
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, Daya, et al. "Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning." arXiv preprint arXiv:2501.12948 (2025).
참고:
- https://aipapersacademy.com/deepseek-r1/
- https://arxiv.org/abs/2501.12948
Contents
- Introduction
- Recap: LLMs Training Process
- Pretraining
- Supervised Fine-tuning
- Reinforcement Learning (RL)
- DeepSeek-R1-zero
- Rule-based RL
- Experiments
- DeepSeek-R1
- Need for DeepSeek-R1
- Training Pipeline
- Experiments
1. Introduction
LLMs: Paved the way toward artificial general intelligence (AGI)
OpenAI-o1: Innovative inference-time scaling techniques
\(\rightarrow\) Significantly enhance reasoning capabilities (but closed source)
DeepSeek-R1
- (1) SOTA + Open-source reasoning model
- (2) Large-scale reinforcement learning techniques
2. Recap: LLMs Training Process
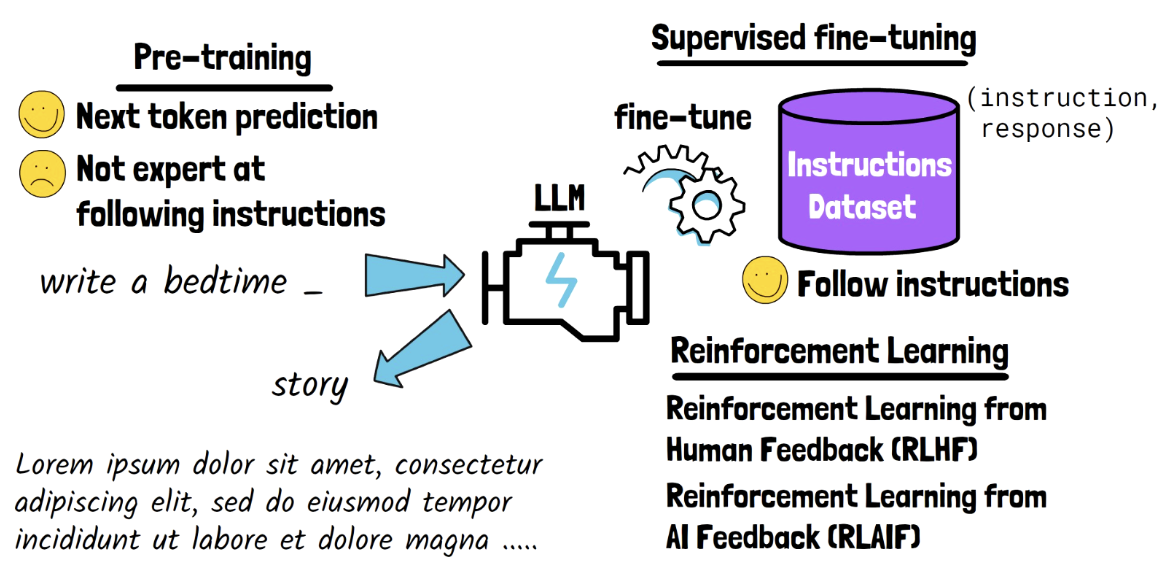
(1) Pre-training
-
Pre-trained on vast amounts of text and code
\(\rightarrow\) Learn general-purpose knowledge.
-
Task: Next token prediction (NSP)
-
However, with ONLY pre-training …
\(\rightarrow\) Struggles to follow human instructions!
$\rightarrow$ Necessity of SFT
(2) Supervised Fine-tuning
-
Fine-tuned on an instruction dataset
-
Instruction dataset
- Either made by human / (original) dataset / model ( =self-instruct)
- Consists of an instruction-response pair ( response = label )
\(\rightarrow\) Model becomes better at following instructions!
(3) Reinforcement Learning (RL)
- Further improved using feedback (feat. RL)
- Reinforcement Learning from Human Feedback (RLHF)
- Human provides the feeback
- But, gathering large-scale, high-quality human feedback, especially for complex tasks, is challenging! \(\rightarrow\) RLAIF
- Reinforcement Learning from AI Feedback (RLAIF)
- AI model provides the feedback
- With highly capable model (e.g., GPT4)
3. DeepSeek-R1-zero
(Partially) eliminates the step 2) SFT
DeepSeek-R1-Zero
-
Start with a pretrained model: DeepSeek-V3-Base (671 B params)
-
Stage 2) (X) No SFT stage
-
Stage 3) (O) Instead of using the standard RL (e.g., RLHF, RLAIF) …use rule-based RL!!
