CLLMs: Consistency Large Language Models
Kou, Siqi, et al. "Cllms: Consistency large language models." ICLR 2024
참고:
- https://aipapersacademy.com/consistency-large-language-models/
- https://arxiv.org/pdf/2403.00835
Contents
- Motivation
- LLM inference latency
- Introduction
- Jacobi Decoding
- Jacobi trajectory
- Jacobi Decoding Minimal Performance Gain
- Diffusion & Consistency Models
- Diffusion Models
- Consistency Models
- Consistency LLMs (CLLMs)
- Create a dataset
- Fine-tune
- Inference
- Experiments
1. Motivation
(1) LLM inference latency
When we feed a LLM with a prompt…
\(\rightarrow\) It only generates a single token at a time
( To generate second token, another pass of the LLM is needed )
Limitation: latency
\(\rightarrow\) Common research topic: How to improve LLM inference latency?
(2) Introduction
CLLMs (Consistency LLMs)
-
A method to generate multiple tokens in one pass
( Rather than token by token )
-
Improvement of 2.4 to 3.4 times in generation speed
2. Jacobi Decoding
CLLMs: Based on Jacobi decoding
# ChatGPT
Jacobi decoding is an "iterative" signal recovery method that updates "all" symbols "simultaneously". Each symbol's new value is computed using the previously updated values of other symbols. It allows "parallel" computation, making it fast, but convergence is not always guaranteed.
\(\rightarrow\) Instead of generating a single token at a time, we generate a sequence of tokens on one pass
- Start with random
- Fix them iteratively
(1) Jacobi trajectory
Path between the random starting point and the final response
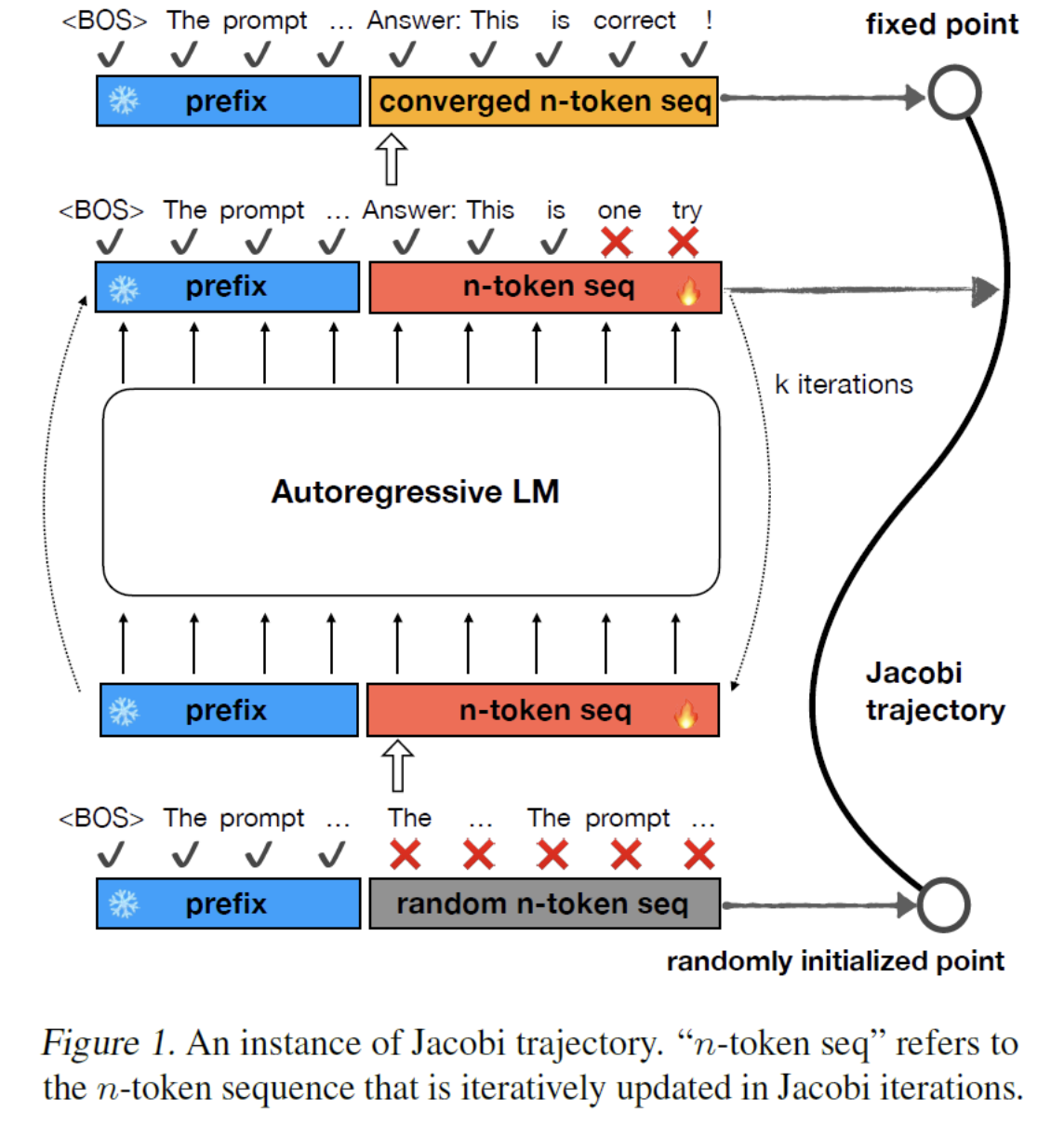
-
[Start] Prompt (blue) + Initial random response sequence (gray)
- Each token is marked with a red (X): Wrong prediction
-
[Each step] Feed the prompt + current response sequence into the LLM
\(\rightarrow\) Fix every token in the response sequence if needed
Note that this is done in a single LLM pass
-
[End] After enough iterations of this, we converge into a valid response
\(\rightarrow\) Final point in the Jacobi trajectory.
(2) Jacobi Decoding Minimal Performance Gain
Vanilla Jacobi decoding
\(\rightarrow\) Does not improve the latency much! Two reasons?
-
(1) In each iteration, each LLM pass is slower
