Large Language Models: A Survey (Part 2)
https://arxiv.org/pdf/2402.06196
2. LLM
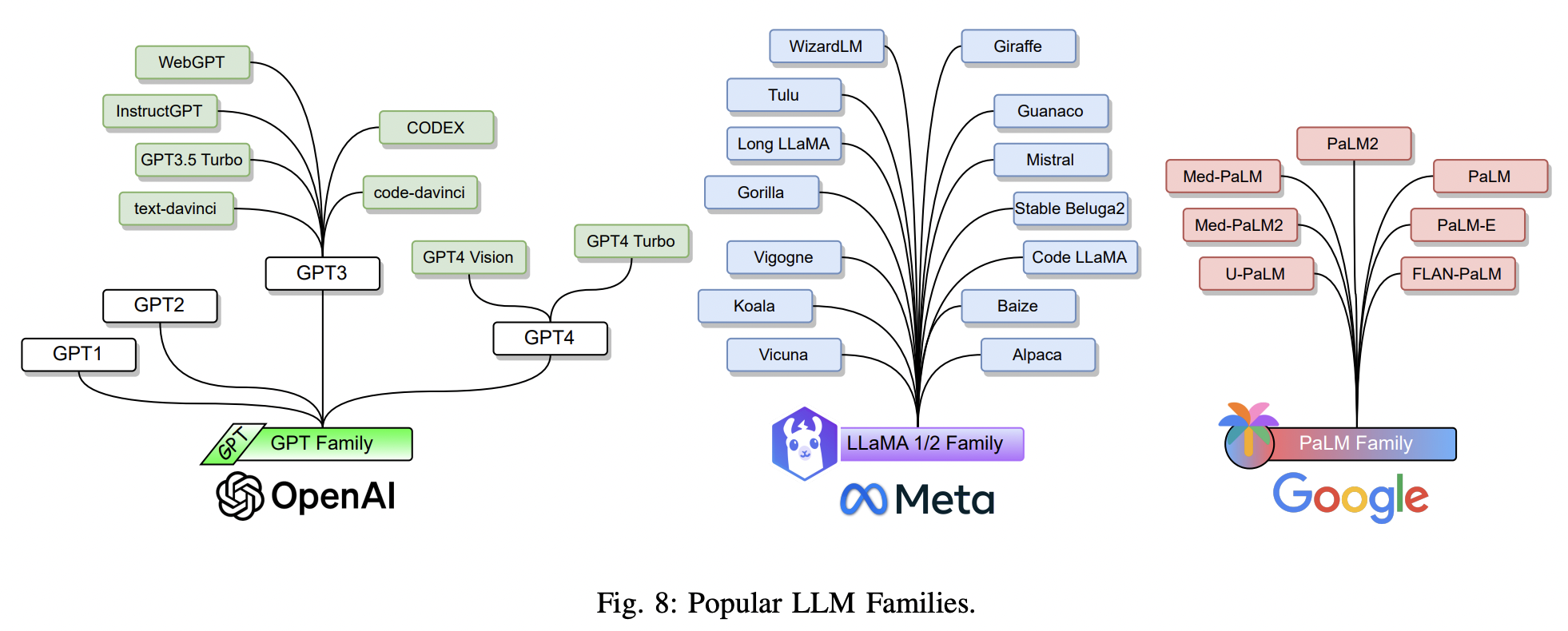
(2) LLM Families
P1) LLM
- Transformer-based PLM ( ~ hundreds of billions of parameters )
- Stronger language understanding and generation (vs. PLM)
- Emergent abilities that are not present in smaller-scale models
- Three LLM families
- (1) GPT
- (2) LLaMA
- (3) PaLM
P2) The GPT Family
Definition = Family of decoder-only Transformer-based language models ( by OpenAI )
- GPT-1, GPT-2, GPT-3, InstrucGPT, ChatGPT, GPT-4, CODEX, and WebGPT…
- [1] Early models
- GPT-1 and GPT-2
- Open Source
- [2] Recent models
- GPT-3 and GPT-4
- Closed source ( Only be accessed via APIs )
P2-1) GPT3
- 175 B params
- Widely considered as the first LLM in that ..