\(\rightarrow\) Group Relative Policy Optimization (GRPO)
(1) Rule-based RL
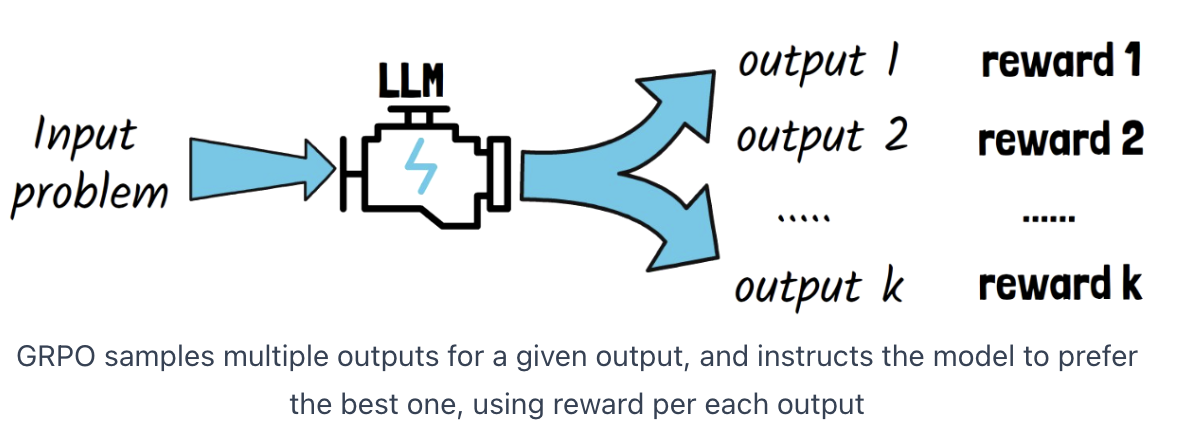
Group Relative Policy Optimization (GRPO)
Procedure
-
Step 1) Input is fed to model
-
Step 2) A group of multiple outputs is sampled
- Each output = (reasoning process, answer)
-
Step 3) GRPO method
-
Observes these sampled outputs
-
Trains the model to generate the preferred options
\(\rightarrow\) By calculating a reward for each output using predefined rules
-
Summary
-
Does not use a neural model to generate rewards
\(\rightarrow\) Simplifies and reduces the cost of the training process!
Predefined rules
-
Accuracy: (e.g., math problems, code problems with deterministic results)
- Can reliably check if the final answer provided by the model is correct.
