
Large Language Models: A Survey (Part 1)
https://arxiv.org/pdf/2402.06196
Abstract
Recent trends in LLMs
- Strong performance on a wide range of NLP tasks
- e.g., ChatGPT: 2022.11
- Training billions of model’s parameters & massive amounts of text data
- feat. Scaling laws
This paper:
-
(1) 3 LLM families (GPT, LLaMA, PaLM)
- (2) Techniques to build/augment LLMs
- (3) Popular datasets
- (4) LLM evaluation metrics
1. Introduction
P1) Language modeling (LM)
- Pass
P2) Transformer-based LLMs
- [Dataset] Pretrained on Web-scale text corpora
- [Example] ChatGPT and GPT-4
LLM is the basic building block for …
$\rightarrow$ The development of general-purpose AI agents or artificial general intelligence (AGI) !!
P3) Challenges
- Challenging to figure out the best recipes to build LLM-powered AI systems
P4) Four waves of recent success of LLMs
- (1) Statistical LM
- (2) Neural LM
- (3) Pre-trained LM
- (4) Large LM
P5) (1) Statistical language models (SLMs)
-
Text = Sequence of words
$\rightarrow$ Probability of text = Product of their word probabilities
-
e.g.) Markov chain models ( = “n-gram” models )
- Smoothing: To deal with “data sparsity”
- (i.e., assigning zero probabilities to unseen words or n-grams)
- Smoothing: To deal with “data sparsity”
-
Limitation: Sparsity
$\rightarrow$ Cannot fully capture the diversity of language!
P6) (2) Neural language models (NLMs)
- Handle “Data sparsity”
- Map words to embedding vectors
- Next word prediction
- Based on the aggregation of its preceding words using NN
P7) (3) Pre-trained language models (PLMs)
- Task-agnostic
- Pre-training & fine-tuning
- (1) Pre-trained
- On large scale dataset
- For general tasks (e.g., word prediction)
- (2) Fine-tuned
- To specific tasks
- Using small amounts of (labeled) task-specific data
- (1) Pre-trained
P8) (4) Large language models (LLMs)
- (Mainly refer to) Transformer-based NLMs
- Contain tens to hundreds of billions of parameters
- Pretrained on massive text data
- Ex) PaLM , LLaMA , and GPT-4
- (Compared to PLM) Much larger in model size & better performance
- emergent abilities that are not present in smaller-scale language models
- Emergent abilities
- (1) In-context learning
- Learn a new task from a small set of examples presented in the prompt at inference time
- (2) Instruction following
- (After instruction tuning) Follow the instructions for new types of tasks without using explicit examples
- (3) Multi-step reasoning
- Solve a complex task by breaking down that task into intermediate reasoning steps
- (1) In-context learning
- Augmentation
- LLMs can also be augmented by using external knowledge and tools
- Effect
- Can effectively interact with users and environment
- Can continually improve itself using feedback data collected through interactions (e.g. via RLHF)
P9) AI agents
-
LLMs can be deployed as so-called AI agents
-
AI agents?
= Artificial entities that sense their environment, make decisions, and take actions
-
AI agent researches
- (Previous) Agents for specific tasks and domains
- (Recent) General-purpose AI agents based on LLMs ( feat. Emergent abilities )
-
LLM vs. AI Agent
-
LLMs: Trained to produce responses in static settings
-
AI agents: Need to take actions to interact with dynamic environment
$\rightarrow$ $\therefore$ LLM-based agents often need to augment LLMs!
