LongNet: Scaling Transformers to 1,000,000,000 Tokens
Ding, Jiayu, et al. "Longnet: Scaling transformers to 1,000,000,000 tokens." arXiv preprint arXiv:2307.02486 (2023).
( https://arxiv.org/pdf/2307.02486 )
참고:
- https://aipapersacademy.com/longnet/
Contents
- Background
- Improving Attention Mechanism
- Standard Attention
- Dilated Attention
- Mixture of Dilated Attentions
- Multi-head Dilated Attention
1. Background
Modeling long sequences is crucial!
Limitation: High computational complexity
\(\rightarrow\) Difficult to scale up the context length.
2. Improving Attention Mechanism
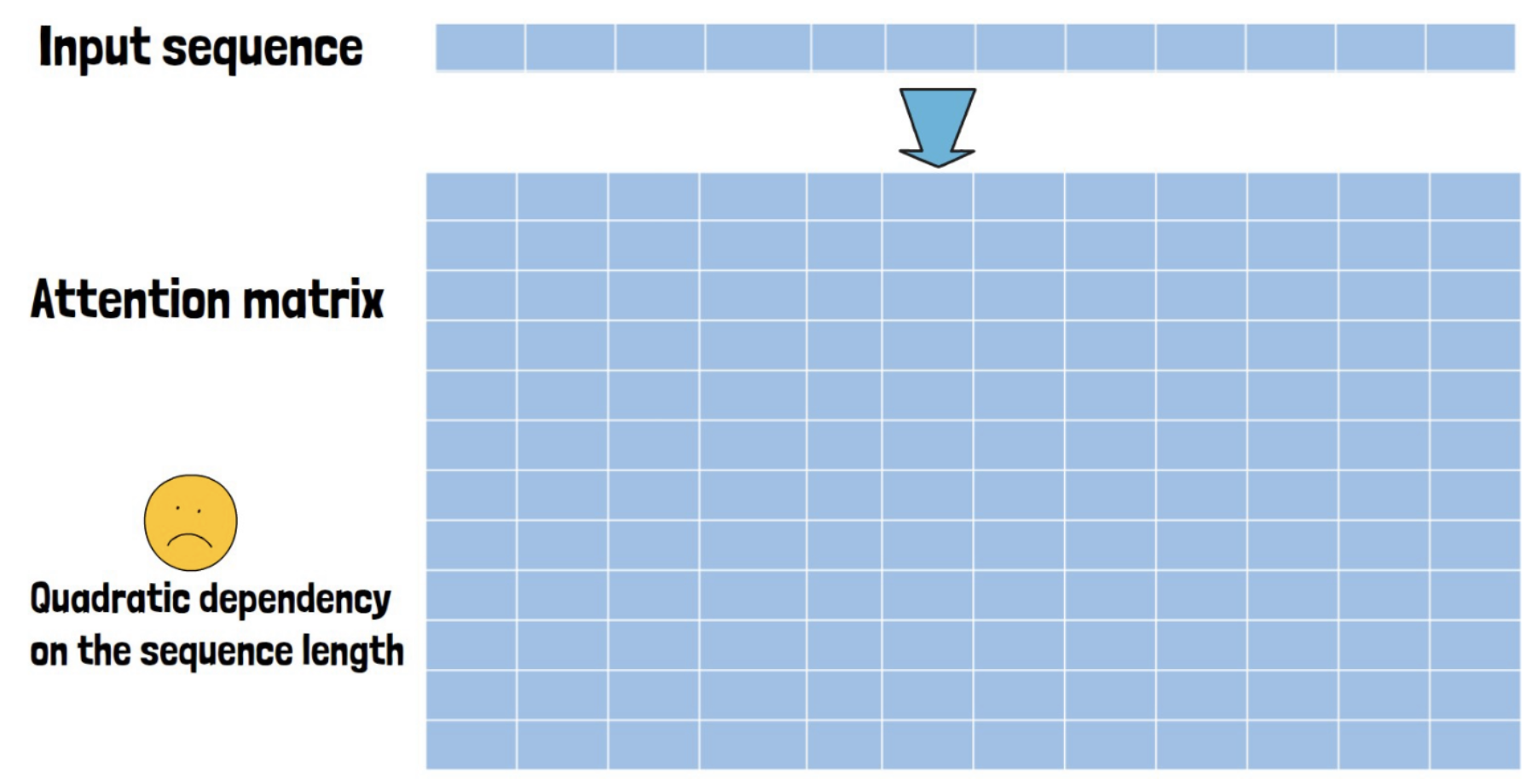
(1) Standard Attention
Quadratic dependency
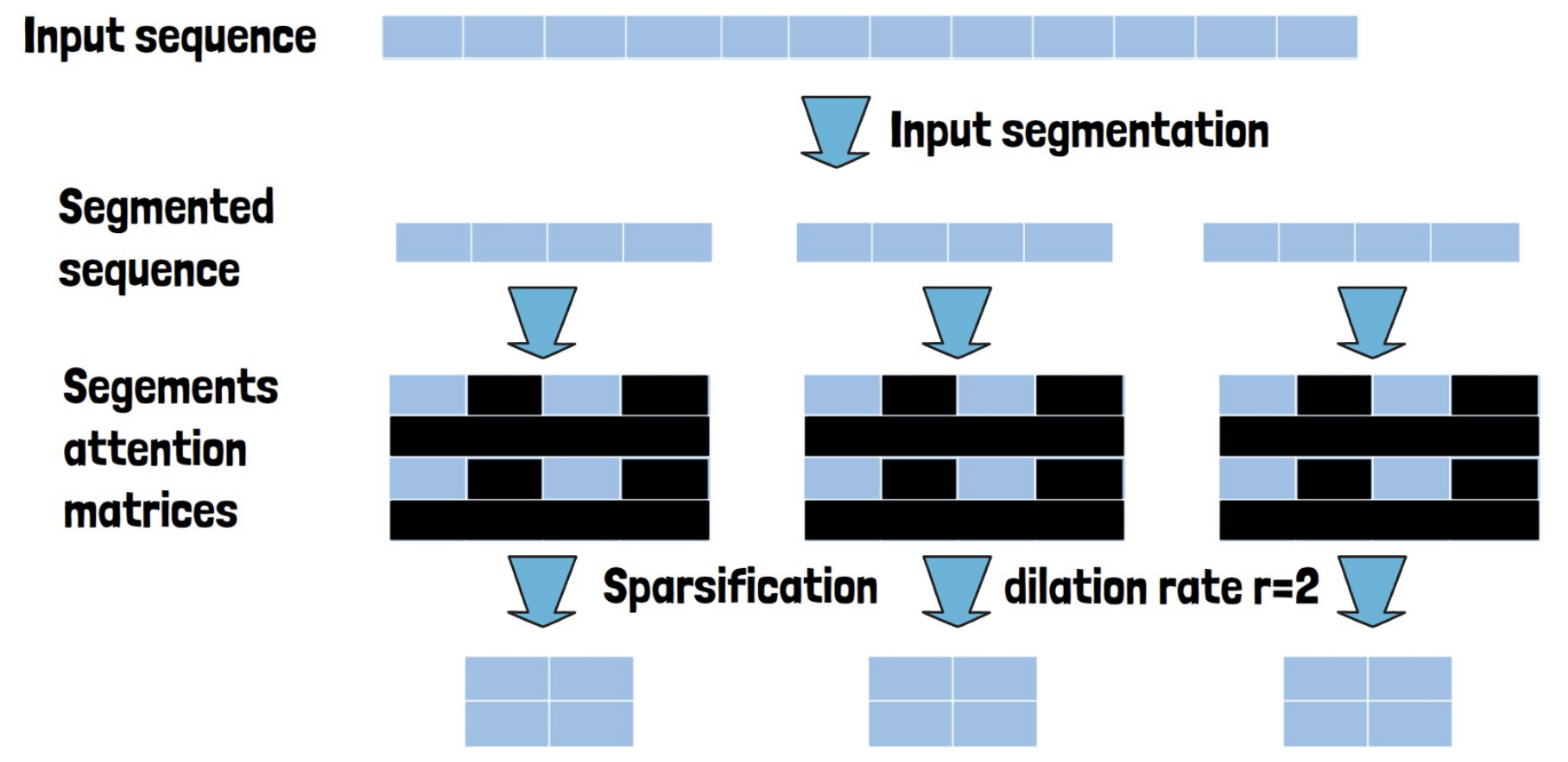
(2) Dilated Attention
Sparsification = Remove rows from each segment based on a hyperparameter \(r\)
- Controls the distance between each removed row
- Each segment can be calculated in parallel \(\rightarrow\) Distributed training on multiple GPUs.