-
Format:
-
Another type of rule creates format rewards.
-
How the model is instructed to respond, with …
- Reasoning process within <think> tags
- Answer within <answer> tags
\(\rightarrow\) Format reward ensures the model follows this formatting!
-

4. Experiments
(1) Performance Insights
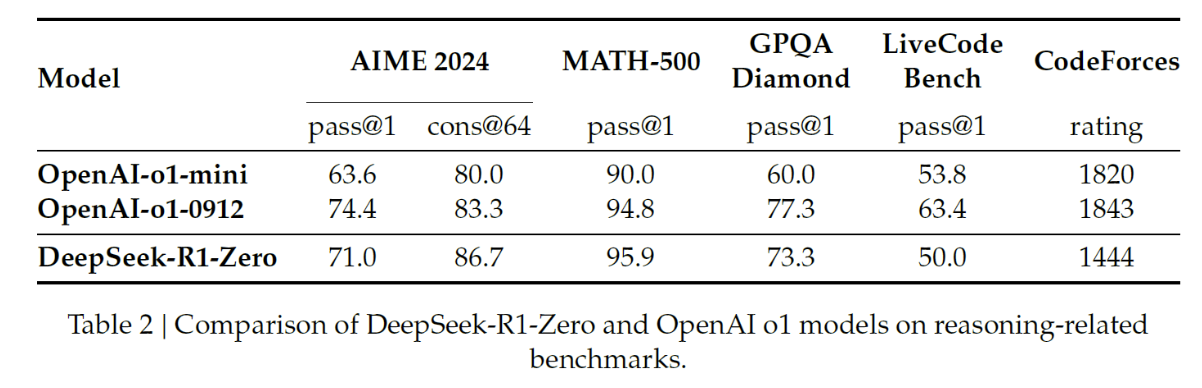
DeepSeek-R1-Zero
- Comparable to o1 and even surpasses it in some cases
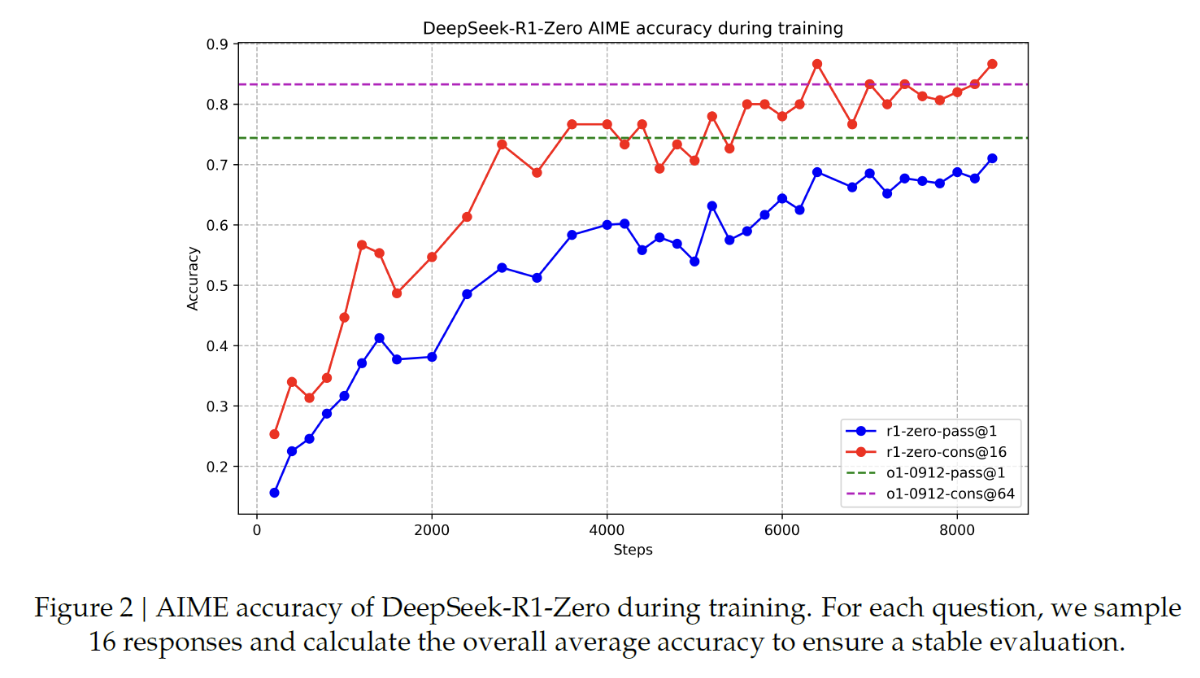
\(\rightarrow\) Improvement progress during training!!
(2) Self-Evolution Process of DeepSeek-R1-Zero
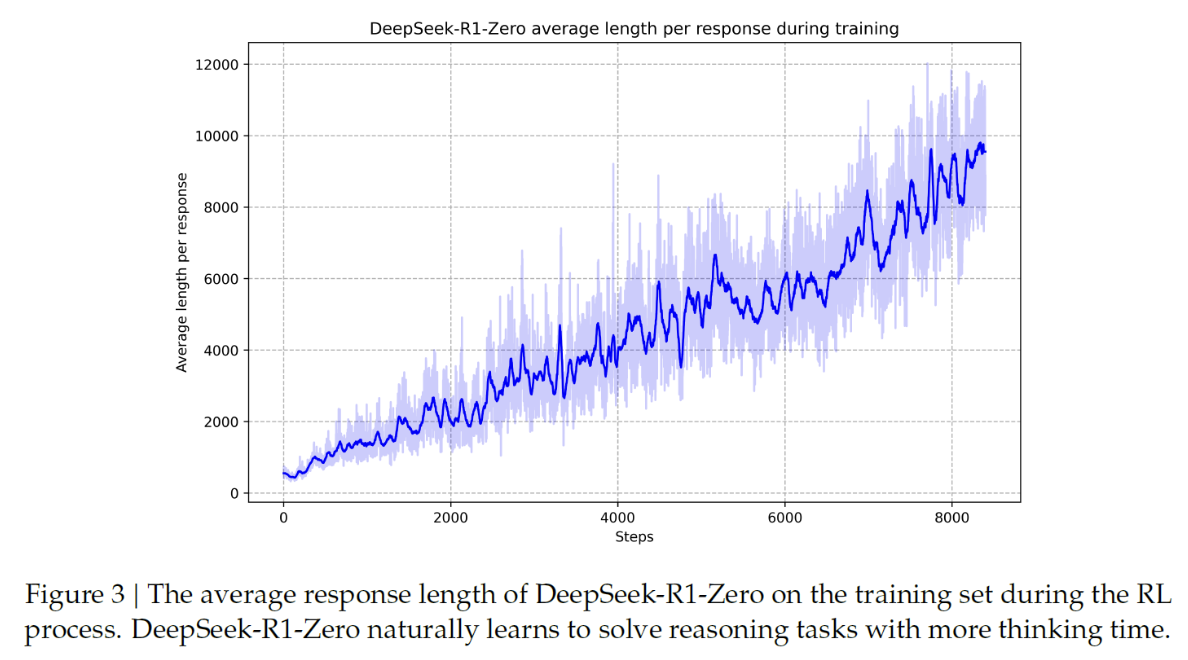
Self-evolution process of the model
\(\rightarrow\) Through RL, the model naturally learns to allocate more thinking time when solving reasoning tasks!
