TimeCAP: Learning to Contextualize, Augment, and Predict Time Series Events with Large Language Model
https://arxiv.org/pdf/2502.11418
Abstract
TSF를 위해서는…
- Numerical TS만이 아니라
- 맥락(context) 이해도 중요함
TimeCAP
- LLM의 활용?
- Predictor (X)
- TS의 맥락을 해석·설명하는 역할 (O)
- Architecture
- LLM Agent 1 (Contextualizer): TS을 설명하는 text summary 생성
- LLM Agent 2 (Predictor): 이 summary를 활용해 이벤트 예측 수행
- Multimodal encoder로 TS + Text를 함께 학습하며, in-context example로 상호 보강
1. Introduction
(1) 문제 배경
기존 TS 모델들
- Temporal dynamics는 잘 포착하나
- Contextual information 는 충분히 반영하지 못함
- e.g., 지리적, 환경적, 도메인적 맥락
LLM의 잠재력
- 방대한 텍스트 기반 domain knowledge
- reasoning, pattern recognition
- few-shot / zero-shot learning 능력을 보유
기존 LLM + TS 접근의 한계
- (Main) LLMs as predictors
- TS를 embedding 또는 tokenized input으로 변환하여 예측 수행
- Fine-tuning 또는 Prompting 방식
- 문제점?
- TS는 본질적으로 non-textual
- LLM이 가진 semantic/contextual knowledge를 충분히 활용하지 못함
- Textualized TS + simple context 방식도 존재하나
- Contextualization이 지나치게 단순하여 효과가 제한적
(2) Proposal
Findings: TS prediction에서 중요한 요소는 ..
-
단순 pattern X
-
CONTEXT!! Geographic context, climate influence, economic interdependency .. O
\(\rightarrow\) 이러한 맥락은 LLM이 강점을 가지는 영역
두 개의 Proposal
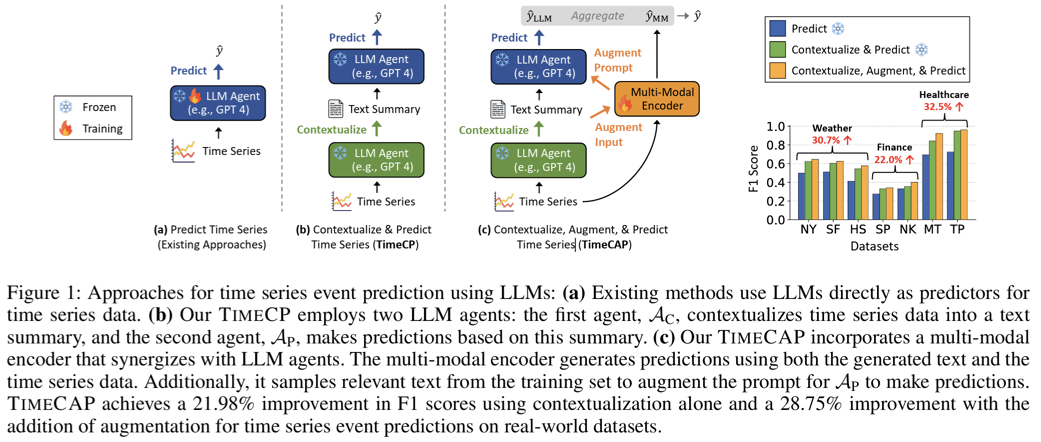
- TimeCP (Contextualize & Predict)
- TimeCAP (Contextualize, Augment & Predict)
a) TIMECP (Contextualize & Predict)
- 두 개의 독립적인 LLM agent 사용
- (1) Contextualizer LLM
- TS를 기반으로 textual summary 생성
- 도메인 지식을 활용해 맥락을 명시적으로 표현
- (2) Predictor LLM
- 생성된 summary를 입력으로 받아 event prediction 수행
- (1) Contextualizer LLM
- Raw TS를 직접 입력하는 방식보다 성능 향상
b) TIMECAP (Contextualize, Augment & Predict)
- Extension of TIMECP
- Multi-modal encoder 도입
- Raw TS + LLM-generated text summary를 함께 학습
- Encoder가 학습한 representation을 활용해
- Training set에서 relevant summaries 선택
- 이를 in-context examples로 Predictor LLM에 제공
- 결과적으로
- LLM → Encoder : contextual augmentation
- Encoder → LLM : prompt augmentation
- 추가 장점
- LMaaS (Language Modeling as a Service) 환경과 호환
- black-box LLM API 사용 가능
- 예측 결과에 대한 interpretable textual rationale 제공