- (1) Much larger than previous PLMs,
- (2) First time demonstrates emergent abilities
- Shows the emergent ability of “in-context learning”
- (1) To any downstream tasks without any gradient updates or fine-tuning
- (2) Demonstrations specified purely via text interaction with the model.
- Strong performance on many NLP tasks
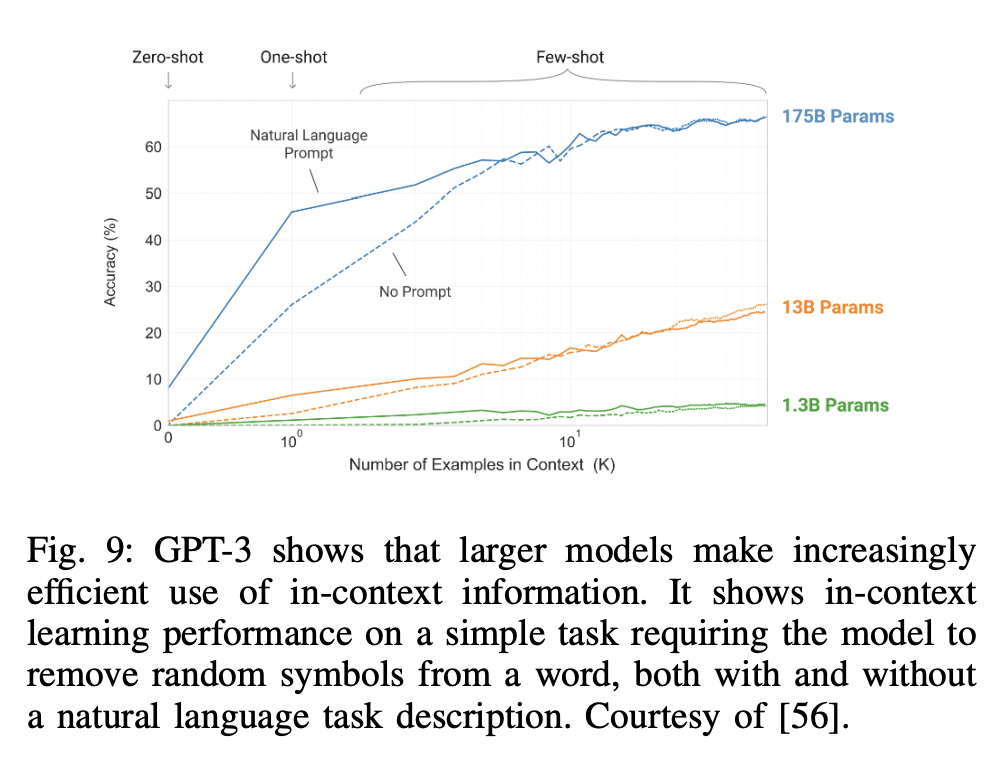
- Function of the number of examples in in-context prompts
P2-2) CODEX
-
Descendant of GPT-3 (by OpenAI in March 2023)
-
General-purpose “programming” model
- Parse natural language & Generate code
-
Fine-tuned for programming applications on code corpora collected from GitHub
\(\rightarrow\) CODEX powers Microsoft’s GitHub Copilot
P2-3) WebGPT
-
Descendant of GPT-3
-
Fine-tuned to answer open-ended questions using a text-based web browser
\(\rightarrow\) Facilitating users to search and navigate the web.
-
Trained in 3 steps
- Step 1) Learn to mimic human browsing behaviors
- Using human demonstration data.
