
Concept & Data Drift
(reference : https://towardsdatascience.com/machine-learning-in-production-why-you-should-care-about-data-and-concept-drift-d96d0bc907fb)
Problem : corrupted, late, or incomplete data
\(\rightarrow\) solved…then is it OK? that’s not all !!
Contents
- Model decay
- Data drift
- Concept drift
- How to deal with drift?
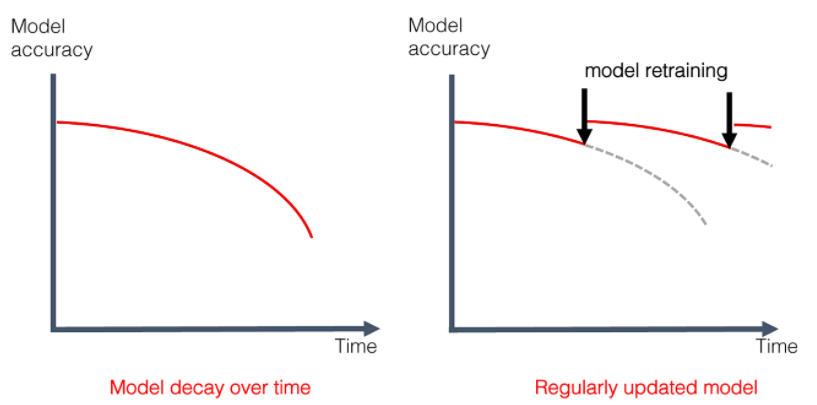
1. Model decay
Past performance is no guarantee of future results
= model drift / model decay / staleness
Reason :
- 1) data drift
- 2) concept drift
Retraining might help!
2. Data Drift
( Data drift = feature drift = population/covariate shift )
input data has changed!
- old model might not be suitable for new data!
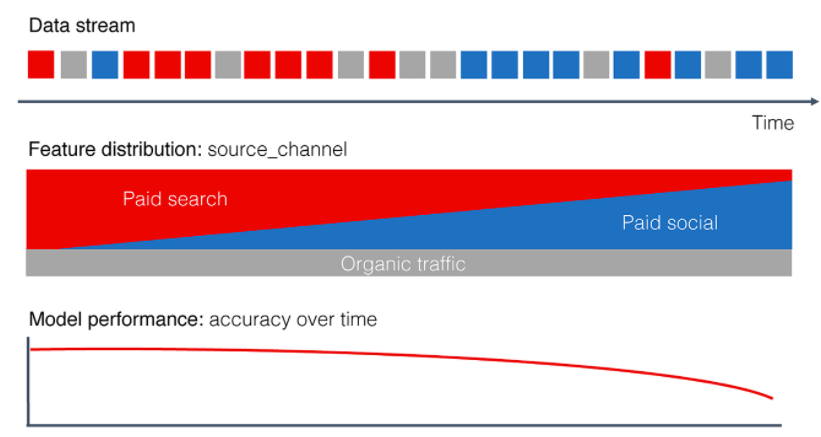
Example 1) online advertising
-
task : want to predict how likely they will make a purchase
-
feature distribution of “source channel” might change over time!
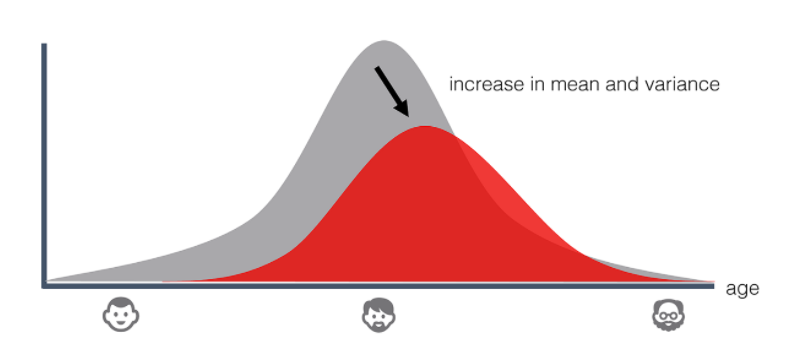
Example 2) Demographic change
- people get old over time!
“Degree of decay” depends on the task!
Training-serving skew
Cause of skew is different from data drift!
( actually, there is no “drift”, but more like “mismatch” )
Example )
- TRAIN on artificially constructed or cleaned dataset
- INFERENCE on real-world dataset

3. Concept Drift
patterns ( relation of X & Y ) the model learned changes
a) gradual concept drift

follows the gradual changes in “external factors”
examples )
- competitor launches new products
- macroeconomic conditions change
individual change might be small, but big as a whole
b) sudden concept drift
example) COVID-19
-
shopping patterns changed suddenly!
\(\rightarrow\) change in “demand forecast”
4. How to deal with drift?
Need to “RETRAIN” the model!
- method 1) Retrain the model using all available data
- method 2) Retrain the model using all available data + higher weight on new data
- method 3) Retrain the model using NEW data
other options
- domain adaptations
- building a composition of models taht use BOTH old & new data
- entirely new architecture
- …