CodeFusion: A Pre-trained Diffusion Model for Code Generation
Singh, Mukul, et al. "Codefusion: A pre-trained diffusion model for code generation." EMNLP 2023
참고:
- https://aipapersacademy.com/codefusion/
- https://aclanthology.org/2023.emnlp-main.716.pdf
Contents
- Human vs. Model (in coding)
- Recap of Diffusion Models
- CodeFusion Architecture
- Training Process
- Phase 1: Unsupervised pretraining
- Phase 2: Supervised fine-tuning
- Experiments
1. Human vs. Model (in coding)
- Human: Often reach a point where we decide to start writing some piece of code from scratch.
- Model: Has one chance to get the implementation right
\(\rightarrow\) The model has no easy way to reconsider tokens it already generated
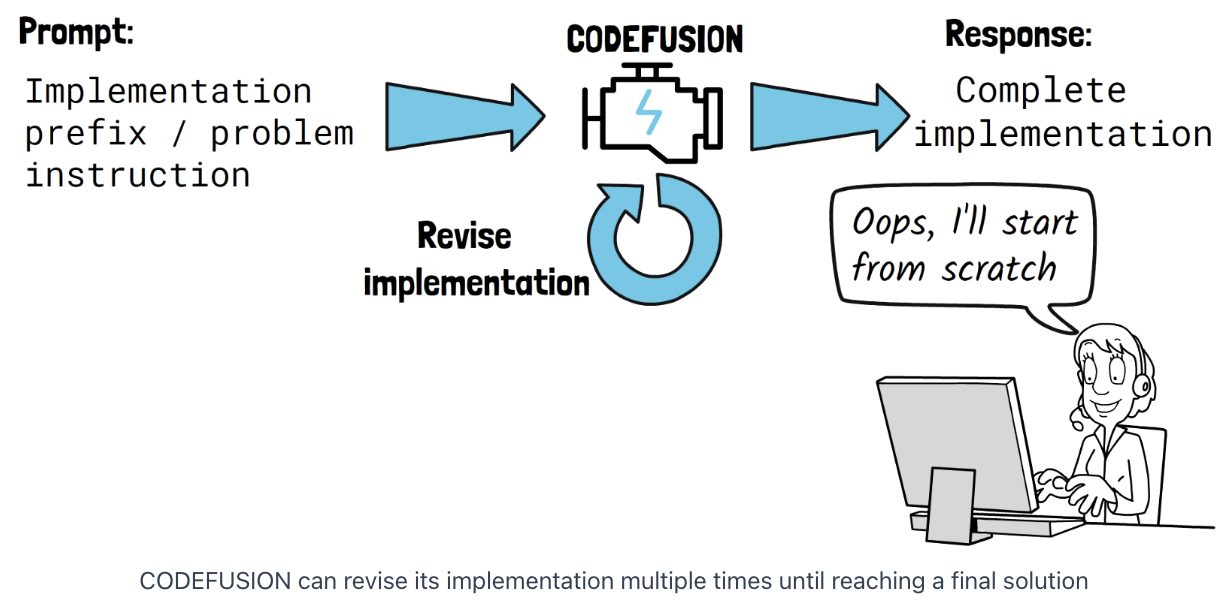
\(\rightarrow\) CodeFusion: Tackles this limitation by letting the model to **revise its implementation **in multiple iterations.
2. Recap of Diffusion models
CodeFusion: Diffusion model for code generation
Recap of diffusion models
-
Backbone of the top text-to-image generation models
(e.g., DALL-E, Stable Diffusion, Imagen … )
-
Input) Prompt: “A cat is sitting on a laptop”.
-
Process) Gradually remove noise from an image
-
Step 1) Starts with a random noise image
-
Step 2) Each step it removes some of the noise
-
Noise removal is conditioned on the input prompt
-
Noise removal process usually takes between 10s to 1000s of steps
\(\rightarrow\) Latency drawback.