- LMaaS (Language Modeling as a Service) 환경과 호환
(3) Contribution
- LLM을 predictor + contextualizer로 분리한 새로운 관점
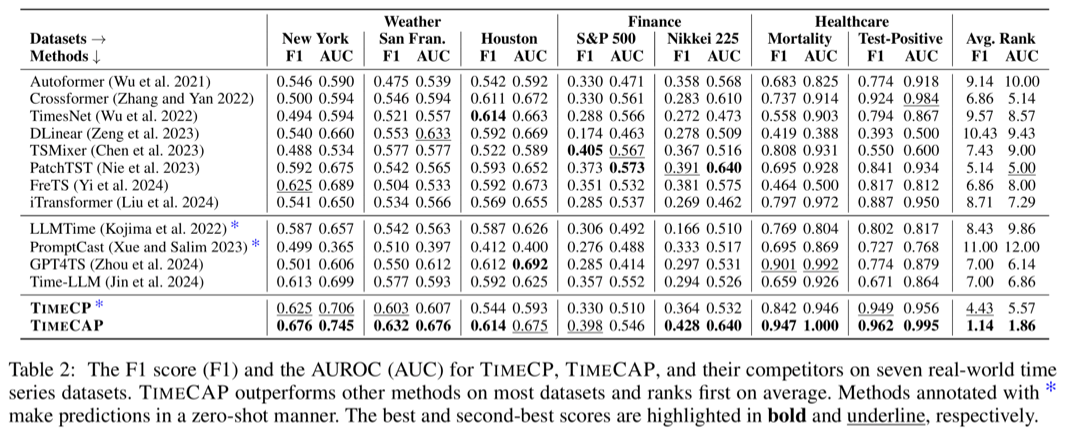
- state-of-the-art 대비 최대 157% F1 score 향상
- context가 중요한 3개 도메인의 7개 real-world dataset 공개
3. Methodology
Overview
- TS event prediction을 위해 LLM + multi-modal encoder를 결합한 framework 제안
- 단계적 발전 구조
- TIMECP: LLM을 contextualizer + predictor로 분리
- TIMECAP: encoder를 추가해 augmentation과 fusion까지 수행
- 추가적으로 interpretability 제공
3.1 Problem Statement
LLMs
- LLM을 \(M_\theta\)로 정의, 파라미터 \(\theta\)는 frozen
- Zero-shot, Gradient-free → LMaaS-compatible
- 입력과 출력: \(R = M_\theta(p(D, S))\)
- \(D\): 관심 데이터
- \(S\): optional supplementary data (e.g., demonstrations)
- \(p(\cdot)\): prompt function
LLM Agents
- 동일한 \(M_\theta\)를 사용
- 역할은 prompt 설계로 분리 (summarization, prediction 등)
Time Series Event Prediction
- 입력 TS: \(x = (x_1, \dots, x_L), \quad x_t \in \mathbb{R}^C\)
- 목표: 미래 event outcome \(y\) 예측
- multi-class classification으로 설정
- 가정: TS는 contextual information (geography, climate, domain knowledge)에 강하게 의존
2. TIMECP (Contextualize and Predict)
Motivation?
\(\rightarrow\) 기존 방법 (e.g., PromptCast)은 LLM을 direct predictor로만 사용
\(\rightarrow\) Contextual reasoning 활용이 제한적
Dual LLM Agent 구조
- (1) AC (Contextualizer)
- TS → context-aware text summary 생성
- \(s_x = AC(x) = M_\theta(p_C(x))\).
- (2) AP (Predictor)
- Summary 기반 event prediction
- \(\hat{y}_{LLM} = AP(s_x) = M_\theta(p_P(s_x))\).
Key Insight
- Raw TS → prediction인 \(M_\theta(p_P(x))\) 보다
- TS → context → prediction이 일관되게 우수
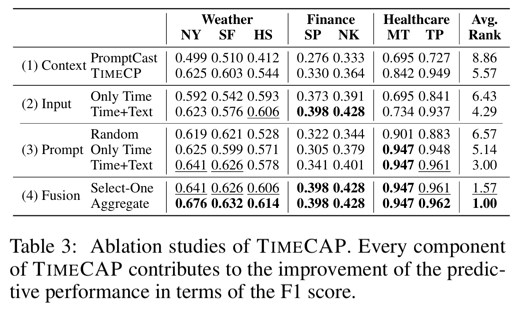
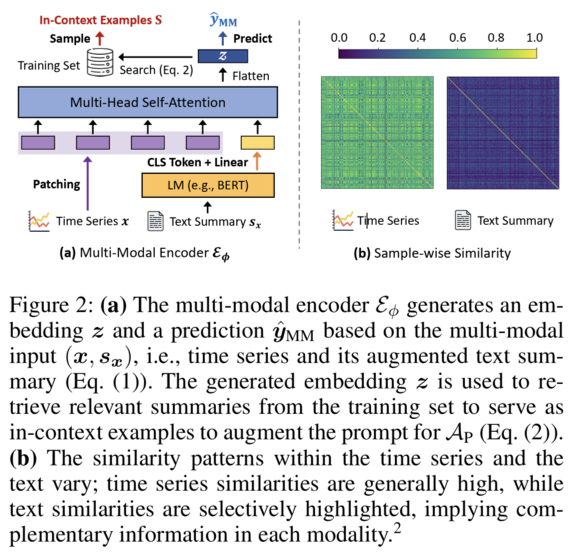
3.3 TIMECAP (Contextualize, Augment, Predict)
Core Idea
- TIMECP + trainable multi-modal encoder
- 두 가지 augmentation
- (1) Input augmentation
- (2) Prompt augmentation
Multi-Modal Encoder
\[(\hat{y}_{MM}, z) = E_\phi(x, s_x)\]- \(E_\phi\): trainable encoder
- \(z\): joint embedding (TS + text)
Details
- (1) Text Encoding
- \(\hat{z} = LM(s_x) \in \mathbb{R}^{d'}\).