(3) Aha Moment
Given a math question, the model starts its reasoning process.
However, at a certain point, the model begins to reevaluate its solution!
\(\rightarrow\) Learns to reevaluate its initial approach & and correct itself if needed!

5. DeepSeek-R1
(1) Need for DeepSeek-R1
Why do we need a second model ( = DeepSeek-R1 ) ?
( given the remarkable capabilities of DeepSeek-R1-zero )
2 Reasons
- Readability Issues
- Language Consistency
- Frequently mixes languages within a single response
\(\rightarrow\) Makes DeepSeek-R1-Zero less user-friendly
Findings (ablation study)
-
Guiding the model to be consistent with ONE language slightly damages its performance
( \(\leftrightarrow\) Humans who usually stick to a single language )
(2) Training Pipeline
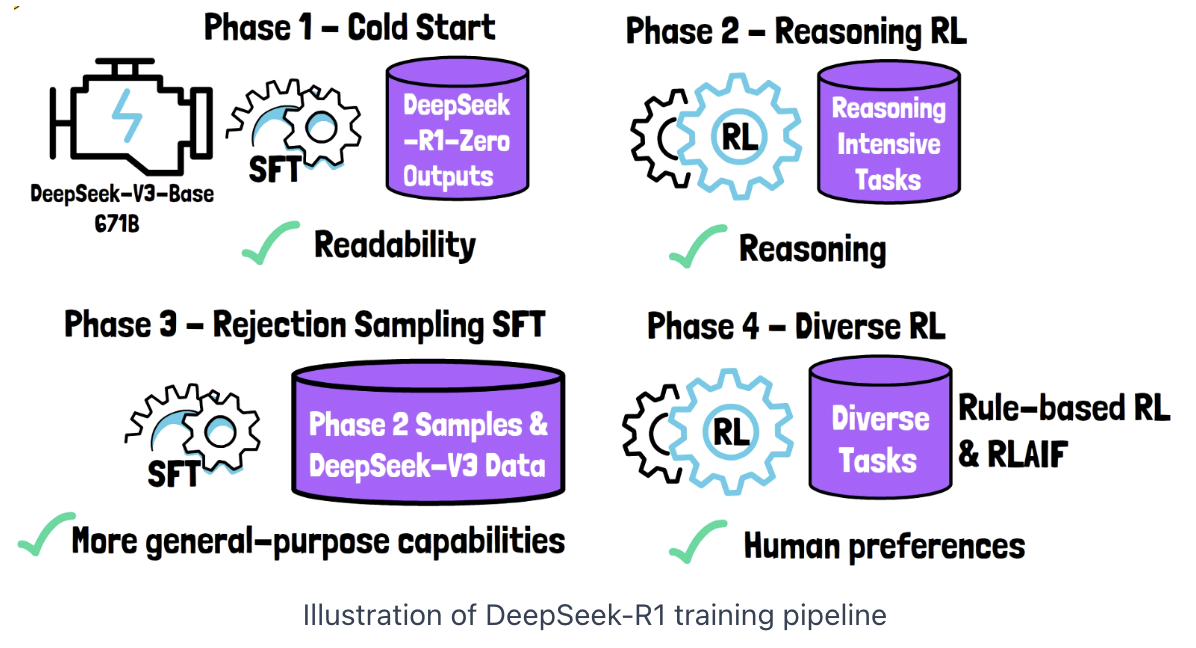
Phase 1) Cold Start
-
Start with (pre-trained model) DeepSeek-V3-Base
-
Supervised fine-tuning
- On a small dataset (thousands) of results (collected from DeepSeek-R1-Zero)
\(\rightarrow\) Results: High-quality and readable.