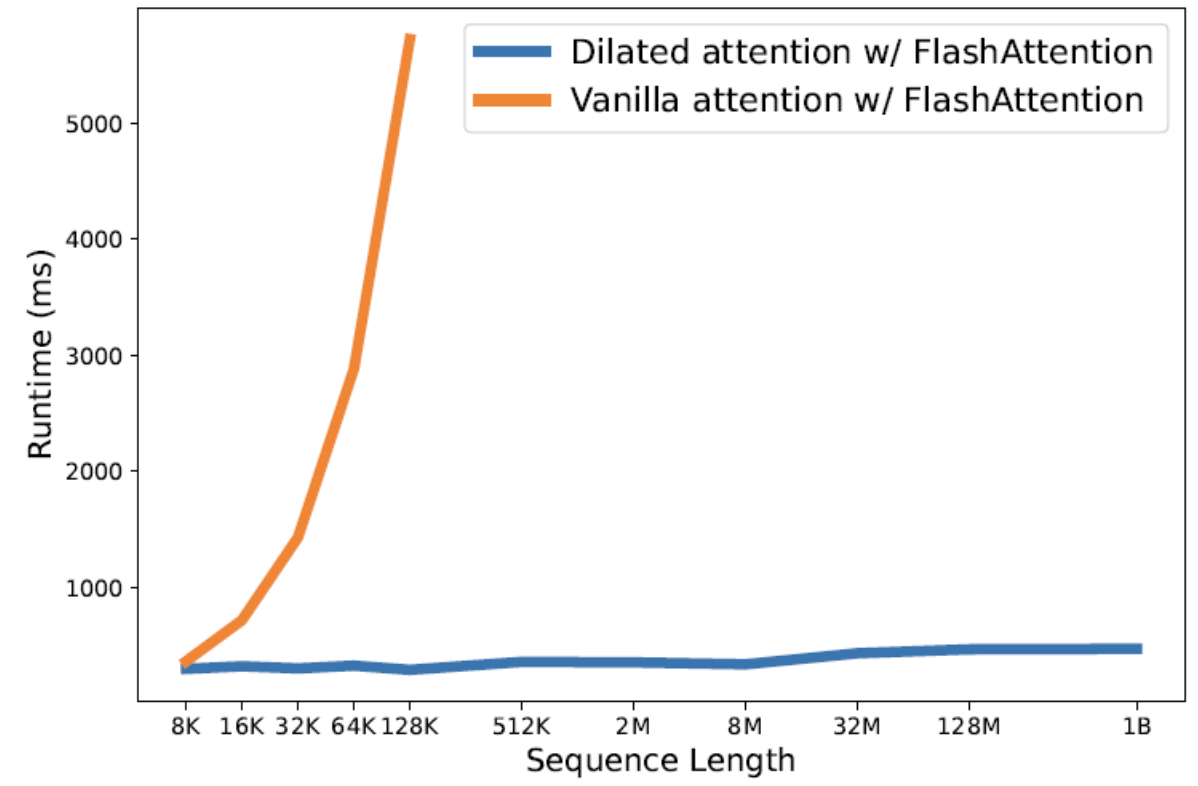
(3) Mixture of Dilated Attentions
Q) Information loss by dilation?
\(\rightarrow\) Use mixture of dilated attentions
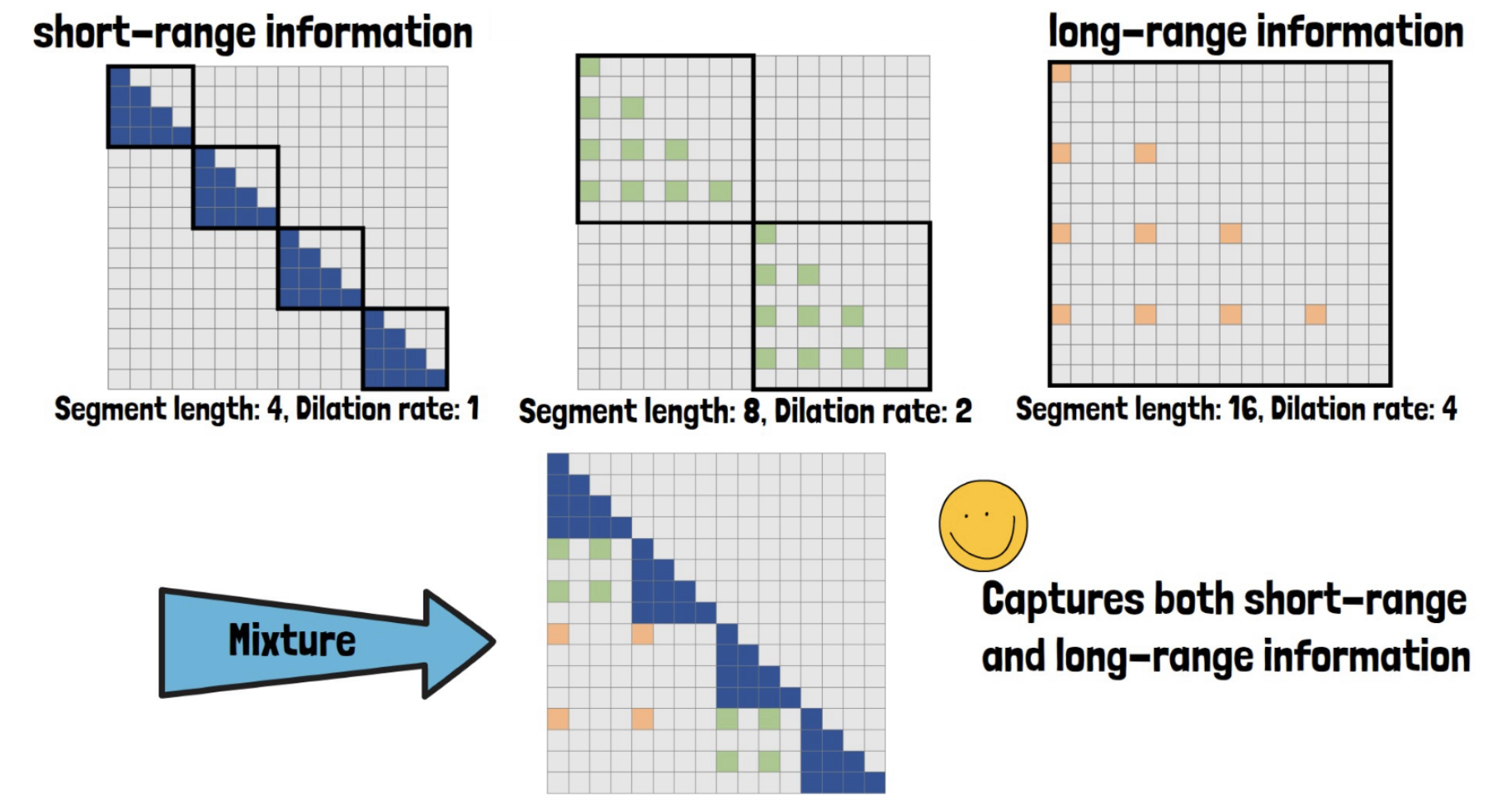
- All of the different dilated attentions can be computed in parallel
- Provide the model with diverse and full information that