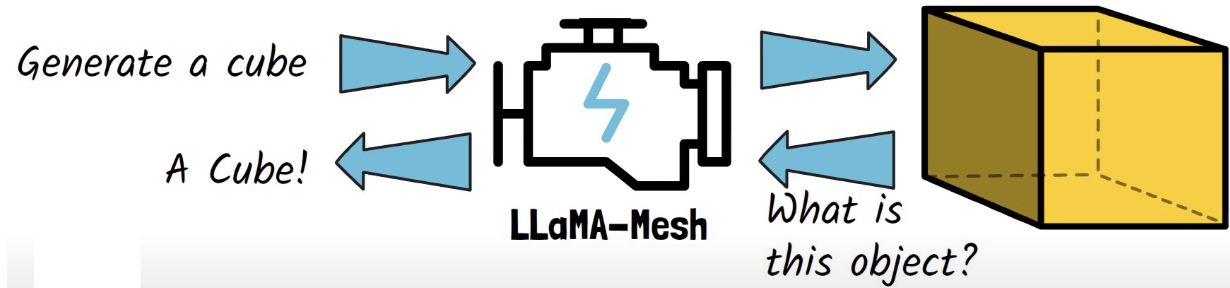
Transform a LLM into a 3D mesh expert!
\(\rightarrow\) By teaching it to understand and generate “3D mesh” objects
- Can generate a 3D mesh object
- Feed the LLM with a cube & recognize and say it is a cube
Demo: Nvidia’s blog
3. LLaMA-Mesh (by NVIDIA)
(1) OBJ format
How can LLM, trained on text, can understand & generate 3D object??
\(\rightarrow\) Format: OBJ ( = text-based standard for 3D objects )
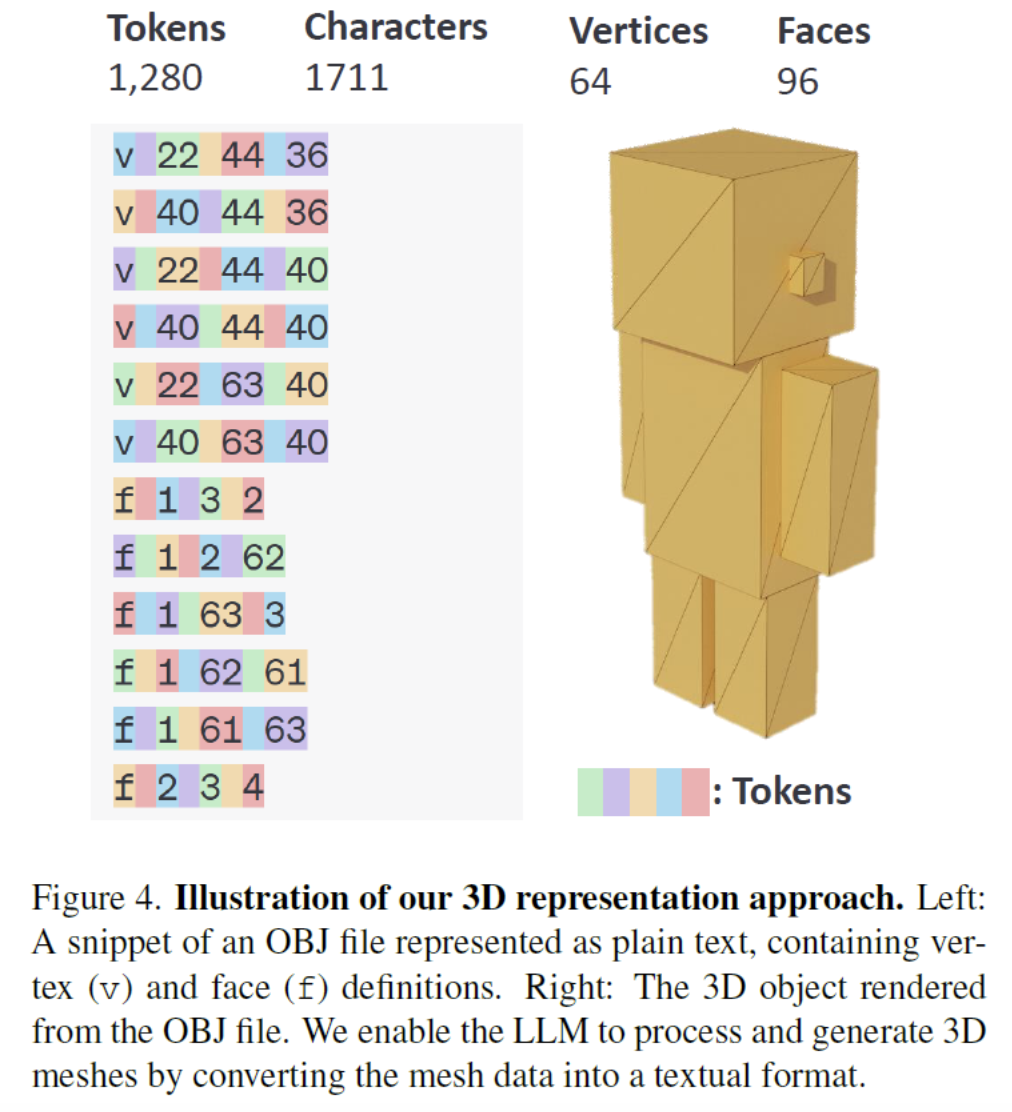
- “v” = vertices in the three-dimensional space
- With x, y, and z coordinates
- “f” = faces
- Specifying the list of vertices that make up a surface
\(\rightarrow\) Enable the LLM to read&generate this format!
(2) Quantization
Reduction of # tokens

