GPT4MTS: Prompt-based Large Language Model for Multimodal Time-series Forecasting
https://ojs.aaai.org/index.php/AAAI/article/view/30383
Abstract
Problem setting
- 기존 TSF 모델은 uni-modal에만 집중
- 성능 향상에 도움이 되는 extra knowledge가 존재하지만
- 수집이 어렵고
- multimodal fusion이 쉽지 않음
Key idea
- LLM을 활용해 다양한 데이터 소스로부터 corresponding textual information을 수집하는 general principle 제안
- (Prompt-based LLM framework) GPT4MTS 제안
- numerical data + textual information을 동시에 활용하는
- Dataset contribution
- GDELT-based multimodal TS dataset 제안
- 뉴스 영향 예측을 위한 concise + well-structured multimodal TS + text 데이터셋
Results
- extensive experiments
- extra-textual information을 활용한 forecasting 성능 향상 입증
1. Introduction
Motivation
- TSF는 다양한 분야에서 핵심적인 역할을 함
- Textual information의 영향력이 커지고 있음에도, multimodal TS dataset은 부족함
- LLM의 등장으로 새로운 forecasting paradigm과 데이터셋 설계가 가능해짐
- Limitations of existing methods: 기존 방법은 unimodal TS에만 집중
Related LLM-based attempts
- 일부 연구는 TS를 text로 변환하거나 LLM embedding과 정렬함
- True multimodal input (TS + text)을 사용하는 접근은 거의 없으며
- METS는 healthcare에 한정되어 일반화가 어려움
Proposed pipeline
- LLM을 활용한 textual information generation pipeline 제안
- Collection → Summarization → Re-rank → Efficient summary 구조
- 모든 도메인에 적용되지는 않지만 finance, communication 등에는 유효
Dataset: GDELT
- GDELT-based multimodal TS dataset 구축
- TS + event textual summaries를 포함
- computational communication, finance, policy 분석 등 다양한 분야 확장 가능
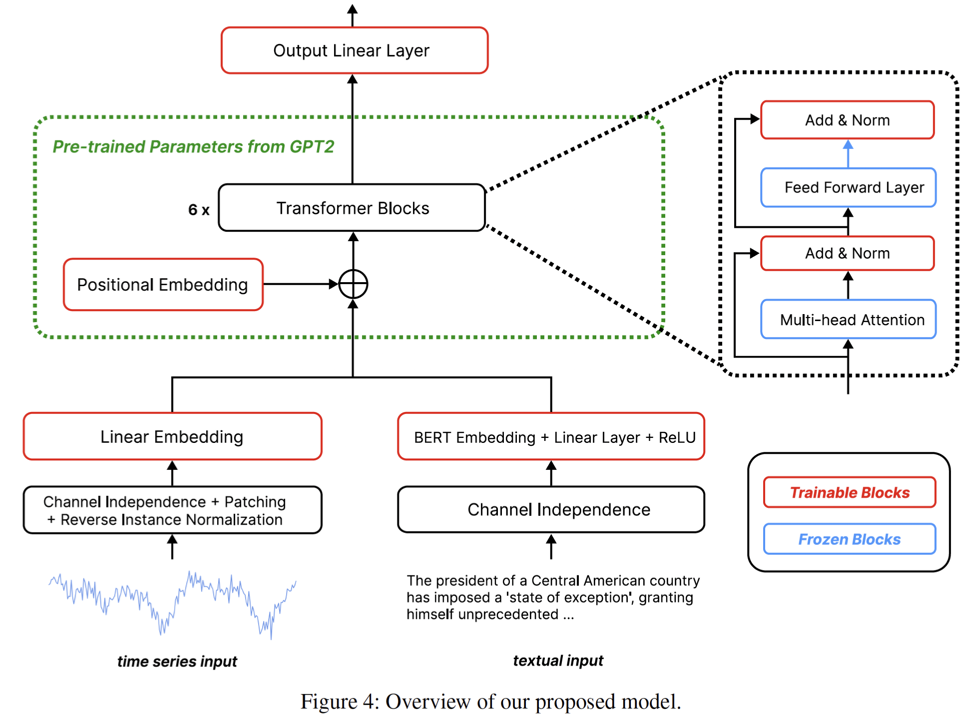
Model: GPT4MTS
- Prompt tuning-based LLM, GPT4MTS 제안
- Numerical TS는 patch + RevIN + linear embedding
- Text는 soft prompt로 사용하며 attention layer는 freeze
- Extra-textual information이 forecasting 성능을 향상시킴
Contributions
- (1) Textual data를 TS에 통합하는 general pipeline 제안
- (2) GDELT multimodal dataset 구축
