
TimeCMA: Towards LLM-Empowered Multivariate Time Series Forecasting via Cross-Modality Alignment
https://arxiv.org/pdf/2406.01638
Abstract
-
Recent Trend: TS + LLM (Textual prompt)를 결합
-
Limitation
-
LLM-based 방법: Disentangled embeddings 학습에 취약함
( == TS 구조적 정보가 entangled representation에 묻힘 )
-
-
Proposed Framework: TimeCMA
-
“Cross-modality” alignment 기반 (TS+ Text)의 framework
-
a) Dual-Modality Encoding
-
TS encoding branch: Disentangled하지만 weak한 TS embeddings를 생성
-
LLM-empowered encoding branch: Entangled하지만 robust한 prompt embeddings를 생성
-
-
b) Cross-Modality Alignment
-
TS modality & Prompt modality 간의 similarity를 활용
-
Disentangled하면서도 robust한 TS embeddings를 복원함
-
-
c) 기타:
-
Efficient Prompt Design
-
핵심 temporal information이 last token에 집중되도록 prompt를 설계함
-
Downstream prediction에는 last token만 사용함
-
-
Inference Acceleration
-
Last token embeddings를 저장함
-
Inference speed를 효과적으로 향상시킴
-
-
-
-
Experimental Results
- Eight real-world datasets에서 실험을 수행함
- TimeCMA가 state-of-the-art 방법들을 일관되게 상회함
1. Introduction
(1) Background: LLM-Based Trend
- Pre-trained LLM을 TS에 도입
- Abundant language data에서 학습된 robust embeddings를 활용
(2) Existing LLM-Based Categories
a) TS-based LLMs
- Tokenizer를 embedding layer로 대체해 TS를 직접 처리함
- Language–TS domain gap으로 weak embeddings가 발생함
b) Prompt-based LLMs
- Text prompt로 TS forecasting task를 설명함
- Data-to-text 변환 또는 text summary를 활용함
- Robust embeddings로 기존 방법 대비 성능을 향상시킴
(3) Key Limitation of Prompt-based LLMs
-
Data entanglement
-
Disentangled하지만 weak한 TS embeddings와
-
Entangled하지만 robust한 prompt embeddings가 단순 결합됨
-
-
Textual information이 noise로 작용해 forecasting 성능을 저하시킴
(4) Overview
Insight
- MTSF에는 disentangled하면서도 robust한 TS embeddings가 필요함
- LLM prompt embeddings 내부에는 유용한 TS 정보가 이미 존재함
Core Idea
- Cross-modality alignment를 통해 필요한 정보만 선택적으로 추출함
- Similarity-based retrieval로 robust한 TS component를 복원함
2. Proposed Framework: TimeCMA
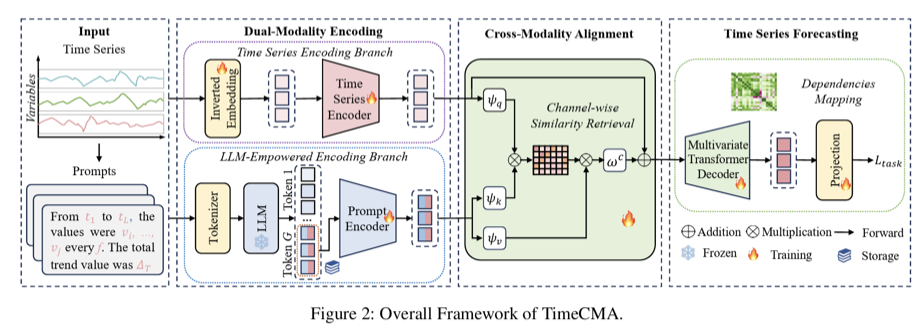
a) Dual-modality encoding
- TS encoding branch
- Disentangled한 variable embeddings를 추출함
- LLM-empowered encoding branch
- 동일한 TS를 prompt로 감싸 robust embeddings를 생성함
b) Cross-modality alignment module
- Channel-wise similarity로 prompt embeddings에서 TS component를 추출함
- Original TS embeddings를 강화함
c) Last Token
- Computational Challenge
- MTS는 variable × time 구조로 연산량이 큼
- LLM의 multi-head attention은 high-dimensional output을 생성함
- Frozen LLM에서도 반복적인 processing이 발생함
- Efficiency Design
- Last token에 핵심 temporal information이 집중되도록 prompt를 설계함
- Downstream alignment에는 last token embedding만 사용함
- Last token embeddings를 offline으로 저장함
- Repetitive LLM processing을 제거해 inference speed를 향상시킴
Contributions
- Dual-modality LLM에서의 data entanglement 문제를 분석함
- Cross-modality alignment 기반 TimeCMA를 제안함
- Last token 기반 설계로 computational cost를 감소시킴
- Eight datasets에서 state-of-the-art 성능을 달성함