- e.g., Obtain updated information from external knowledge bases
- e.g., Verify whether a system action produces the expected result
- e.g., Cope with when things do not go as expected
-
P10) Section Introduction
- Section II: Overview of SOTA LLMs ( Three LLM families (GPT, LLaMA and PaLM) )
- Section III: How LLMs are built
- Section IV: How LLMs are used, and augmented for real-world applications
- Sections V and VI: Popular datasets and benchmarks for evaluating LLMs
- Section VII: Challenges and future research directions
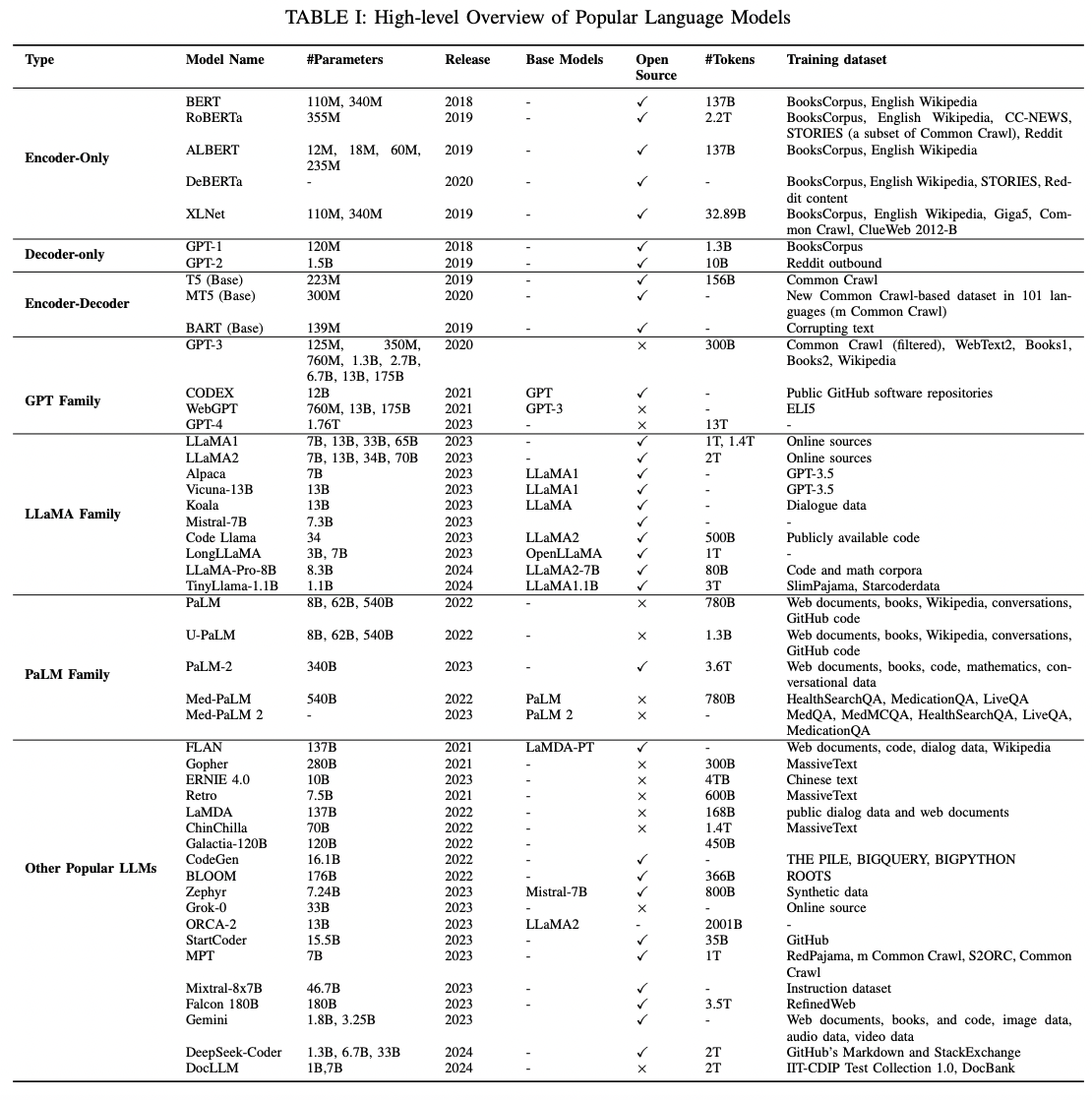
2. LLM
- Review of early pre-trained neural language models ( = base of LLMs )
- Focus our discussion on three families of LLMs ( GPT, LlaMA, and PaLM )