- Step 2) Reward function
- Learned to predict human preferences
- Step 3) Reinforcement learning & Rejection sampling
- Refined to optimize the reward function
- Step 1) Learn to mimic human browsing behaviors
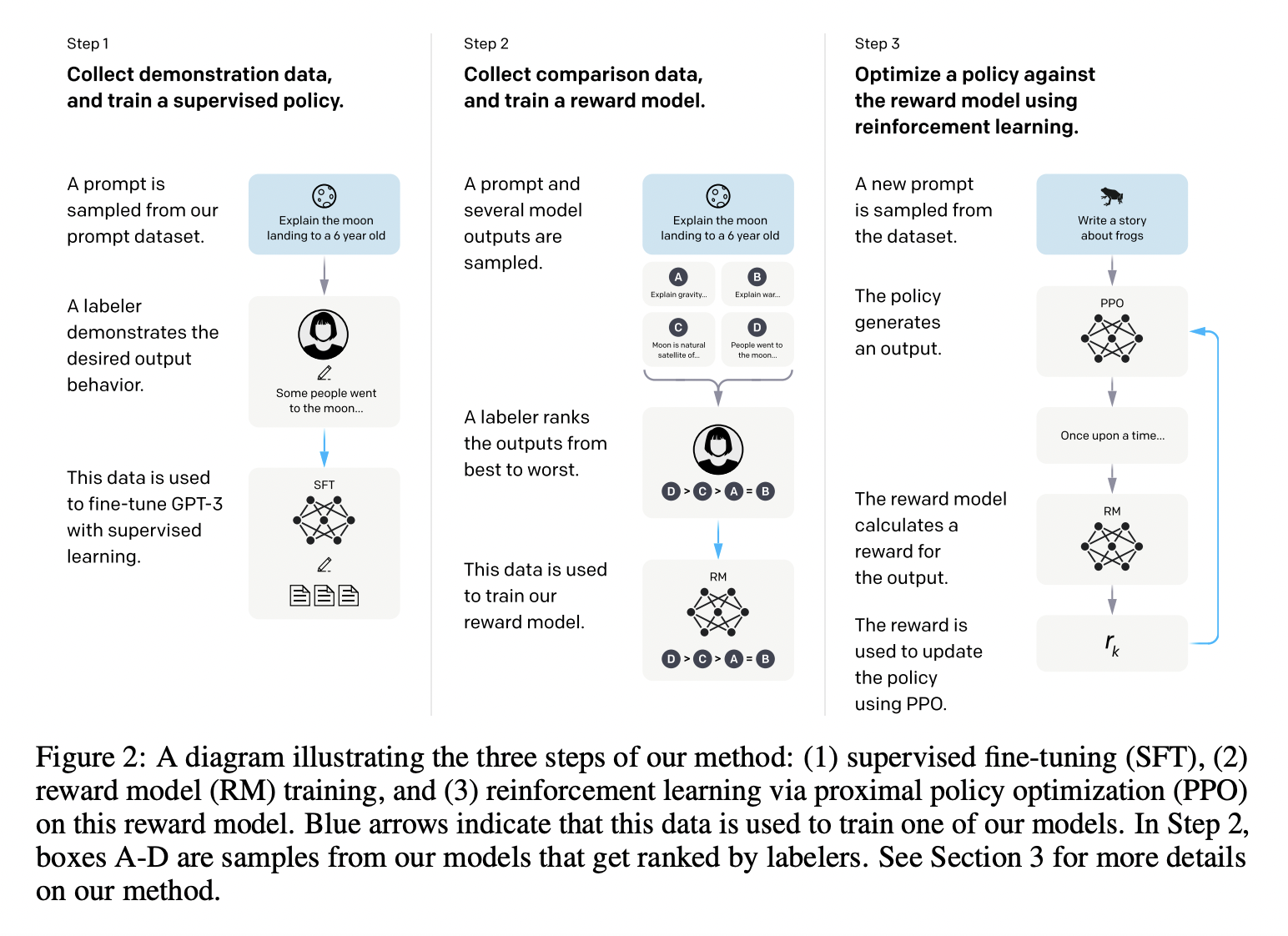
P2-4) InstructGPT
- Goal: To follow expected “human instructions”
- Align LLM with user intent on a wide range of tasks by fine-tuning with human feedback
- Reinforcement Learning from Human Feedback (RLHF)
P2-5) ChatGPT
- Most important milestone of LLM development (November 30, 2022)
- Chatbot: Wide range of tasks (such as question answering, information seeking, text summarization…)
- Powered by GPT-3.5 (and later by GPT-4) (= a sibling model to InstructGPT)
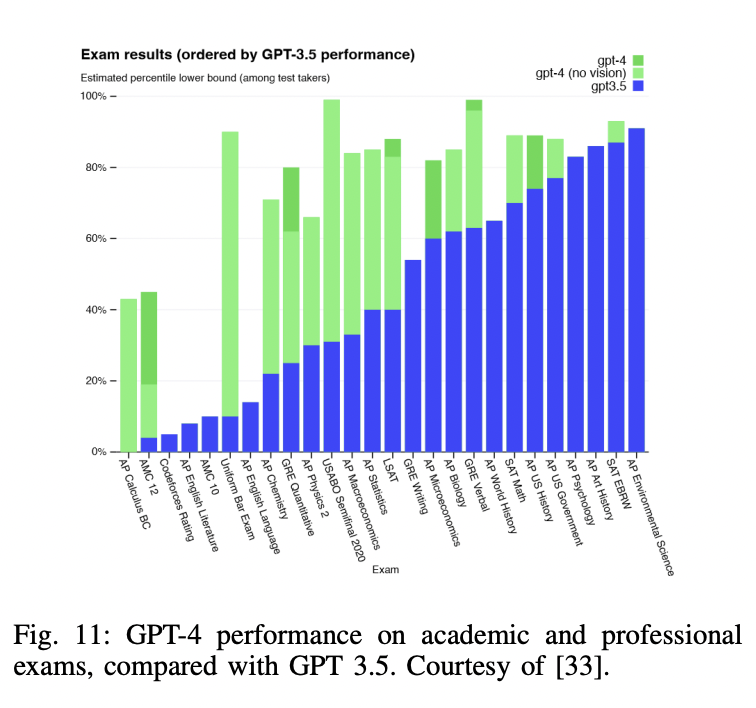
P2-6) GPT-4
