
( reference : Machine Learning Data Lifecycle in Production )
Feature Selection
[1] Feature Spaces
Outline
- What is Feature Space
- Introduction to Feature Selection
- Feature Selection Methods
- (1) filter methods
- (2) wrapper methods
- (3) embedded methos
Feature Space
-
$N$ features $\rightarrow$ $N$ dimension feature space
( do not include target label )
Feature Space Coverage
IMPORTANT : ensure feature space coverage!!
-
train & evaluation datasets’ feature coverage $\approx$ serving dataset’s feature coverage
-
same feature coverage =
- same numerical ranges
- same classes
- similar characteristics of data ( IMAGE )
- simliar vocab, syntax, semantics ( NLP )
Challenges
- Data is affected by …. seasonality / trend / drift
- New values in features & labels in serving data
$\rightarrow$ thus, need CONTINUOUS MONITORING
[2] Feature Selection
- identify features’ correlation
- remove unimportant features
- reduce dimension of feature space
Why??
Feature Selection methods
- Unsupervised
- remove redundant features
- Supervised
- select most contributing features
- ex) filter methods, wrapper methods, embedded methods
[3] Filter Methods

Filter Methods
- (1) correlation
- (2) univariate feature selection
(1) correlation
- high correlation $\rightarrow$ redundant information
- draw correlation matrix
- ex) Pearson Correlation, Univariate Feature Selection
(2) Univariate feature selection
( feat. Sklearn )
Univariate Feature Selection Routines
SelectKBestSelectPercentileGenericUnivariateSelect
Statistical tests
- Regression :
f_regression,mutual_info_regression - Classification :
chi2,f_classif,mutual_info_classif
from sklearn.feature_selection import SelectKBest, chi2
selector = SelectKBest(chi2, k=20)
X_new = selector.fit_transform(X, y)
X_new_feature_idx = selector.get_support()
[4] Wrapper Methods
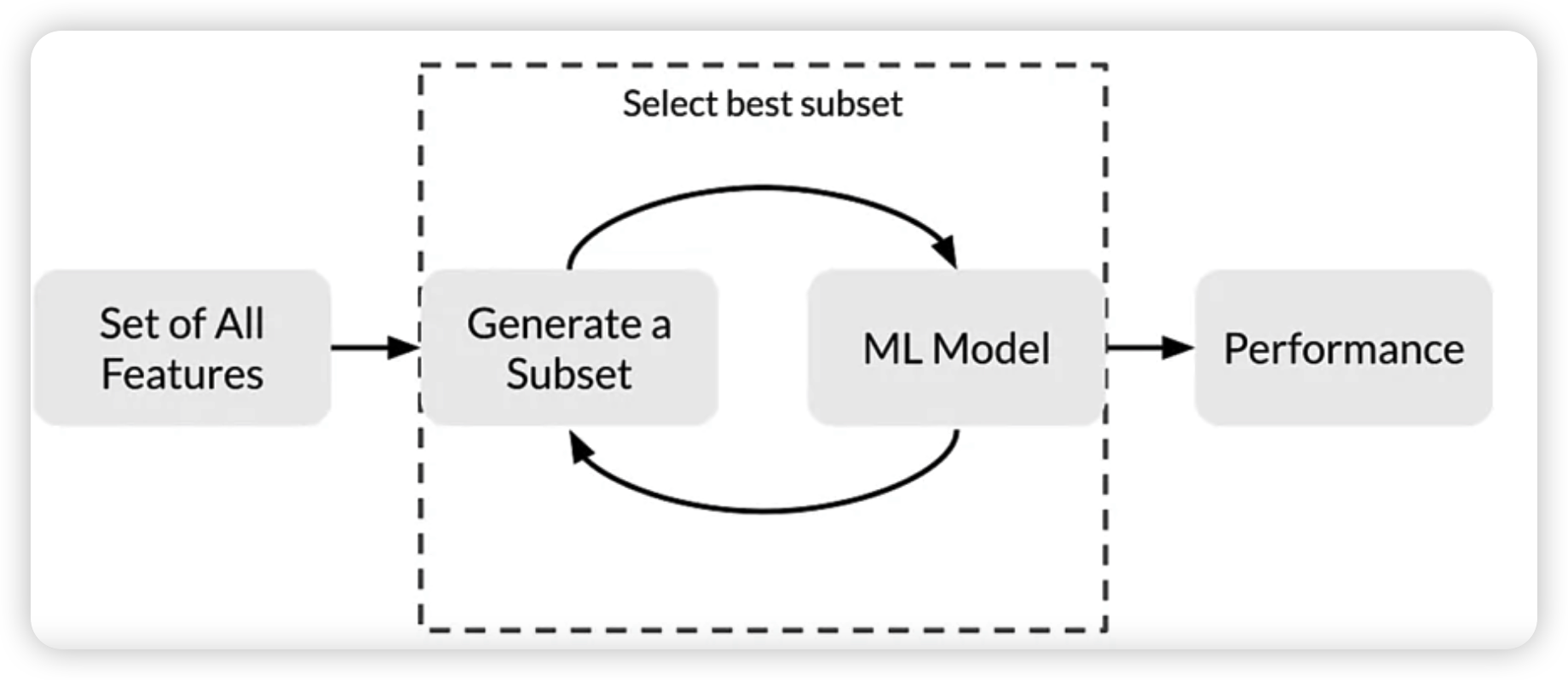
Wrapper Methods
- (1) Forward Selection
- (2) Backward Elimination
- (3) Recursive Feature Elimination
(1) Forward Selection
Iterative, Greedy method
-
start with 1 feature
-
evaluate model performance,
when ADDING each of additional features ( one at a time )
-
add next feature,
that gives the BEST performance
-
Repeat until no improvement
(2) Backward Elimination
-
start with ALL features
-
evaluate model performance,
when REMOVING each feature ( one at a time )
-
Remove next feature,
that gives the WORST performance
-
Repeat until no improvement
(3) Recursive Feature Elimination
-
select model ( JUST FOR measuring FEATURE IMPORTANCE )
- select desired # of features
- fit the model
- Rank features by importance
- discard least important features
- repeat until desired # of features remains
from sklearn.feature_selection import RFE
from sklearn.ensemble import RandomForestClassifier
K = 20
model = RandomForestClassifier()
rfe = RFE(model, K)
rfe = rfe.fit(X,y)
X_features_idx = rfe.get_support()
X_features = X.columns[X_features_idx]
[5] Embedded Methods
Embedded Methods
- (1) L1 regularization
- (2) Feature Importance
- scores for each feature in data
- discard features with low feature importance
model = RandomForestClassifier()
model = model.fit(X,y)
FI = model.feature_importances_
print(FI)
FI.nlargest(10).plot(kind='barh')