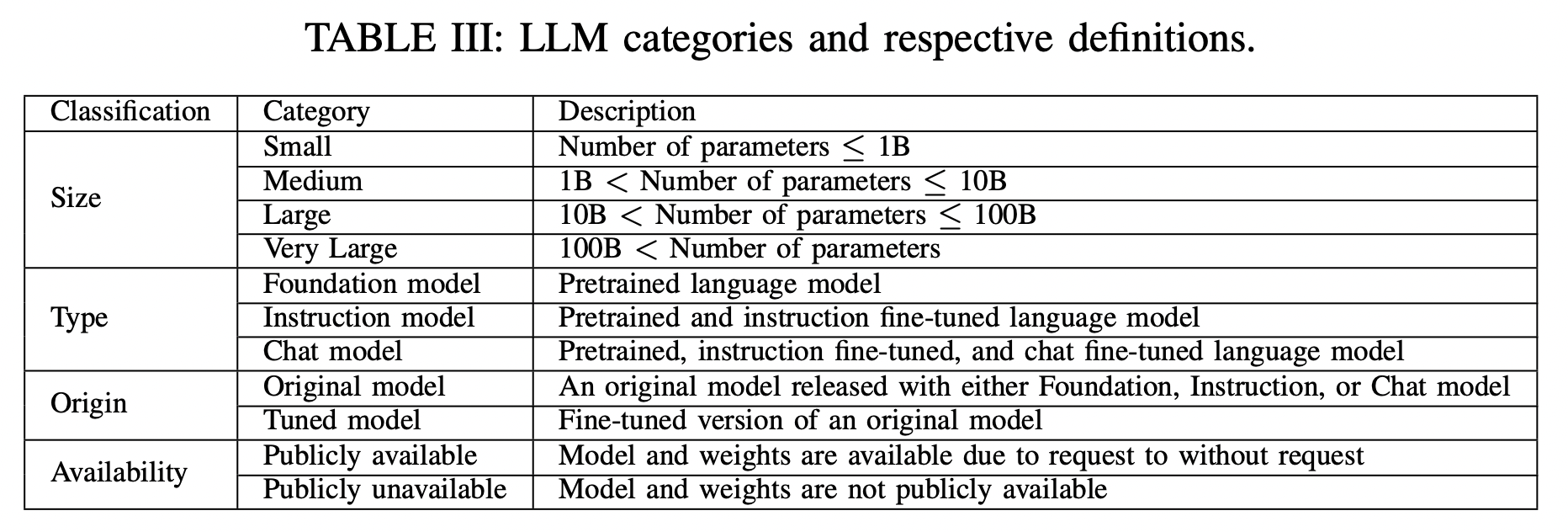
(1) Early Pre-trained Neural Language Models
P1) History of NLMs
[13] : First neural language models (NLMs)
[14] : Applied NLMs to machine translation
[41] : RNNLM (an open source NLM toolkit)
[42] : Popularize NLMs
[After] NLMs based on RNNs (& variants) were widely used
- E.g., Machine translation, text generation and text classification
P2) Invention of Transformer
-
Transformer = Allow for much more parallelization than RNNs
-
Development of Pre-trained language models (PLMs)
( + Fine-tuned for many downstream tasks )
-
Three categories
- (1) Encoder-only
- (2) Decoder-only
- (3) Encoder-decoder models
P3) Transformer: Encoder-only PLMs
P3-1) Encoder-only?