- Multimodal LLM (Launched in March, 2023)
- Input: Image and text
- Output: Text outputs.
- Exhibits human-level performance on various benchmarks
- (Same as early GPT models)
- Step 1) Pre-trained to predict next tokens
- Step 2) Fine-tuned with RLHF to align model behaviors with human-desired ones
P3) The LLaMA Family (by Meta)
LLaMA models are “open-source”
\(\rightarrow\) Grows rapidly!
P3-1) LLaMA
( LLaMA: Open and Efficient Foundation Language Models )
https://arxiv.org/pdf/2302.13971
- [Date] February 2023
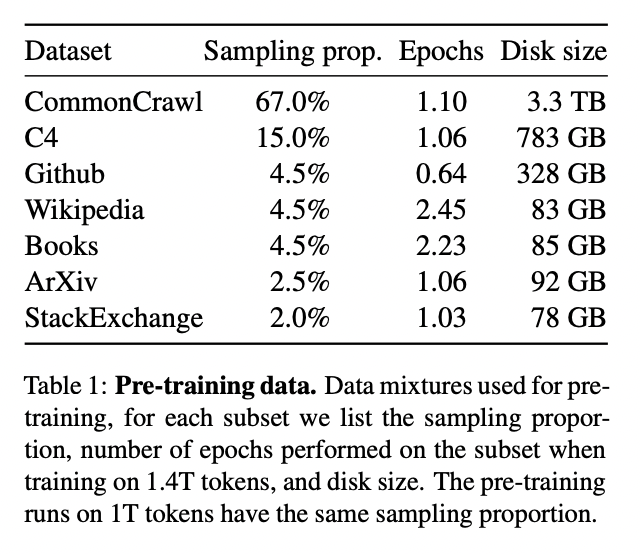
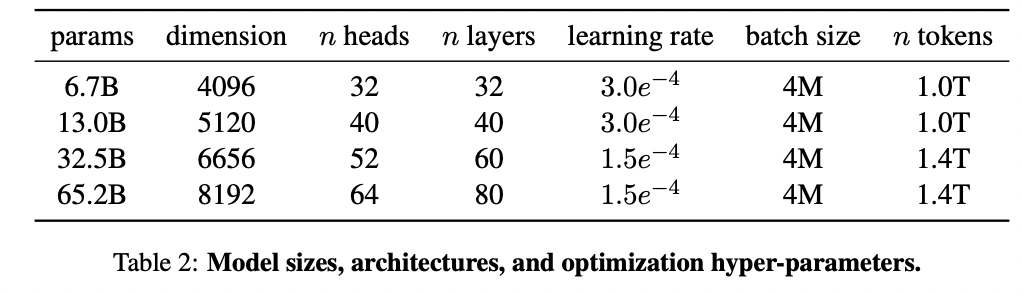
- [Size] Ranging from 7B to 65B params
- [Data] Pre-trained on trillions of tokens ( from publicly available datasets )
- [Arch] Transformer architecture of GPT-3 + \(\alpha\)
- Difference?
