( reference : Machine Learning Data Lifecycle in Production )
Collecting Data
[1] Importance of Data
Outline
- importance of DATA QUALITY
- Data pipeline consists of..
- (1) data COLLECTION
- (2) data INGESTION
- (3) data PREPARATION
- continuously MONITOR data collection
Every starts with DATA!
- garbage in, garbage out
- models aren’t magic!
- need to translate user’s needs into data problems
Meaningful data
- Maximize predictive content
- Remove non-informative data
- feature space coverage
[2] Knowing your data
Key considerations
- (1) data availability & collection
- what / how much data is available?
- how often is it refreshed?
- is it labeled?
- (2) translate users’ needs to data needs
- data / features / labels
Know your data!
- identify the data sources
- check if they are refreshed
- check consistencey
- values / units / data types
- keep monitor your data!
Measure Data Effectiveness
- check feature importance
- does it help prediction?
- Feature Engineering & Feature Selection :
- Feature Engineering : helps maximize predictive signals
- Feature Selection : helps measure predictive signals
Summary : understand your user’s need! translate into DATA PROBLEMS
[3] Responsible Data : Security, Privacy, Fairness
Outline
- Data Sourcing
- Data Security & User Privacy
- Bias & Fairness
Avoid problmeatic biases in datasets!
- example )

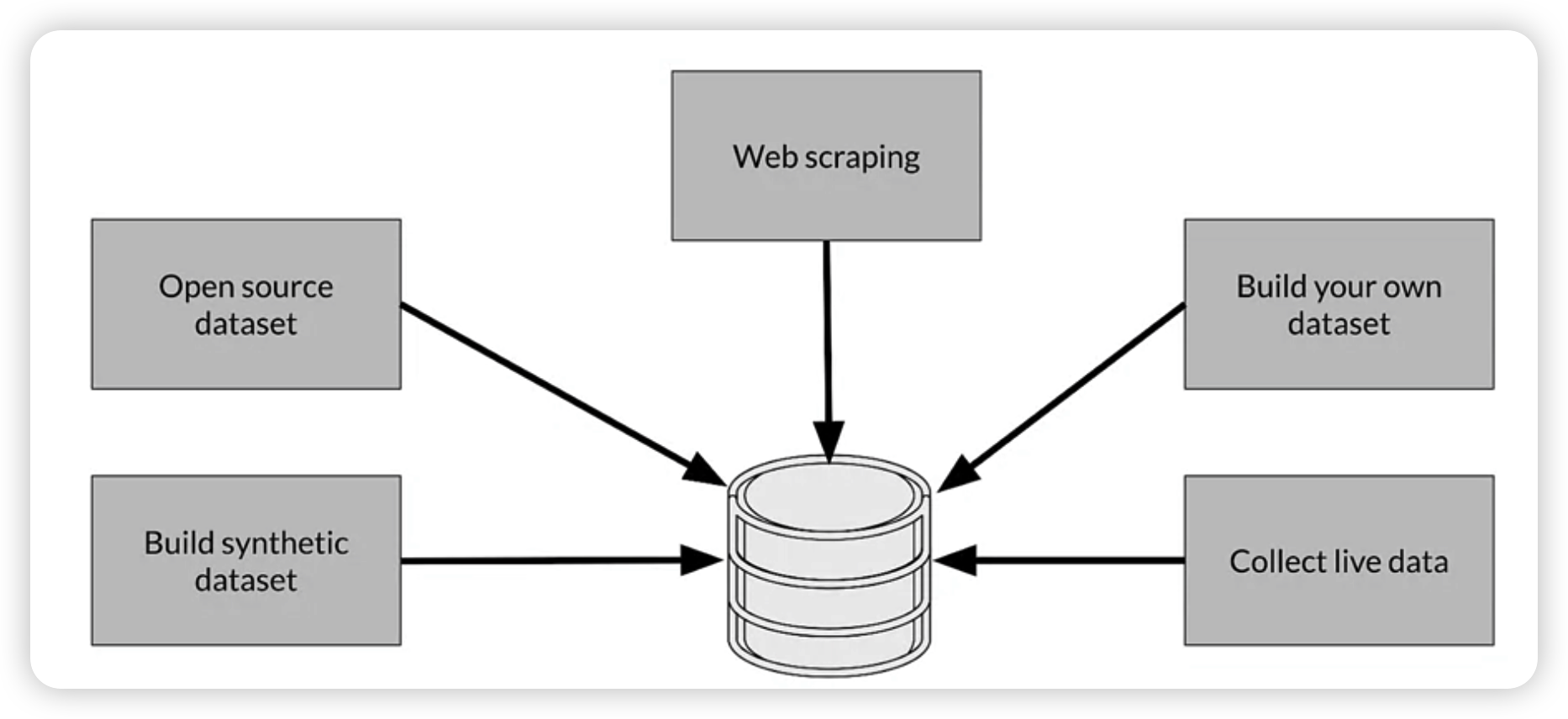
Source Data responsibly
- data may come from many different sources!