- (3) Extensive experiments로 방법의 효과 검증
2. Related Works
(1) LLM
- Transformer 기반 LLM은 NLP와 CV에서 큰 성과를 보임
- BERT, T5, GPT, LLaMA 등 다양한 사전학습 모델 존재
- TS forecasting 분야에서의 LLM 활용은 아직 충분히 탐구되지 않음
(2) Prompting
- Prompt는 모델의 출력을 유도하는 핵심 메커니즘
- 기존은 주로 vision/NLP 중심
- CLIP, T5 등에서 text prompt의 효과가 입증됨
- 본 연구는 textual prompt로 numerical TS 처리를 유도하는 점이 차별점
(3) Multimodal TS Dataset
- 기존 benchmark (Weather, ETT)는 numeric-only TS
- GDELT dataset은 textual content를 포함한 TS 제공
- LLM이 extra-textual information을 활용할 수 있는 환경을 조성
(4) LLM methods for TS
- TS를 patch로 처리하거나 TS–text embedding을 정렬하는 접근들이 존재
- Patch-based TS + pre-trained model
- Contrastive alignment (TEST)
- Reprogramming 기반 (TimeLLM)
- TS → text 변환 또는 text-only 방식
- 본 연구
- pre-trained LLM + prompt 기반 textual input을 사용
3. GDELT 데이터셋
Global Database of Events, Language, and Tone (GDELT) database
- 전 세계 뉴스 미디어를 100+ 언어로 모니터링하는 대규모 이벤트 DB
- 이벤트 중심 정보로 global societal trends 분석에 적합

(1) TS Data Collection
- 상위 10 EventRootCode에 대해 데이터 수집
- Forecasting 변수
- NumMentions
- NumArticles
- NumSources
- 이벤트별 attention level을 반영하는 지표
- 55 US regions + US national
- 기간: 2022-08-17 ~ 2023-07-31
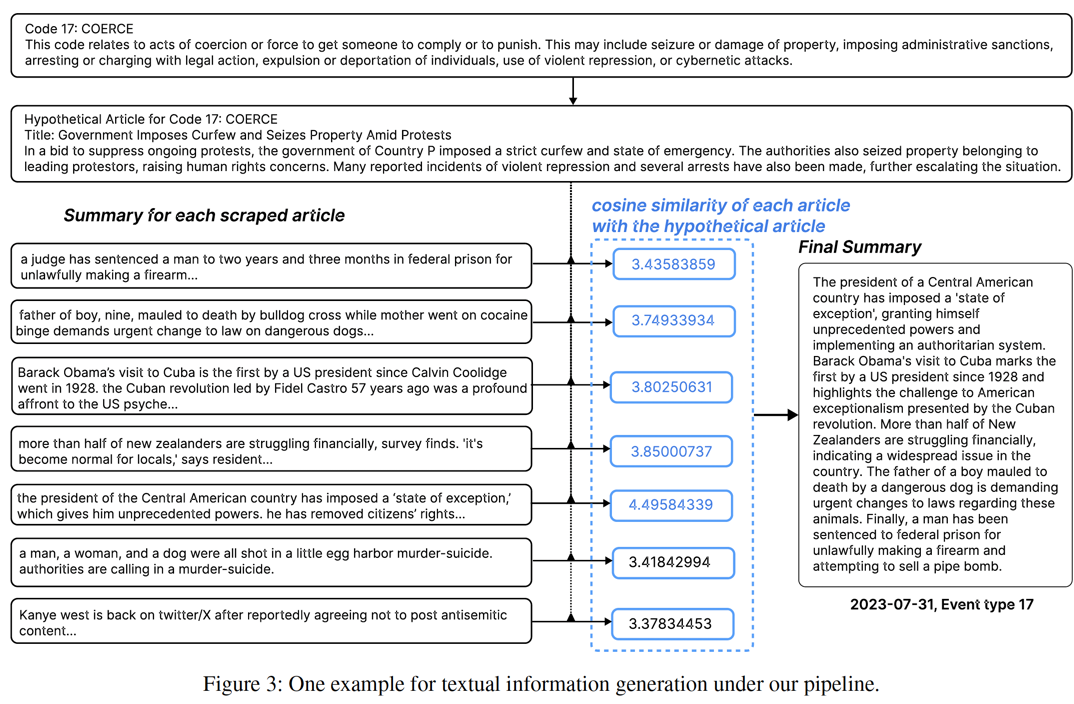
(2) Textual Data Collection
- 이벤트·지역·날짜별 10 news articles 수집
- Procedures
- Step 1) T5로 1차 Article-level summary 생성
- Step 2) Event type 기반 hypothetical summary 생성
- Step 3) Similarity 기반 re-rank
- Step 4) Top-5 summaries로 final summary 생성
- 주로 ChatGPT-3.5 API (일부는 비용 문제로 T5 사용)
- Noise Handling
- 1차 summary의 중복·무의미 정보 문제 존재
- Re-ranking으로 관련도 낮은 summary 제거
- 품질이 낮은 final summary는 scraped title summary로 대체
(3) Dataset Purpose
- 이벤트 attention dynamics 및 regional impact 예측
- multimodal TS dataset generation pipeline의 실효성 검증
4. Architecture: GPT4MTS