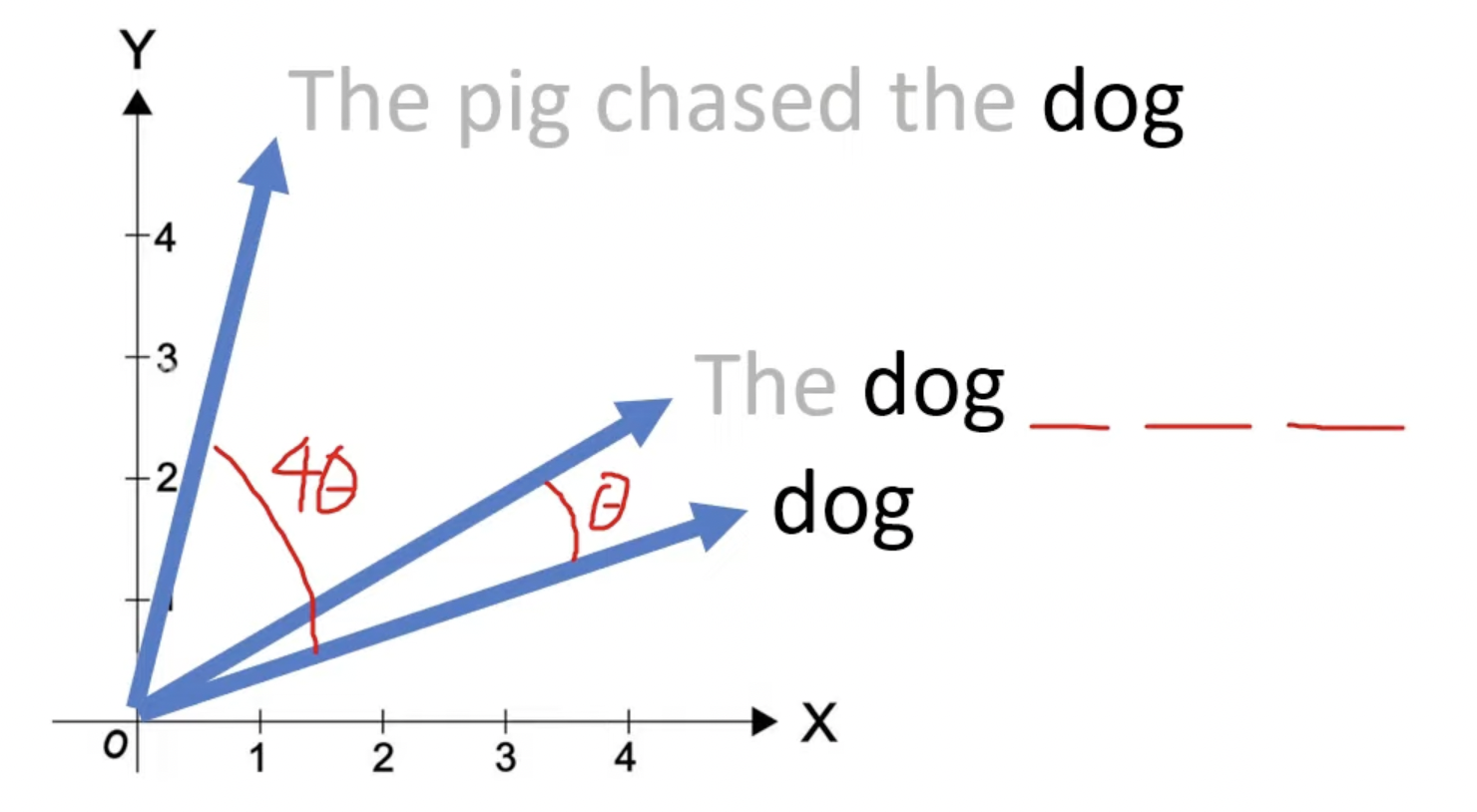
- (1) ReLU \(\rightarrow\) SwiGLU
- (2) Absolute positional embedding \(\rightarrow\) Rotary positional embeddings
- (3) Standard LN \(\rightarrow\) Root-mean-squared LN
- Result:
- (open-source) LLaMA-13B > (proprietary) GPT-3 (175B) on most benchmarks
Rotary positional embedding
- https://www.youtube.com/watch?v=o29P0Kpobz0
P3-2) LLaMA-2
( LLaMA 2: Open Foundation and Fine-Tuned Chat Models )
https://arxiv.org/pdf/2307.09288
-
by Meta (+ partner Microsoft )
-
Include both
- (1) Foundation language models
- (2) Chat models (finetuned for dialog) \(\rightarrow\) LLaMA-2 Chat
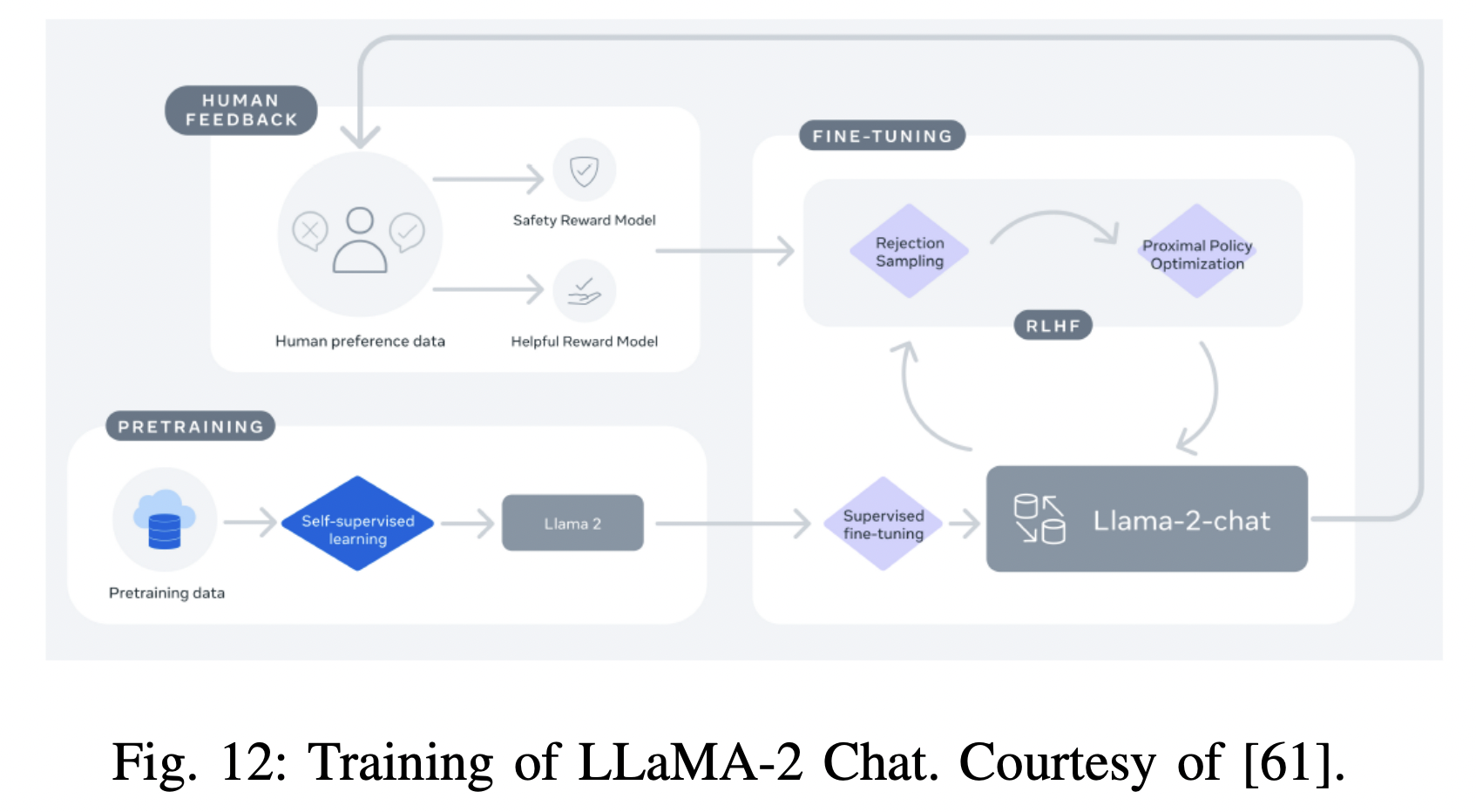
- Step 1) Pretrain LLaMA-2 with publicly available online data
- Step 2) Supervised fine-tuning (SFT)
- Step 3) Iteratively refined using…
- (1) RLHF
- (2) Rejection sampling
- (3) Proximal policy optimization (PPO)
P3-3) Alpaca
- Fine-tuned from the (1) LLaMA-7B model with (2) 52K instruction-following demonstrations