Phase 2) Reasoning Reinforcement Learning
- Same as DeepSeek-R1-Zero (Rule-based)
Phase 3) Rejection Sampling and SFT
-
Generate many samples
- From model checkpoint of phase 2
-
3-1) Rejection sampling
-
Only correct and readable samples are retained
( Generative reward model, DeepSeek-V3, decides the accept/reject )
-
Some of DeepSeek-V3’s training data is also included in this phase
-
-
3-2) SFT with above datasets
Phase 4) Diverse Reinforcement Learning Phase
- Tasks (such as math): Rule-based rewards
- Other tasks: LLM provides feedback to align the model with human preferences
5. Experiments
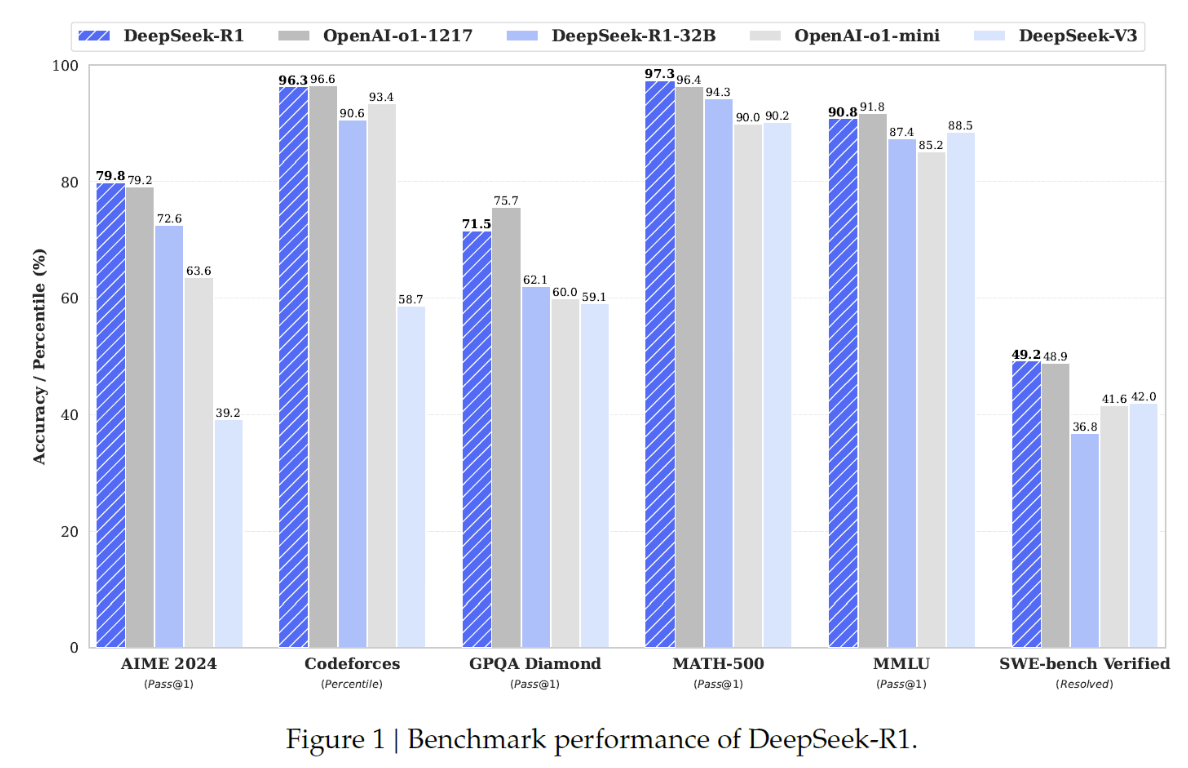
-
DeepSeek-R1-32B: 32 billion parameters distilled model
\(\rightarrow\) Making it a viable smaller alternative