- Only consist of an encoder network
- Developed for language understanding tasks
- e.g., Text classification
- e.g.) BERT & variants
- e.g., RoBERTa, ALBERT, DeBERTa, XLM, XLNet, UNILM
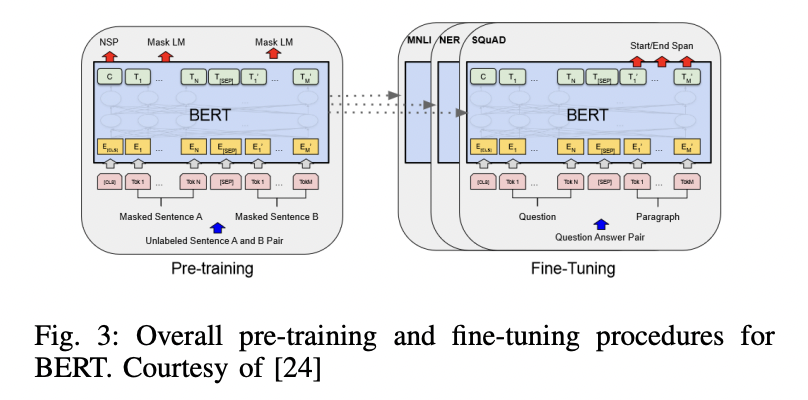
P3-2) BERT
BERT (Birectional Encoder Representations from Transformers)
- 3 modules
- (1) Embedding module
- Input text $\rightarrow$ Sequence of embedding vectors
- (2) Stack of Transformer encoders
- Embedding vectors $\rightarrow$ Contextual representation vectors
- (3) Fully connected layer
- Representation vectors $\rightarrow$ One-hot vectors
- (1) Embedding module
- 2 pretraining tasks
- (1) Masked language modeling (MLM)
- (2) Next sentence prediction (NSP)
- Finetuning
- Can be fine-tuned by adding a classifier layer
- e.g., Text classification, question answering to language inference
 .
.
P3-3) RoBERTa, ALBERT, DeBERTa, ELECTRA, XLMs
RoBERTa (A Robustly Optimized BERT Pretraining Approach)
- Improves the robustness of BERT
- Key changes
- (1) Modify a few key hyperparameters
- (2) Remove the NSP task
- (3) Train with much larger mini-batches and learning rates
ALBERT (A Lite BERT for Self-supervised Learning of Language Representations)
-
