Hymba: A Hybrid-head Architecture for Small Language Models
Dong, Xin, et al. "Hymba: A Hybrid-head Architecture for Small Language Models." ICLR 2025
참고:
- https://aipapersacademy.com/hymba/
- https://arxiv.org/pdf/2411.13676
Contents
- Transformer & Mamba
- Hymba
- Introduction
- Hybrid-Head Module
- Parallel > Sequential
- Hymba Human Brain Analogy
- Meta Token
- Overall Architecture
- Experiments
1. Transformer & Mamba
a) Rise of Mamba
LLMs: Commonly utilize Transformers as their backbone
\(\rightarrow\) High capability, but quadratic complexity!
Mamba: Alternative of Transformer
- Based on State Space Models (SSMs)
- Linear complexity
\(\rightarrow\) Nonethelss, Transformers remain the top choice (due to their overall better performance)
b) Limitation of Mamba
SSMs struggle with memory recall tasks
( = Ability to utilize specific information from previous contexts is not as good as that of Transformers, especially if the context is large )
\(\rightarrow\) What about combining both??
2. Hymba
(1) Introduction
Hymba: A Hybrid-head Architecture for Small Language Models
- Hybrid approach: Transformer + SSMs
- Balanced solution for high performance and efficiency
(2) Hybrid-Head Module
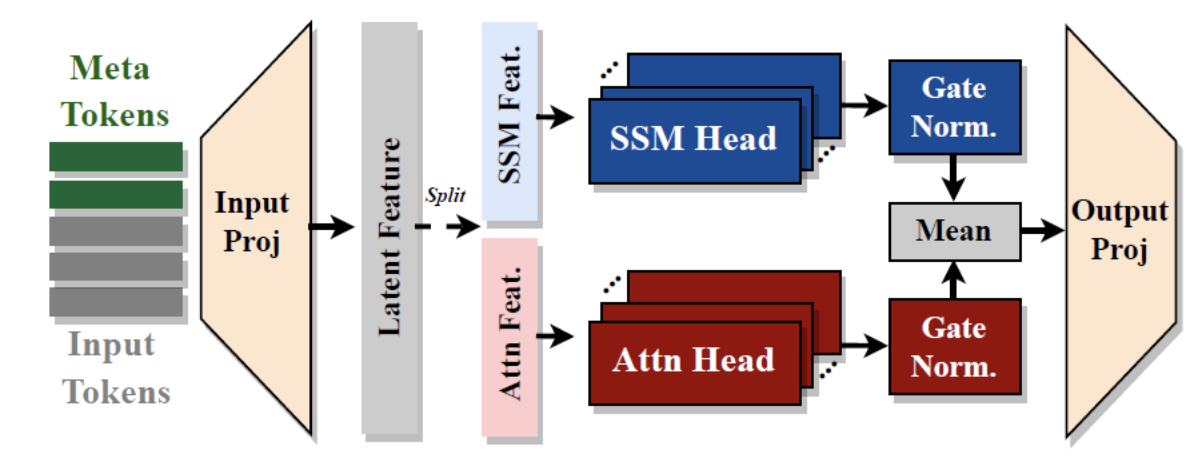
a) Tokens
Tokens = Input tokens + Meta tokens
- Learnable tokens
- Use linear projection layer to embed them
b) Main component
Parallel (1) Attention heads + (2) SSM heads
Combine the results of (1) & (2)
-
Magnitude of outputs from the SSM > Attention
\(\rightarrow\) Outputs of both types of heads pass through a normalization step
c) Output
Linear output projection layer
\(\rightarrow\) Generate output for the next component in the model
(3) Parallel > Sequential
Previous hybrid models
= Combine them sequentially (rather than in parallel)
\(\rightarrow\) Less ideal when handling tasks that are not well suited for a specific head type
Multi-head attention in Transformer = Take different roles
\(\rightarrow\) Hymba is also built with parallel heads.