- 52K instruction-following demonstrations
- Generated in the style of self-instruct using GPT-3.5 (text-davinci-003)
- Very cost-effective for training (especially for academic research)
- (Self-instruct evaluation set) Alpaca performs similarly to GPT-3.5, despite that Alpaca is much smaller
P3-4) Vicuna
- Vicuna13B: 13B chat model
- By fine-tuning LLaMA on user-shared conversations collected from ShareGPT
- Evaluation
- (Evaluator = GPT4) Vicuna-13B achieves more than 90% quality of OpenAI’s ChatGPT and Google’s Bard
- Training cost of Vicuna-13B is merely $$300!
P3-5) Guanaco
- Also finetuned LLaMA models using instruction-following data
- Efficient fine-tuning
- Finetuning is done very efficiently using QLoRA
- Finetuning a 65B parameter model can be done on a single 48GB GPU
- QLoRA: Back-propagates gradients through a frozen, 4-bit quantized PLM into LoRA
- Result: Best Guanaco model
- Outperforms all previously released models on the Vicuna benchmark
- 99.3% of the performance level of ChatGPT ( with much lighter model )
- Outperforms all previously released models on the Vicuna benchmark
P3-6) Koala
- Another instruction-following language model built on LLaMA
- Specific focus on interaction data that include user inputs and responses generated by highly capable closed-source chat models (e.g., ChatGPT)
P3-7) Mistral-7B
- Mistral-7B: Engineered for superior performance & efficiency
- (1) Grouped-query attention \(\rightarrow\) For faster inference
- (2) Sliding window attention \(\rightarrow\) To effectively handle sequences of arbitrary length with a reduced inference cost
- Outperforms the best open-source
- 13B model (LLaMA-2-13B) across all evaluated benchmarks
- 34B model (LLaMA-34B) in reasoning, mathematics, and code generation.
P3-8) Summary of LLaMA
- LLaMA or LLaMA2, including Code LLaMA [66], Gorilla [67], Giraffe [68], Vigogne [69], Tulu 65B [70], Long LLaMA [71], and Stable Beluga2 [72], just to name a few.