Two parameter-reduction techniques
- (1) Split the embedding matrix $\rightarrow$ Into two smaller matrices
- (2) Repeating layers split among groups
$\rightarrow$ Lower memory consumption & increase the training speed of BERT
DeBERTa (Decoding-enhanced BERT with disentangled attention)
- Improves the BERT and RoBERTa models
- Two novel techniques
- (1) Disentangled attention mechanism
- Each word = Two vectors that encode its (a) content & (b) position
- Attention weights among words are computed using disentangled matrices on their contents and relative positions
- (2) Enhanced mask decoder
- To incorporate absolute positions in the decoding layer
- (1) Disentangled attention mechanism
- (During fine-tuning) Novel virtual adversarial training method
- To improve models’ generalization.
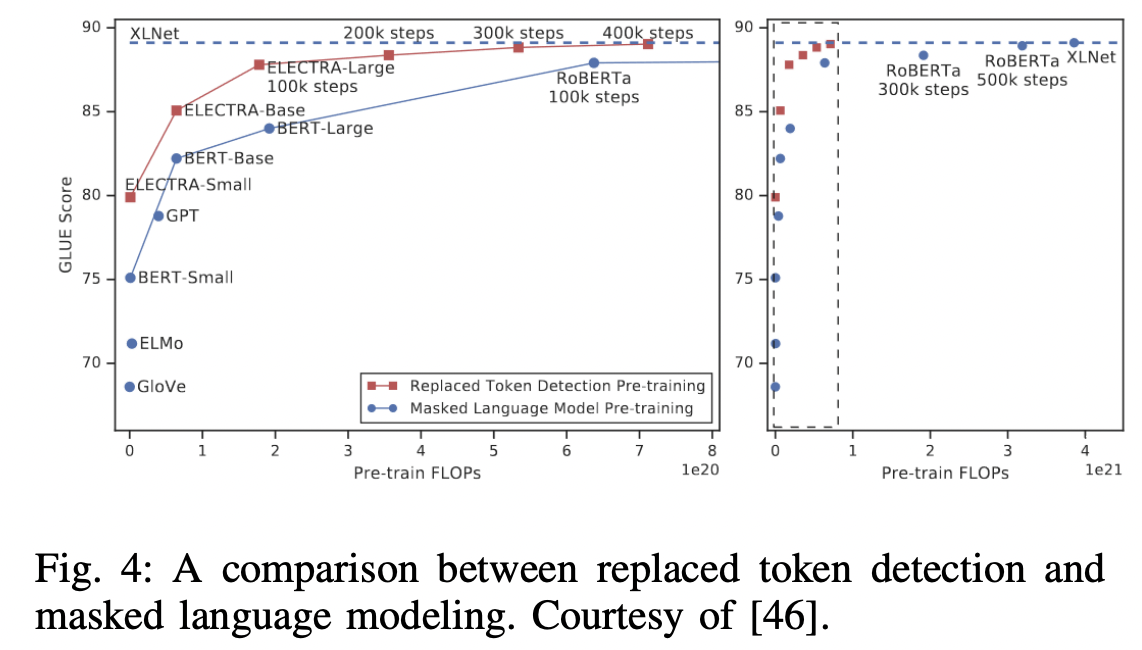
ELECTRA
- (New pre-training task) Replaced Token Detection (RTD)
- MLM vs. RTD
- a) Target token
- (MLM) Mask the input
- (RTD) Corrupts it by replacing some tokens with plausible alternatives (sampled from a small generator network)
- b) Prediction
- MLM: Predicts the original identities of the corrupted tokens