-
-
3. CodeFusion Architecture
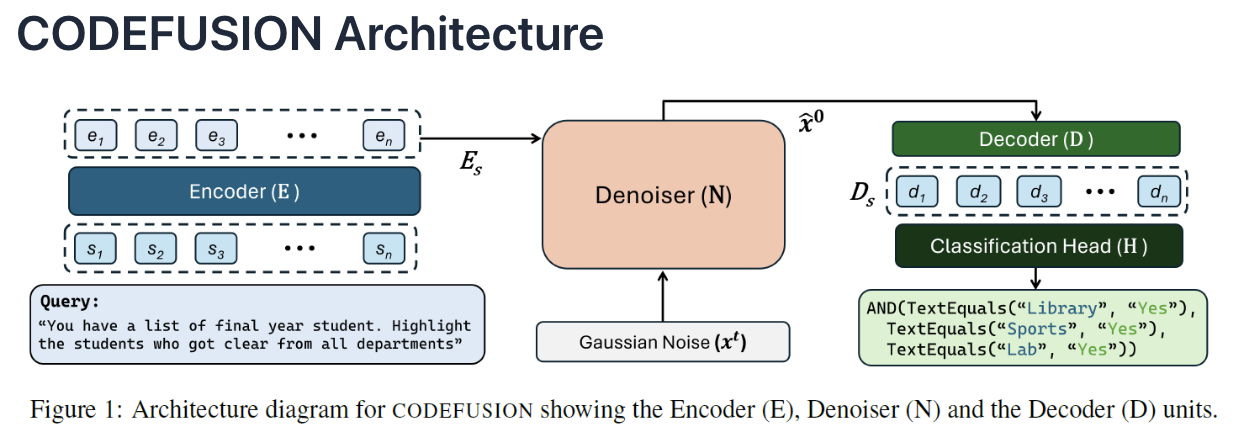
[Key Idea] Allow the model to reconsider its solution in each denoising step
\(\rightarrow\) Mitigating the limitation explained in the beginning of the post
( = Code LLMs cannot easily reconsider tokens that were already generated )
Step 1) Encoding
( = Prompt is passed via a (transformer-based) encoder )
- Text tokens to a vector representation (embeddings)
- Encoder= Pre-trained encoder from the CodeT5 model
Step 2) Denoising
( = The embeddings are passed to (transformer-based) denoiser )
- Input of denoiser = (1) embeddings + (2) random noise in a latent space
- Multiple iterations of gradually removing the noise ( conditioned on the embeddings )
- In the latent space ( not in the data space )
- Ends with \(x_0\) ( = Representation of the final denoiser in the latent space )
Step 3) Decoding
( = Into discrete code tokens )
- (Before projection to classificaiton head) \(x_0\) is passed together with the **prompt embedding \(\mathbf{E}\)
Step 4) Classification
4. Training Process
(1) Phase 1: Unsupervised pretraining
-
Dataset = contain code snippets only ( without prompts )
-
Train only the denoiser and decoder
( Missing prompt embedding is replaced with a random noise )
(2) Phase 2: Supervised fine-tuning
- Dataset = Combined of both prompts and code snippets
- All components are being fine-tuned including the encoder
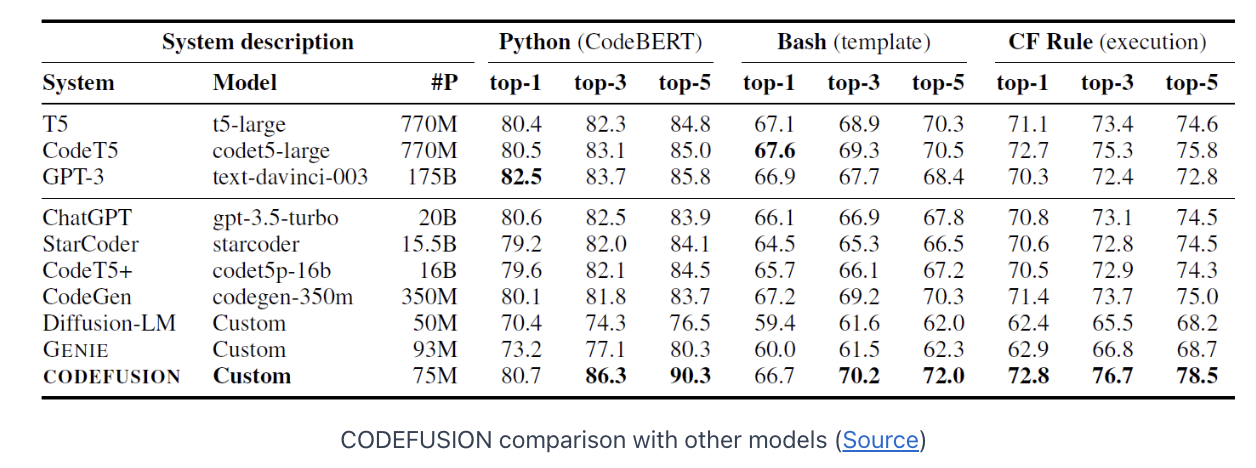
5. Experiments