TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters
Wang, Haiyang, et al. "TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters." ICLR 2025
참고:
- https://aipapersacademy.com/tokenformer/
- https://arxiv.org/abs/2410.23168
Contents
- Motivation
- Transformer vs. Tokenformer
- Transformer
- Tokenformer
- Experiments
1. Motivation
Training Transformers from scratch becomes increasingly costly!
2. Transformer vs. Tokenformer
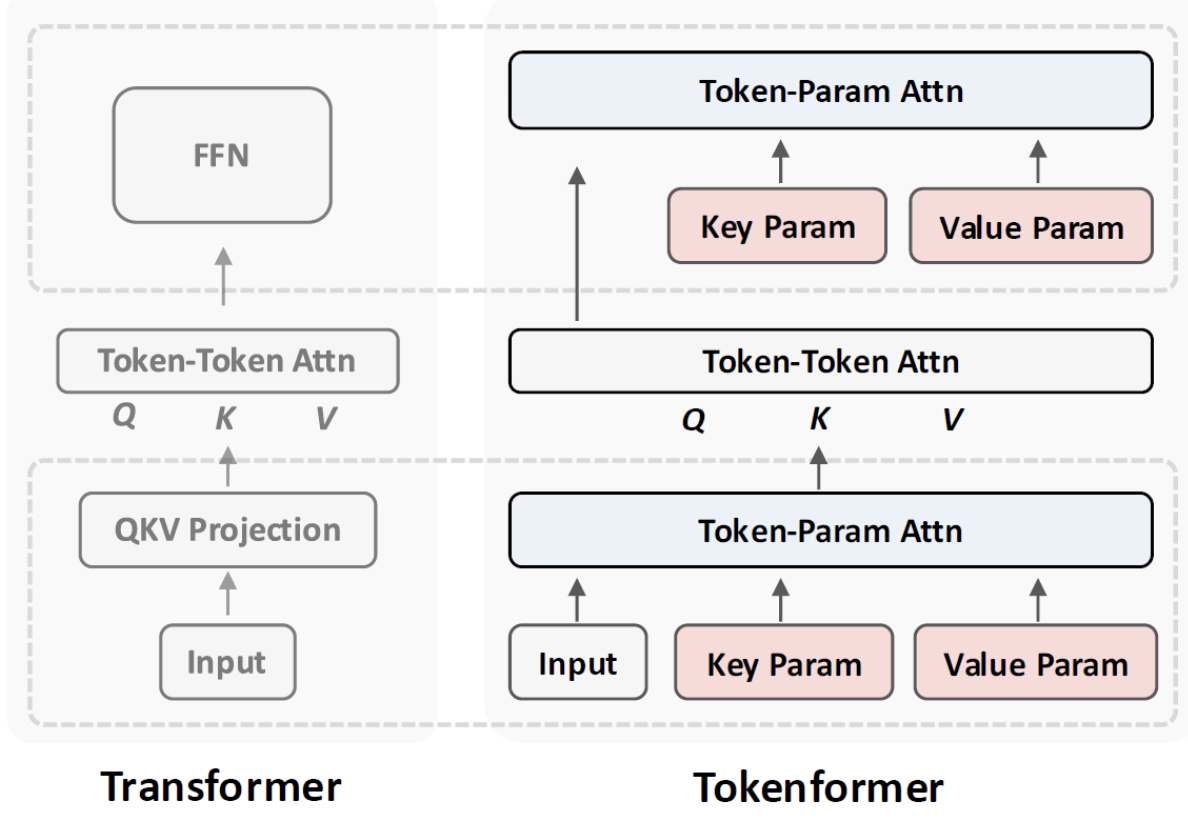
(1) Transformer
Procedure
-
Step 1) Linear projection
= Input first passes through a linear projection block
\(\rightarrow\) Generate inputs for the attention block (\(Q,K,V\))
\(\rightarrow\) Interactions between the parameters and the input tokens
-
Step 2) Self-attention
= Allows input tokens to interact with each other
-
Step 3) FFN
= Interactions between tokens and parameters
(2) Tokenformer
Key Idea
Token-parameter interactions
-
Calculated via linear projection (fixed size of parameters)
\(\rightarrow\) Necessitating training from scratch when increasing model size :(
Solution?