\(\rightarrow\) Each head process the same piece of information in distinct ways, inheriting the strengths of both types of heads
(4) Hymba Human Brain Analogy
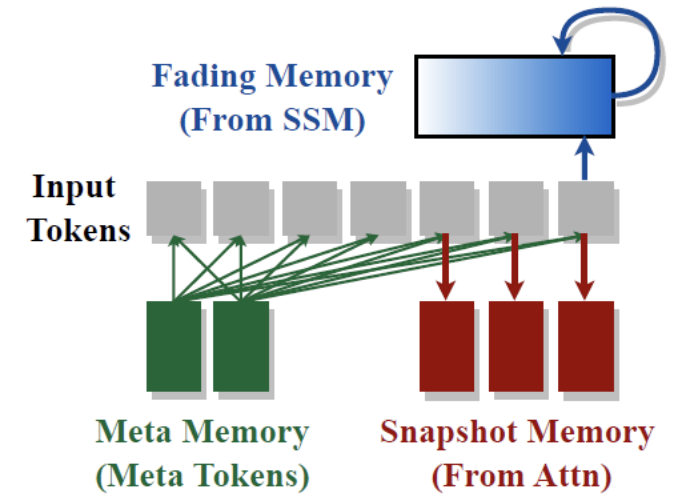
Human brain
- Different types of memory processes work together to store and recall information
(Role 1) Attention head = Snapshot memories
-
Precise details, Detailed recollections
\(\rightarrow\) High-resolution recall of specific information from the input sequence.
(Role 2) SSM head= Fading memories
-
Help us summarize the overall gist of past events without retaining all the details
\(\rightarrow\) Efficiently summarize the broader context
(5) Meta Token
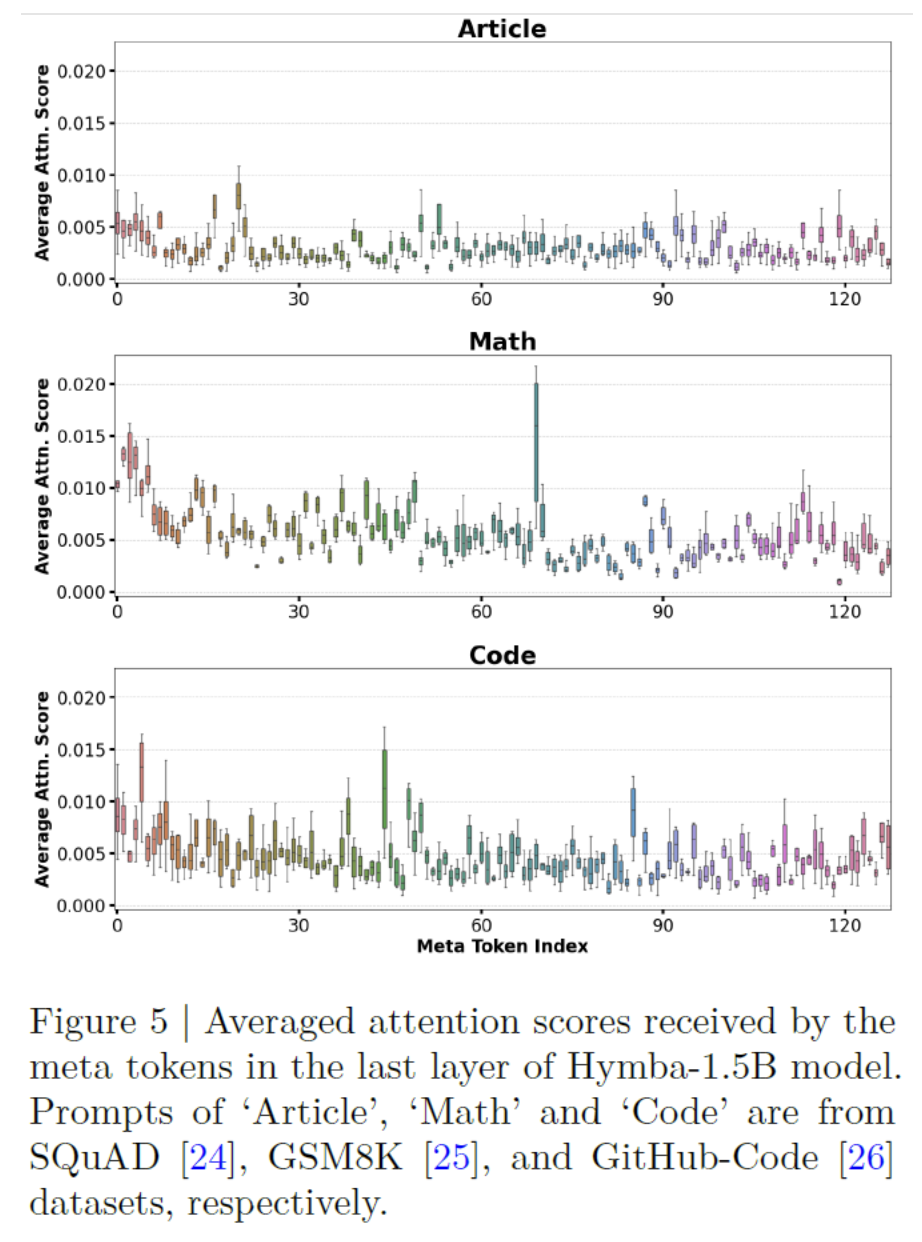
Different meta tokens are activated for the different domains!