(Original) Vertices’ coordinates are typically provided as decimal values
\(\rightarrow\) Convert these coordinates to integers. ( = Quantization process )
\(\rightarrow\) Trading off some precision for efficiency
(3) Building LLaMA-Mesh
Observation: Some spatial knowledge is already embedded in pretrained LLMs
- Possibly due to the inclusion of 3D tutorials in the pretraining data
\(\rightarrow\) Nonetheless, unsatisfactory results!
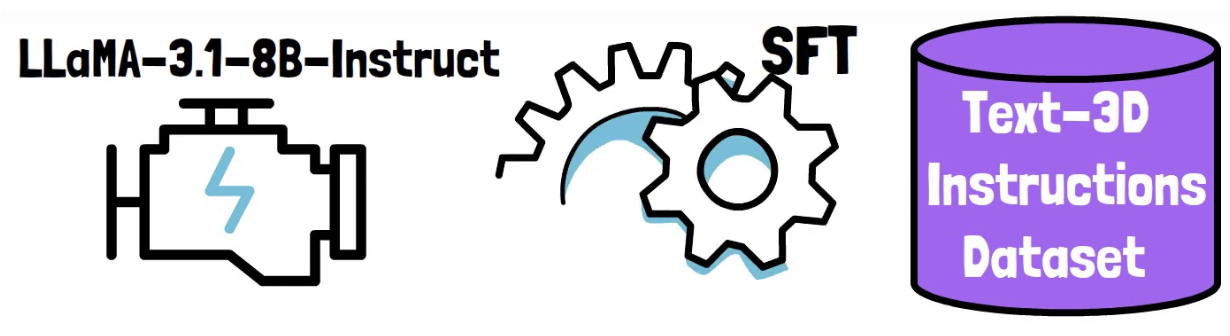
- Model: LLaMA-3.1-8B-Instruct
- Dataset: ??
\(\rightarrow\) Constructed a new dataset of text-3D instructions ( + supervised fine-tuning )
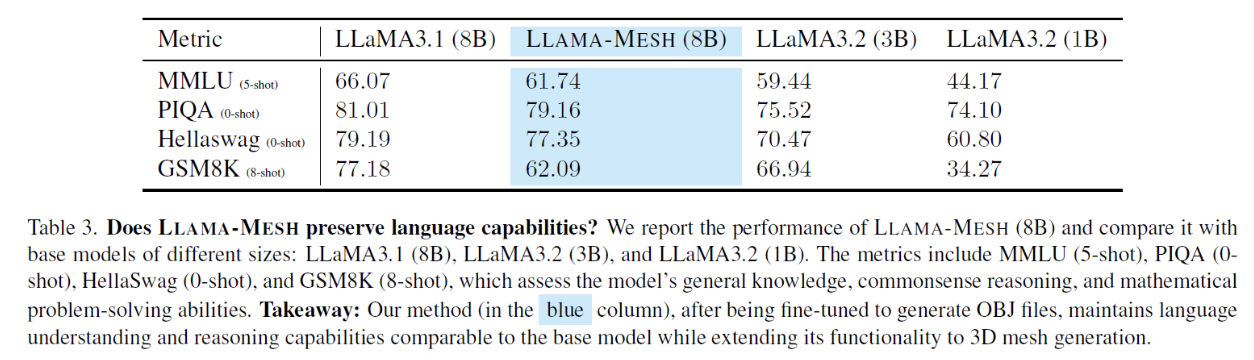
4. Experiments
(1) Examples of dataset

(2) Generation results

(3) Does LLaMA-Mesh Preserve Language Capabilities?