Create a fully attention-based model, including token-parameter interactions
\(\rightarrow\) More flexible architecture that supports incremental # parameter increases
Procedure
- Step 1) Feed input tokens to token-parameter attention block
- [Input] Input tokens (= Query) & parameters (= Key param, Value param)
- [Output] Used as the inputs for the self-attention block (Q, K, and V)
- ( Step 2 = same as Transformer )
- Step 3) Replace FFN with token-parameter attention block
- Query: Output from the self-attention block
- K,V: Different parameters
\(\text { Attention }(Q, K, V)=\operatorname{softmax}\left[\frac{Q \cdot K^{\top}}{\sqrt{d}}\right] \cdot V\).
\(\text { Pattention }\left(X, K_P, V_P\right)=\Theta\left(X \cdot K_P^{\top}\right) \cdot V_P\).
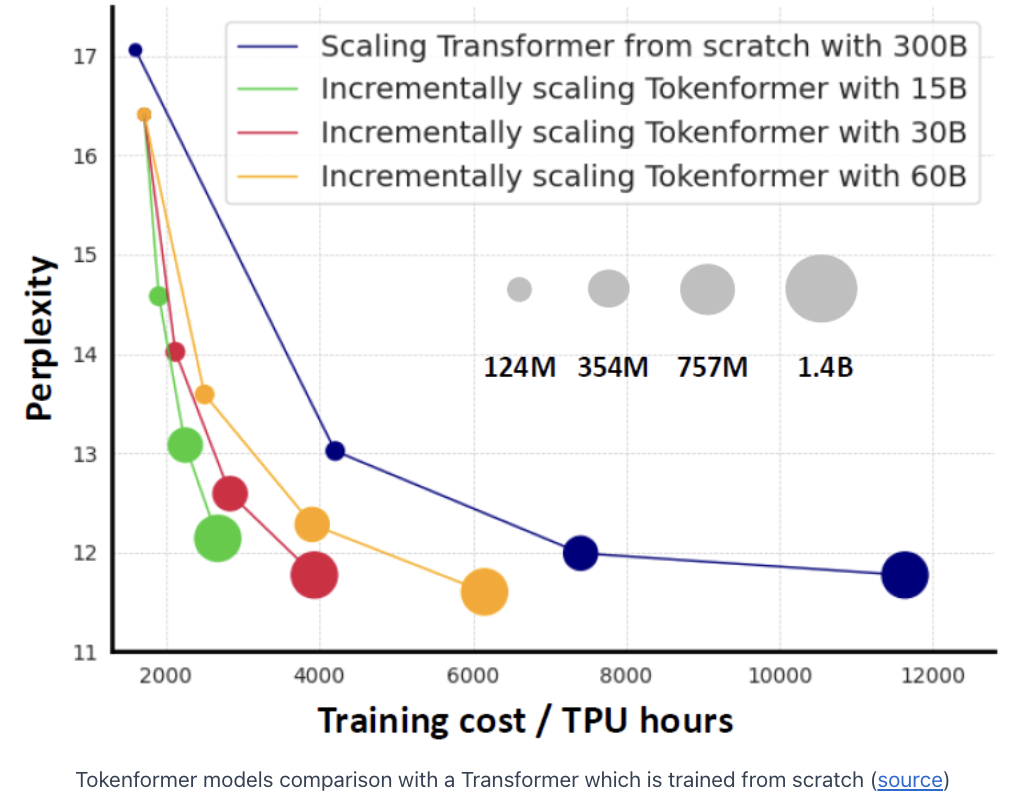
3. Experiments