( \(\because\) We process also the response sequence tokens )
-
(2) LLM is usually able to fix only one token from the response sequence ( or a bit more )
3. Diffusion & Consistency Models
(1) Diffusion Models

(2) Consistency Models
Motivation: To avoid the latency drawback of diffusion models
Consistency models
- Reduce the # of iterations
- Key point: Learn to map between any image on the same denoising path to the clear image
- (Term) consistency
- The models learn to be consistent for producing the same clear image for *any point on the same path
\(\rightarrow\) Can jump directly to a clear image from a noisy image!

4. Consistency LLMs (CLLMs)
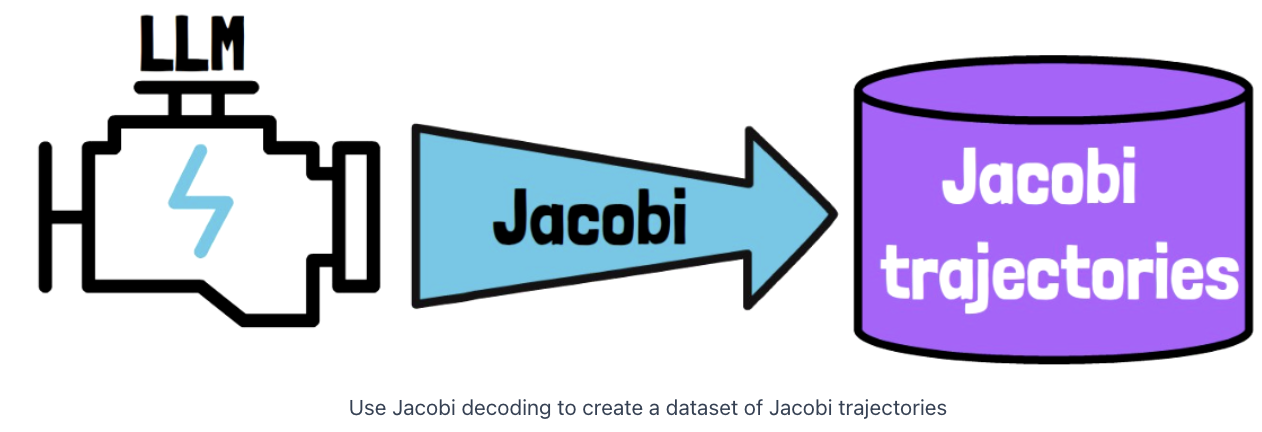
Step 1) Create a dataset
Create a dataset of Jacobi trajectories
-
By taking a pre-trained LLM & run Jacobi decoding
( as much prompts as we want )
Step 2) Fine-tune
Fine-tune the LLM on Jacobi Trajectories
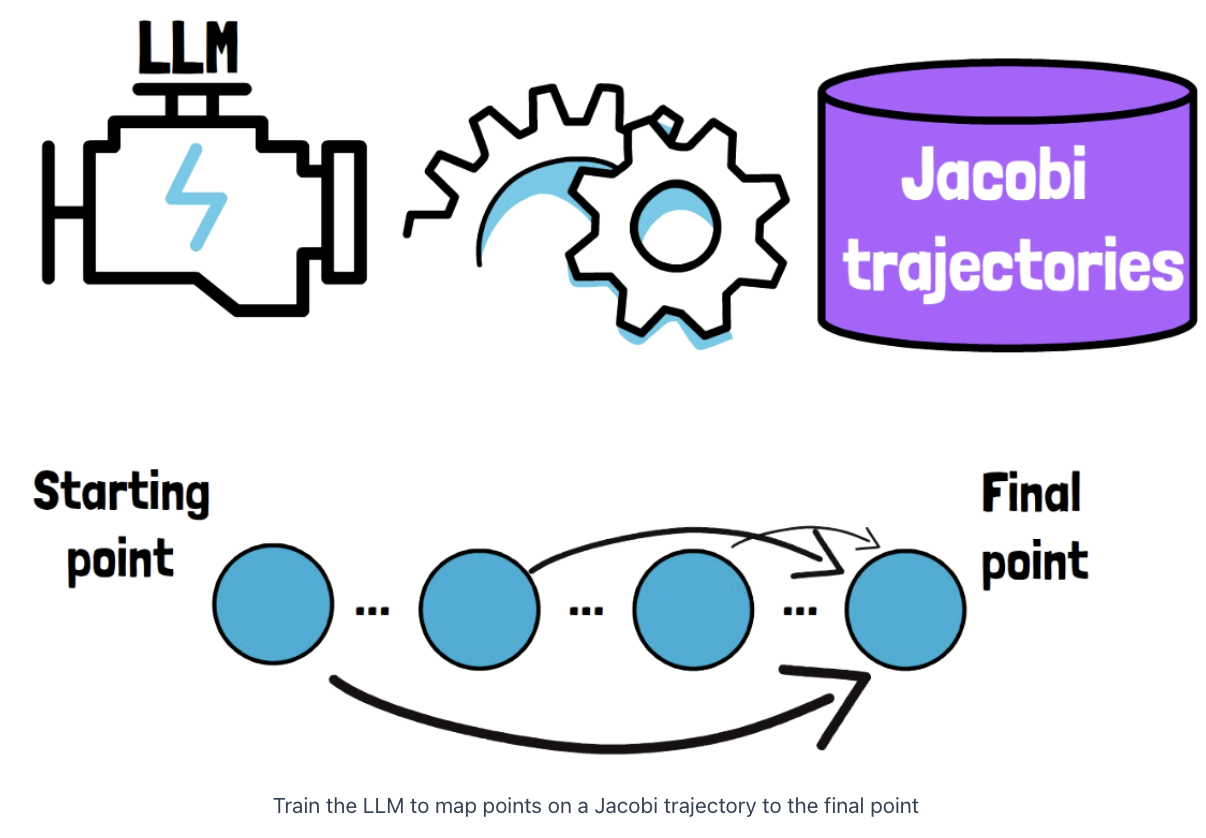
Train the model to yield the final point in the Jacobi trajectory
from each of the intermediate points
Which model do we train?
\(\rightarrow\) Same LLM that we’ve used to create the Jacobi trajectories dataset!