- \(\tilde{z}_{text} = \hat{z} W_{text} \in \mathbb{R}^d\).
- (2) TS Encoding (Patching)
- Channel \(i\)에 대해, \(\hat{x}^{(i)} \in \mathbb{R}^{N \times L_p}\)
- Linear projection: \(\tilde{z}^{(i)}_{time} = \hat{x}^{(i)} W_{time}\)
- (1+2) Fusion & Attention
- Concatenation: \(\tilde{z}^{(i)} = [\tilde{z}^{(i)}_{time}; \tilde{z}_{text}]\)
- MHSA: \(z_h^{(i)} = \text{Softmax}\Big(\frac{Q_h^{(i)} K_h^{(i)T}}{\sqrt{d/H}}\Big)V_h^{(i)}\)
- (Final) Final Prediction: \(z = [z^{(1)}; \dots; z^{(C)}] \in \mathbb{R}^{dC}\)
- \[\hat{y}_{MM} = z W_P\]
In-Context Example Sampling
- Nearest Neighbor Retrieval
- \(S = \{(s_{x_j}, y_j) : j \in \text{NN}_k(z)\}\).
- \(\text{NN}_k(z) = \arg\max_{j \in T}^{top-k} (-\mid \mid z - Z_j\mid \mid )\).
- \(S = \{(s_{x_j}, y_j) : j \in \text{NN}_k(z)\}\).
- Prompt Augmentation for AP
- \(\hat{y}_{LLM} = AP(s_x, S) = M_\theta(p_P(s_x, S))\).
Fused Prediction
Linear Fusion: \(\hat{y} = \lambda \hat{y}_{LLM} + (1 - \lambda)\hat{y}_{MM}\).
- \(\hat{y}_{LLM}\): one-hot 변환 후 사용
- LLM reasoning + encoder dynamics 결합
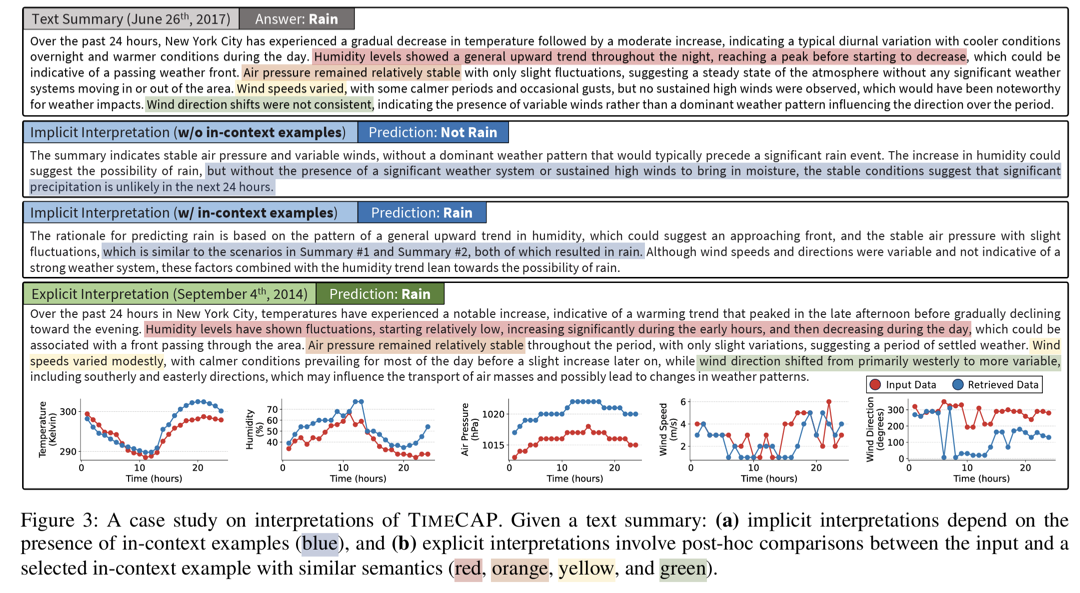
3.4 Interpreting the Predictions
a) Implicit Interpretation (AI_P)
\((\hat{y}_{LLM}, r) = M_\theta(p_P^I(s_x, S))\).
- prediction + rationale 동시 생성
- LLM의 domain reasoning 활용
b) Explicit Interpretation (AE_P)
\((\hat{y}_{LLM}, s_{x_j}^*) = M_\theta(p_P^E(s_x, S))\).
- 가장 영향력 있는 in-context example 선택
- 대응되는 TS x_j^*와 비교 분석 가능
4. Experiments