
Sequence Packing
https://huggingface.co/blog/sirluk/llm-sequence-packing
https://arca.live/b/alpaca/127995776
Overview
1. Motivation
Training LLM: Computationally demanding task
\(\rightarrow\) One solution: Use of packed sequences
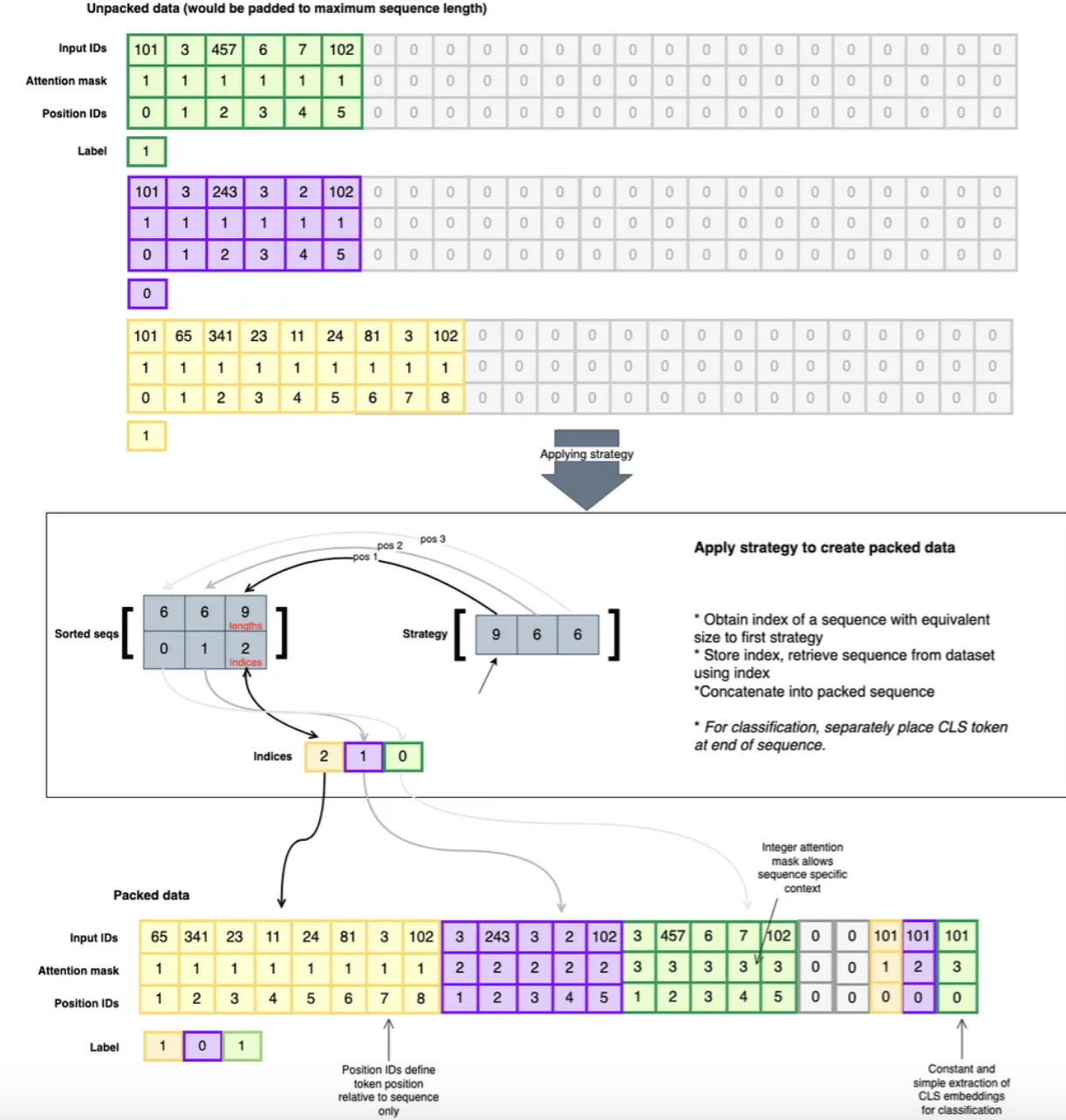
Previous works: padding
- Shorter sequences are padded with special tokens
- It wastes GPU memory by attending to meaningless padding tokens
2. Solution: Sequence packing
How?
- Instead of padding …
- Concatenate multiple shorter sequences into a single longer sequence!
Effect:
-
Minimizes wasted compute (through padding tokens)
-
Allows us to process more tokens per batch
\(\rightarrow\) Reduce training time!
Aware!
- Need to ensure the model doesn’t attend across sequence boundaries
3. Example
Example:
- Packing together the following three sentences
- into a single sequence
- separated by EOS tokens
a) Setup
# Setup
import torch; torch.set_printoptions(linewidth=200)
from transformers import AutoTokenizer, AutoConfig, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("gpt2")
config = AutoConfig.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_config(config)
b) Tokenize (3 seq \(\rightarrow\) 1 seq)
sentence1 = "The cat sat on the mat"
sentence2 = "The dog ate my homework"
sentence3 = "My aunt is a teacher"
sentences = [sentence1, sentence2, sentence3]
tokenized_sentences = tokenizer(sentences, return_attention_mask=False,
add_special_tokens=False)["input_ids"]
tokenized_sentences = [t for s in tokenized_sentences for t in s + [tokenizer.eos_token_id]]
tokenizer.decode(tokenized_sentences)
After decoding…
The cat sat on the mat<|endoftext|>The dog ate my homework<|endoftext|>My aunt is a teacher<|endoftext|>
c) Attention mask
Standard attention mask for causal language modeling for the packed sequences:

Need to truncate the attention mask in a certain way!

4. Adjust position ids accordingly
Important to adjust the position ids use to create position embeddings accordingly!
\(\rightarrow\) Helps the model understand the token’s relative position!
Need to ensure that the position IDs for each sequence start from the beginning (usually 0 or 1) !!
import torch
T = 10
# 문장 종료 인덱스 (inclusive)
eos_indices = torch.tensor([2, 6, 9]) # 문장1: 0~2, 문장2: 3~6, 문장3: 7~9
start_indices = torch.cat([torch.tensor([0]), eos_indices + 1])[:-1] # [0, 3, 7]
# 각 문장의 길이
reps = torch.tensor([3, 4, 3]) # 총합 = 10 == T
# pos_ids 계산
pos_ids = torch.arange(T) - torch.repeat_interleave(start_indices, reps)
print(pos_ids)
tensor([0, 1, 2, 0, 1, 2, 3, 0, 1, 2])
5. Batch
What if entire batch of sequences?
How to do it without a loop?
s1 = "Rome wasn't built in a day"
s2 = "My hovercraft is full of eels"
S = [s1, s2]
token_S1 = tokenizer(S, return_attention_mask=False, add_special_tokens=False)["input_ids"]
token_S1 = torch.tensor([t for s in token_S1 for t in s + [tokenizer.eos_token_id]])
##################################################################
s3 = "Rome wasn't built in a day"
s4 = "My hovercraft is full of eels"
S = [s3, s4]
token_S2 = tokenizer(S, return_attention_mask=False, add_special_tokens=False)["input_ids"]
token_S2 = torch.tensor([t for s in token_S2 for t in s + [tokenizer.eos_token_id]])
##################################################################
batch = torch.nn.utils.rnn.pad_sequence(
[token_S1, token_S2],
batch_first=True, padding_value=tokenizer.eos_token_id
)