Step 3) Inference
Inference= Run a Jacobi decoding
- with a CLLM trained over Jacobi trajectories
Decoding of standard LLM vs. consistency LLM

- (Blue=correct, Red=wrong)
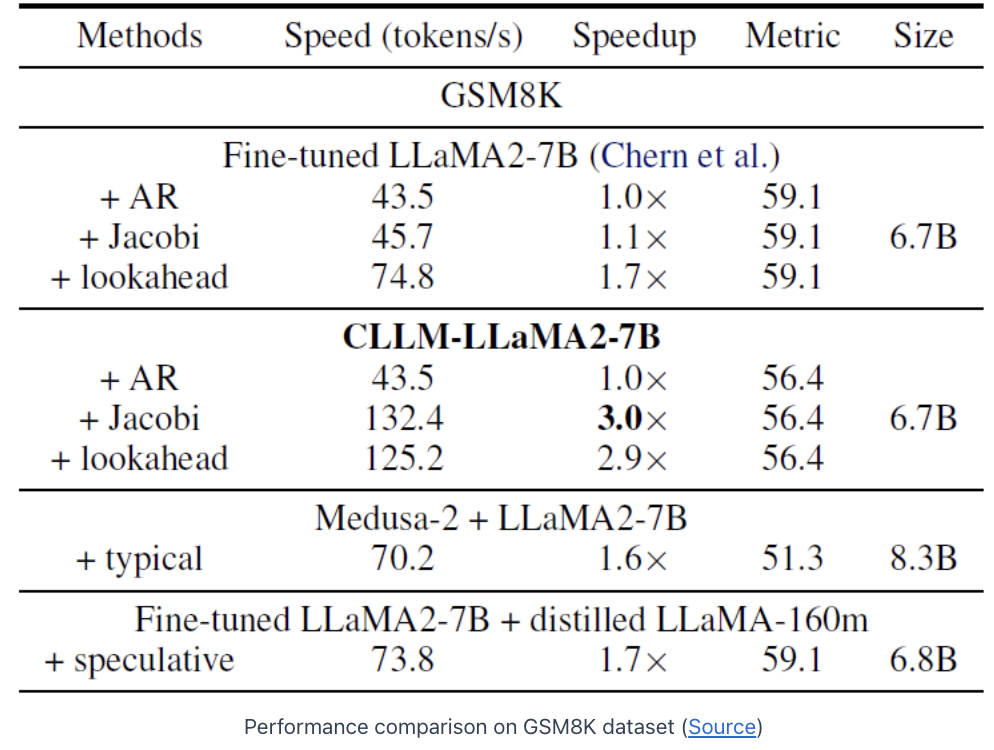
5. Experiments
(1) GSM8K
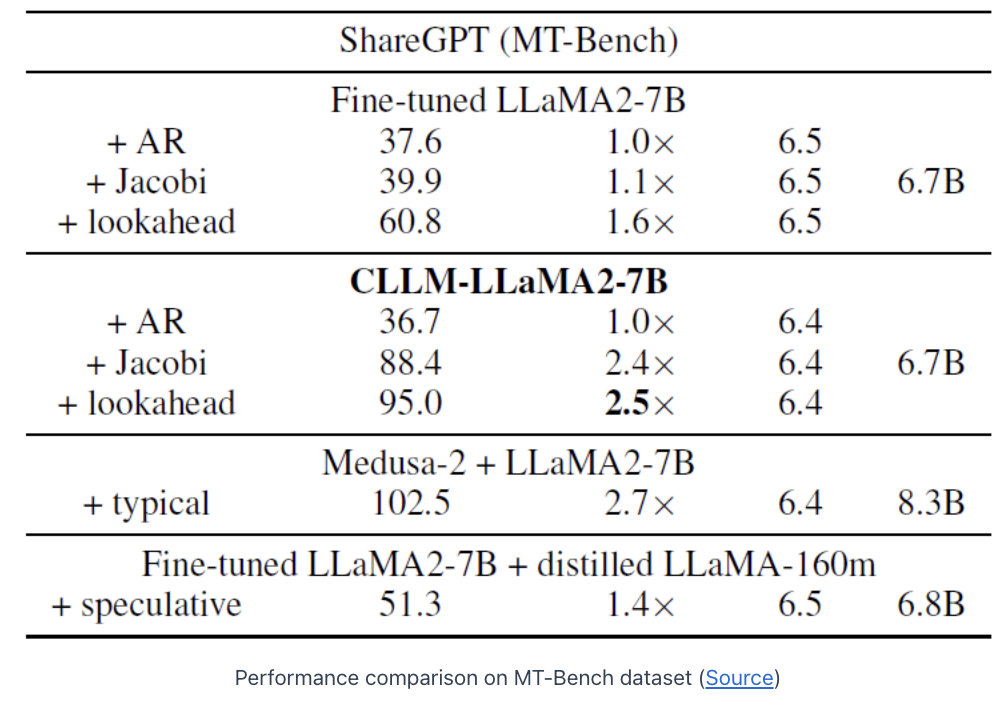
(2) ShareGPT (MT-Bench)