- RTD: Discriminative model is trained to predict whether a token in the corrupted input was replaced by a generated sample or not
- a) Target token
- Effectivenss of RTD
- More sample-efficient than MLM
- RTD: Defined over all input tokens
- MLM: Only small subset being masked out
- More sample-efficient than MLM
P3-4) XLMs
- Extend BERT to “cross-lingual” language models
- Two methods
- (1) Unsupervised method: Relies on “monolingual” data
- (2) Supervised method: Leverages parallel data with a new “cross-lingual” language model objective
- SOTA results
- E.g., Cross-lingual classification, unsupervised and supervised machine translation

P3-5) XLNet & UNILM
( = Encoder-only + Advantages of decoder models )
XLNet
-
Based on Transformer-XL
-
Pre-trained using a generalized “autoregressive” method
-
Enables learning bidirectional contexts
by maximizing the expected likelihood over “all permutations of the factorization order”
-
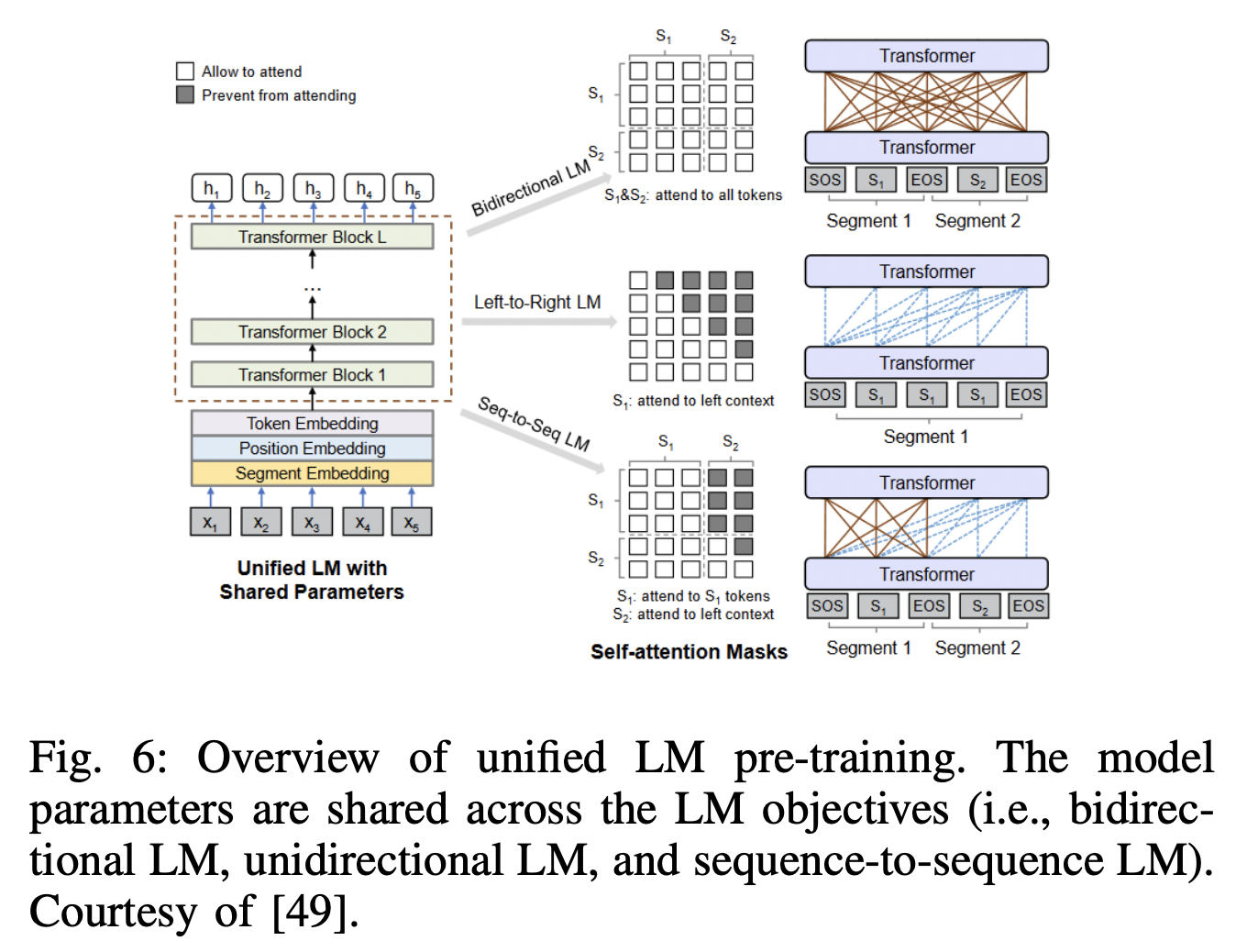
**UNILM (UNIfied pre-trained Language Model) **
-
Pre-trained using three types of language modeling tasks
- (1) Unidirectional prediction
- (2) Bidirectional prediction
- (3) Sequence-to-sequence prediction
$\rightarrow$ By employing a shared Transformer network & utilizing specific self-attention masks