captures both short-range and long-range information.
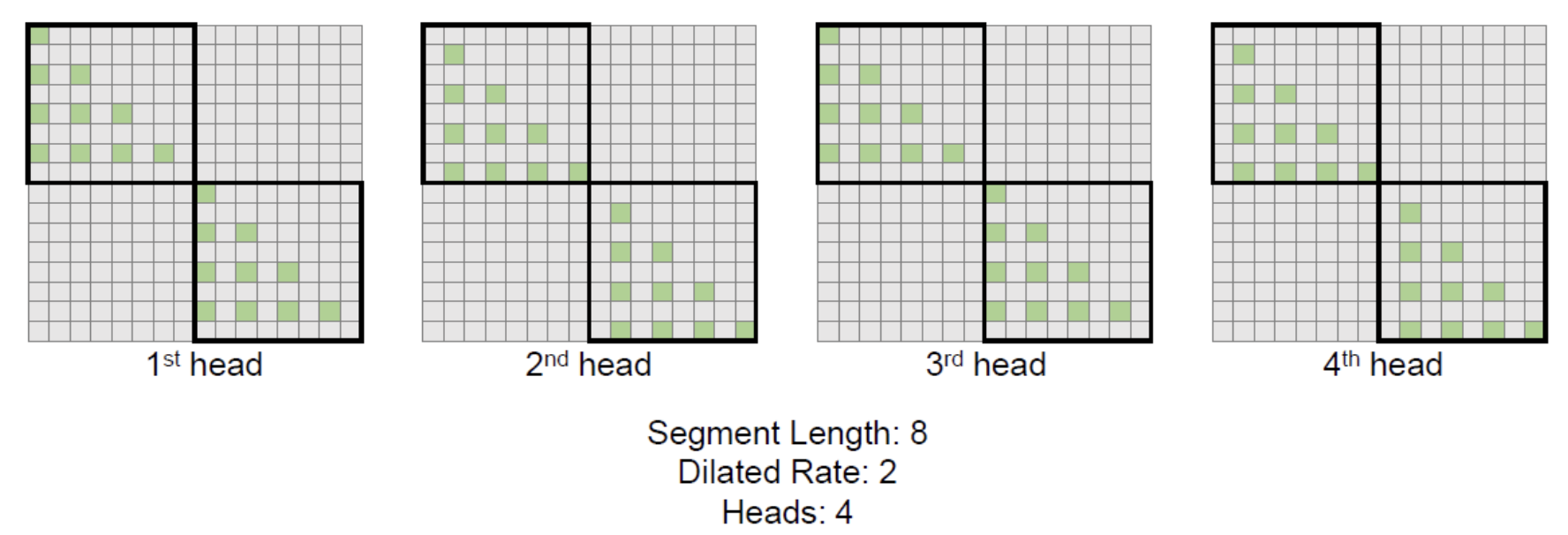
(4) Multi-head Dilated Attention
To further diverse the captured information ( in addition to the mixture of dilate attentions )
\(\rightarrow\) Use multi-head dilated attention blocks
- Choose different rows to remove in each block!