\(\rightarrow\) Role of helping to mitigate attention drain
- Where certain tokens (often called “sink tokens”) receive disproportionately high attention weights.
3. Overall Architecture
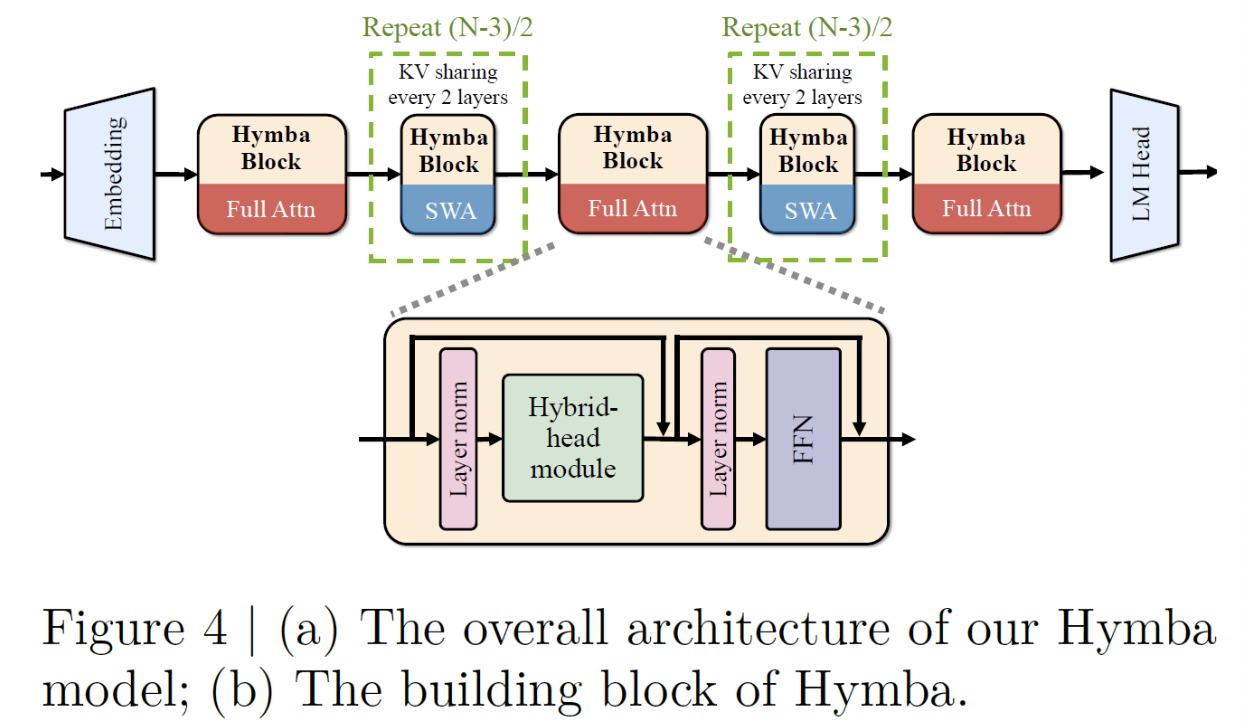
4. Experiments