- Mask: to control what context the prediction is conditioned on!
P4) Transformer: Decoder-only PLMs
Example: GPT-1 and GPT-2 (by OpenAI)
$\rightarrow$ Foundation to more powerful LLMs (e.g., GPT-3 and GPT-4)
P4-1) GPT1
- Decoder-only Transformer model
- [Pretrain] In a SSL fashion (e.g., Next word/token prediction)
- [Fine-tune] On each specific downstream task
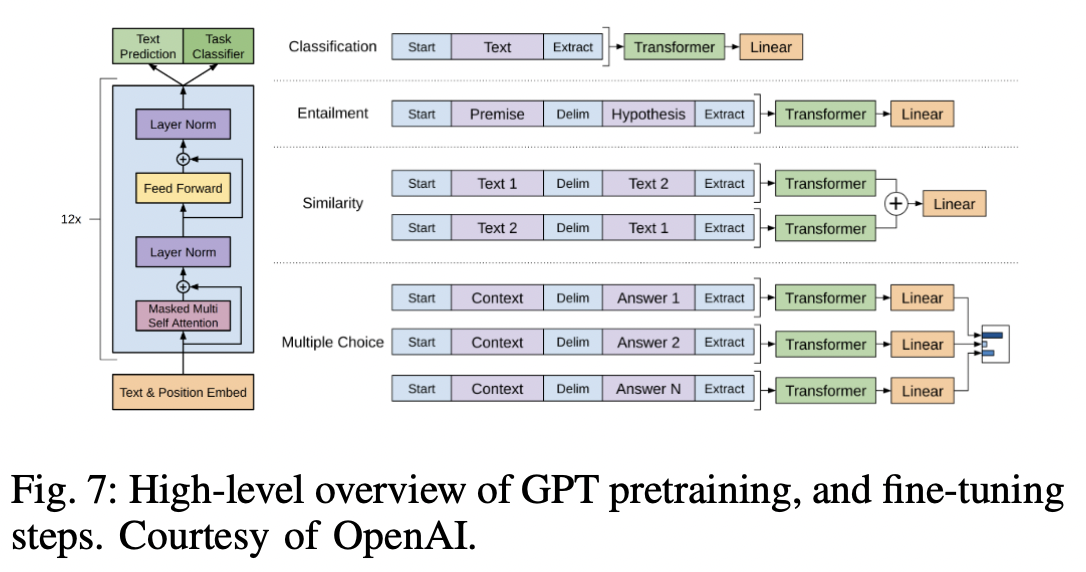
P4-2) GPT2
- Shows that LMs are able to learn to perform specific NLP tasks “w/o any explicit supervision”
- Dataset: large WebText dataset (consisting of millions of webpages)
- GPT-1 + $\alpha$:
- (1) Layer normalization: Moved to the input of each sub-block
- (2) Additional layer normalization: Added after the final self-attention block
- (3) Initialization: Modified to account for the accumulation on the residual path and scaling the weights of residual layers,
- (4) Vocabulary size: Expanded
- (5) Context size: Increased from 512 to 1024 tokens.
P5) Transformer: Encoder-Decoder PLMs
-
Shows that almost all NLP tasks can be cast as a “sequence-to-sequence” generation task
-
Unified model (as “Encoder-decoder framework”)
