
LoRA (2021, ICLR)
(1) Background
2021년: 다양한 LLM들 ( ex) GPT2, GPT3 )
한계점: 새로운 Downstream Task를 수행하기 위해서는 FT
\(\rightarrow\) 만만치 않은 작업… too many parameters
해결책: Parameter Efficient Fine Tuning (PEFT)
- LoRA도 그 중에 하나! ( via Low Rank Decomposition )
(2) LoRA
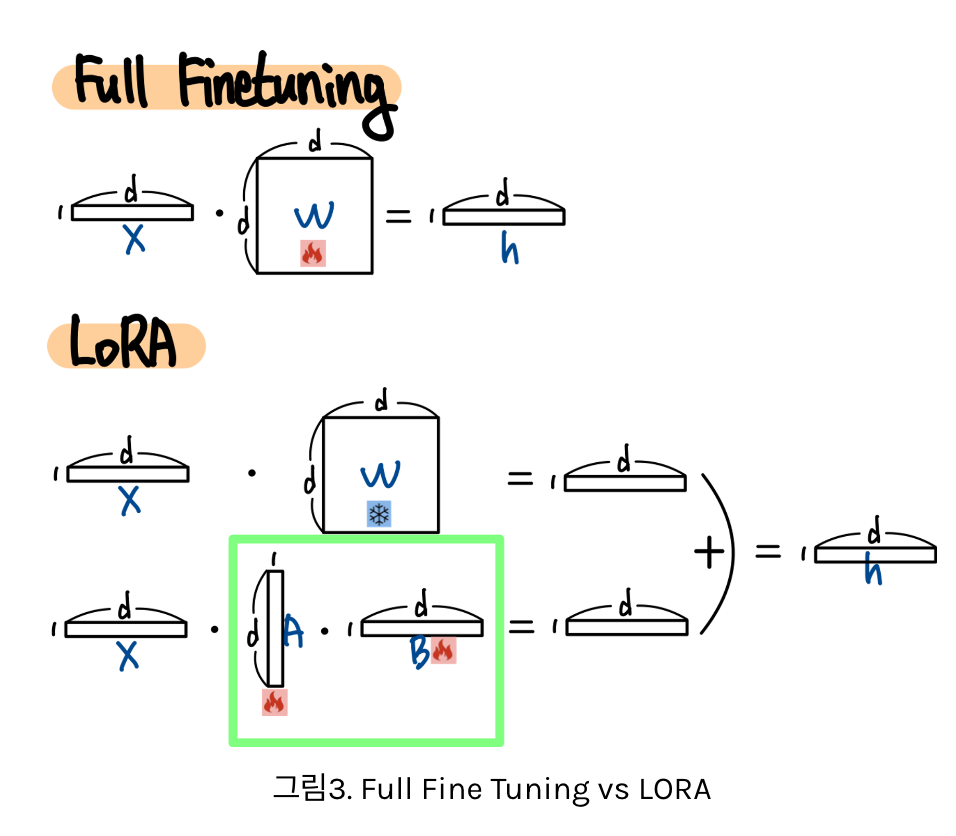
한 줄 요약: 기존 학습 파라미터는 고정한 채로 아주 적은 파라미터만을 추가하여 학습
아주 큰 Transformer 모델을 FT
- Self Attention Layer & Feed Forward Layer
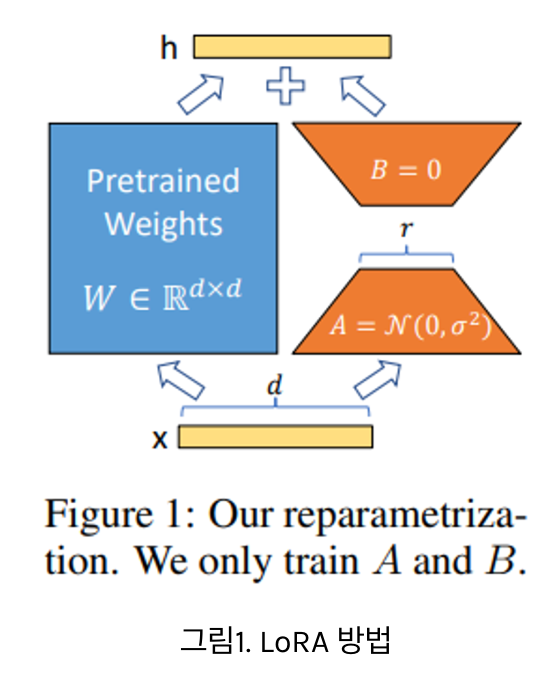
핵심: Low Rank Decomposition
-
큰 차원의 Matrix 연산을 낮은 차원으로 분해
-
ex) Self Attention
-
Q,K,V를 각각 Matrix 연산을 사용하여 구성
\(\rightarrow\) 이때 Q,K,V를 만들기 위해 사용되는 각각의 Matrix W는 매우 고차원
\(\rightarrow\) 이 Matrix를 저차원으로 분해
-
Reference
https://ffighting.net/deep-learning-paper-review/language-model/lora/