- need to think about where it came from
Data Security & Privacy
- give user control of what data can be collected
- comply with regulations & policies ( ex. GDPR )
User Privacy
- protect personally identifiable information
- Solution :
- (1) aggergation : summary individual values
- (2) redaction : remove som data, to create less complete picture
Fairness
your model needs to be fair!
- group fairness, equal accuracy
may be bias in human labeled data & ML models might ampliy it!!
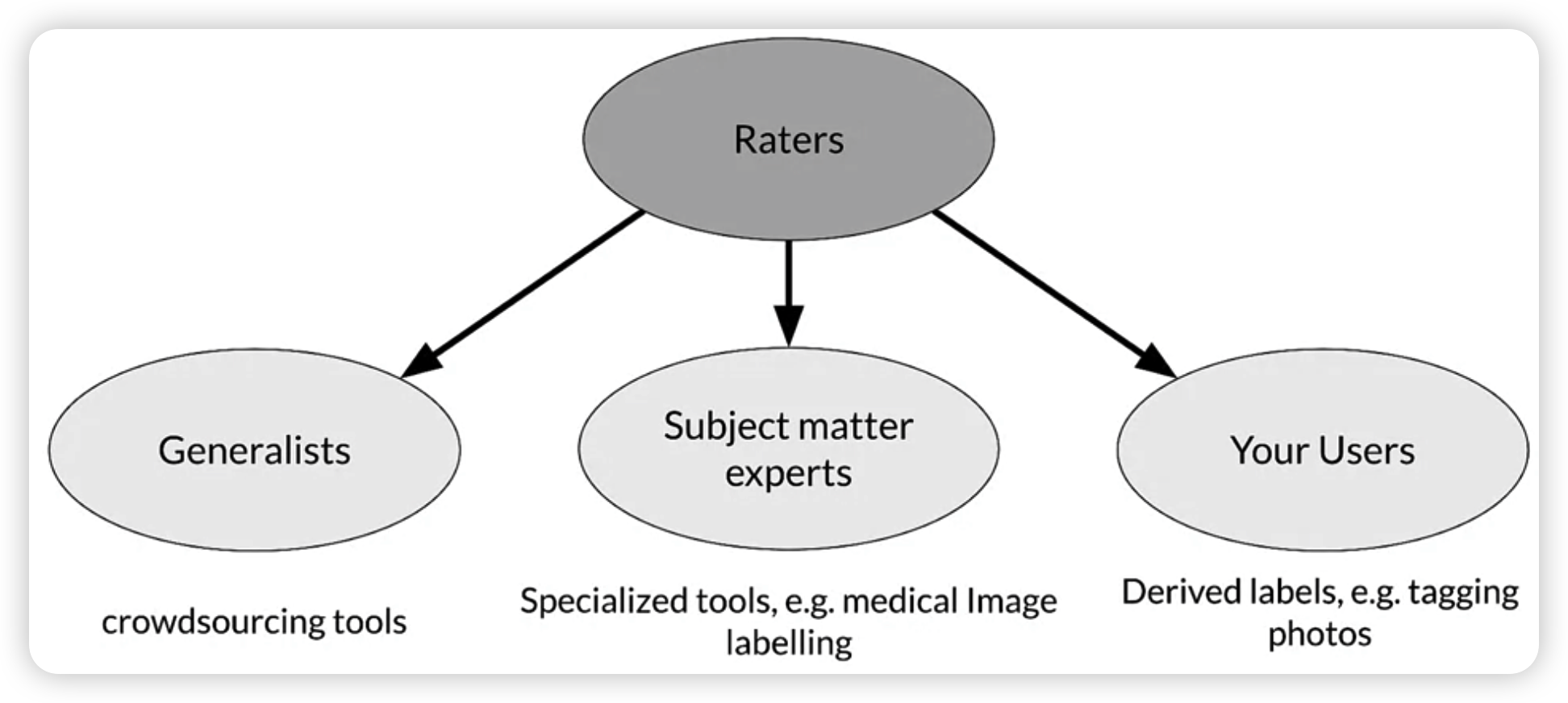
Human Labeled data
who are the raters?
-> depends on the data!