$\rightarrow$ Can an perform all (1) natural language understanding and (2) generation tasks
P5-1) T5 (Text-to-Text Transfer Transformer) & mT5
T5: Unified framework
( Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer )
- All NLP tasks are cast as a text-to-text generation task
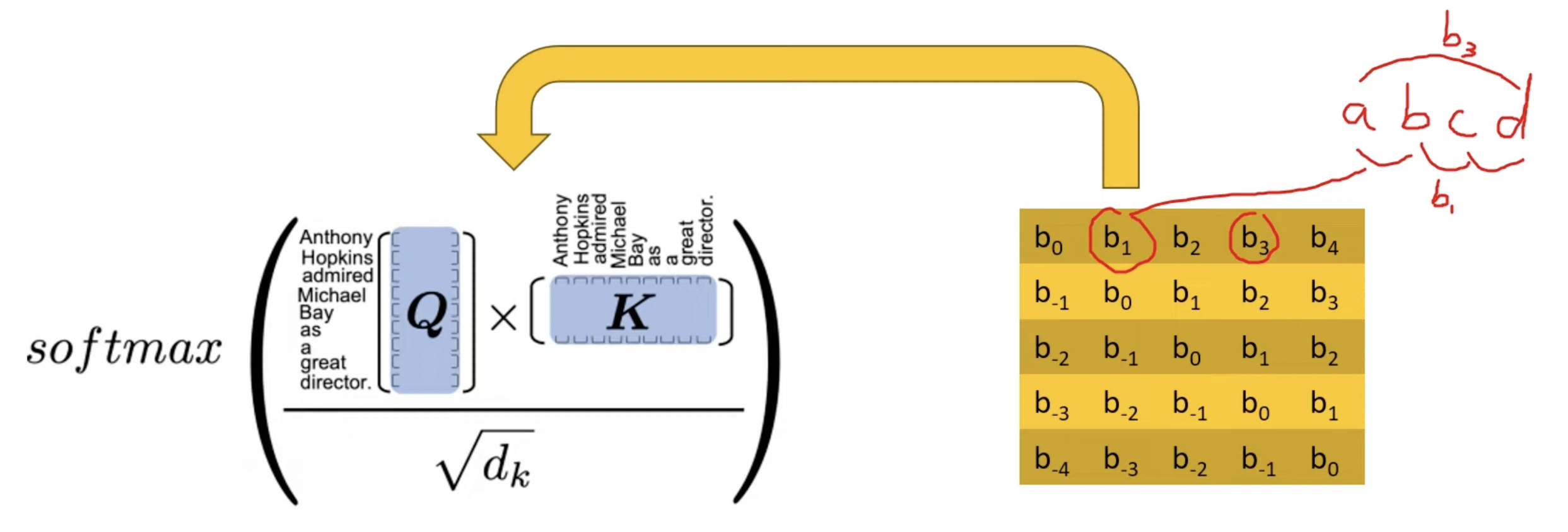
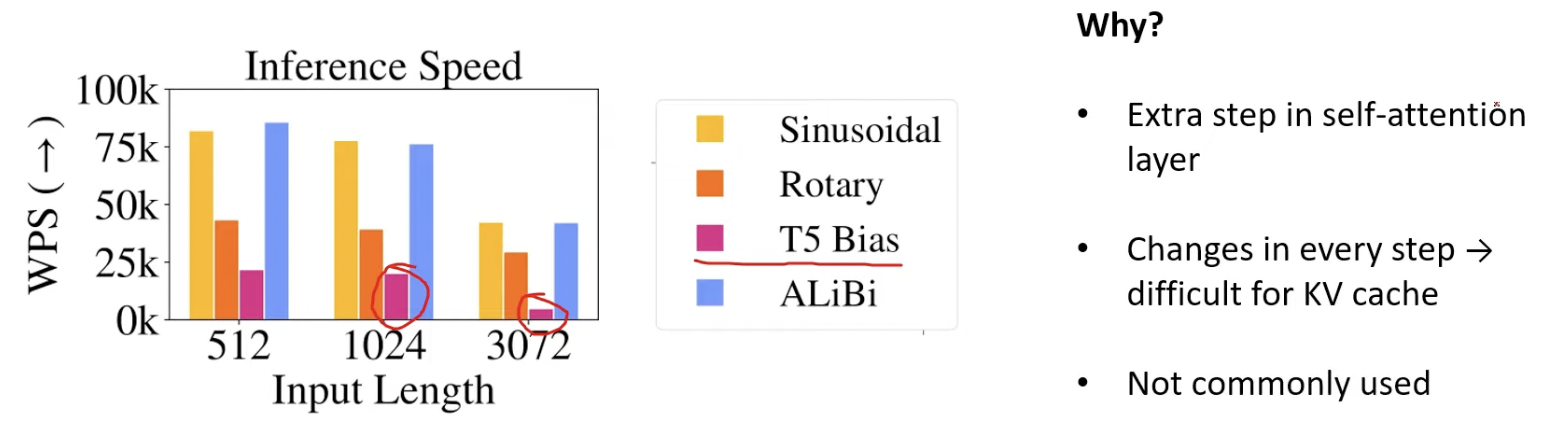
- Relative positional embedding (but slow)
mT5: Multilingual variant of T5
( mT5: A massively multilingual pre-trained text-to-text transformer)
- Pre-trained on a new Common Crawl-based dataset
- Consisting of texts in 101 languages
P5-2) MASS
( MASS: Masked Sequence to Sequence Pre-training for Language Generation )
-
[Pretraining task] Reconstruct a sentence fragment given the remaining part of the sentence
-
Encoder & Decoder
- [Encoder] Input = Masked sentence with randomly masked fragment
- [Decoder] Predicts the masked fragment
$\rightarrow$ Training: Jointly trains the encoder and decoder for language embedding and generation, respectively.
P5-3) BART
( BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension )
- Sequence-to-sequence translation model architecture
- [Pretraining task] Corrupt text with noise & Reconstruct the original text