P4) The PaLM Family
PaLM (Pathways Language Model) … by Google
First PaLM model: April 2022
- [Size] 540B params
- [Dataset] High-quality text corpus consisting of 780B tokens
- [GPU] 6144 TPU v4 chips using the Pathways system
- Enables highly efficient training across multiple TPU Pods
P4-1) U-PaLM
-
U-PaLM models of 8B, 62B, 540B
= Trained on PaLM with UL2R
- A method of continue training LLMs on a few steps with UL2’s mixture-of-denoiser objective
- Approximately 2x computational saving
P4-2) Flan-PaLM
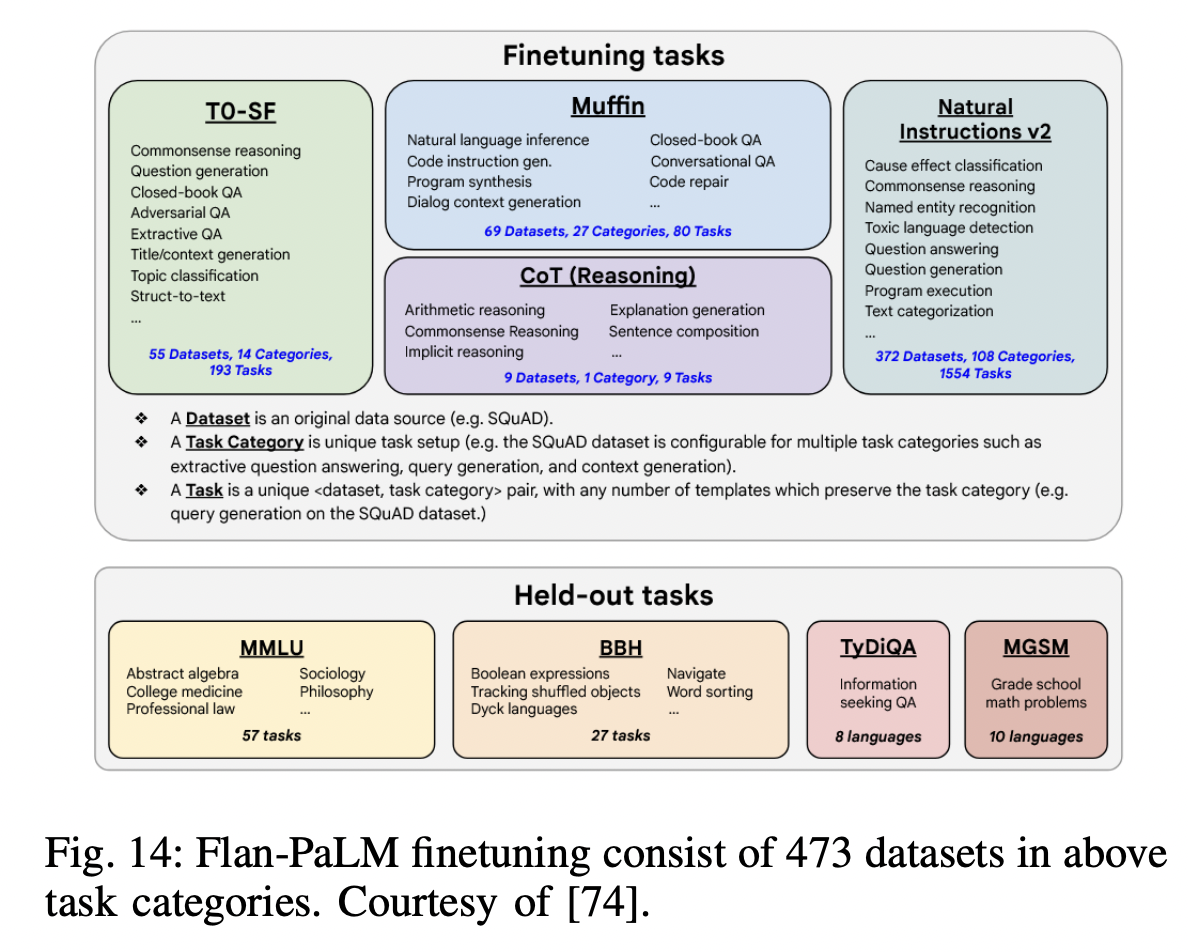
- Flan-PaLM = U-PaLM + Instruction finetuning
- Finetuning: Much larger number of tasks, larger model sizes, and chain-ofthought data
- Result: Substantially outperforms previous instruction-following models
- Fine-tuning data: comprises 473 datasets, 146 task categories, and 1,836 total tasks
P4-3) PaLM-2
- More compute-efficient LLM
- With better multilingual and reasoning capabilities
P4-4) Med-PaLM
- Domain-specific PaLM
- Finetuned on PaLM using instruction prompt tuning
- Designed to provide high-quality answers to medical questions
(4) Other Representative LLMs
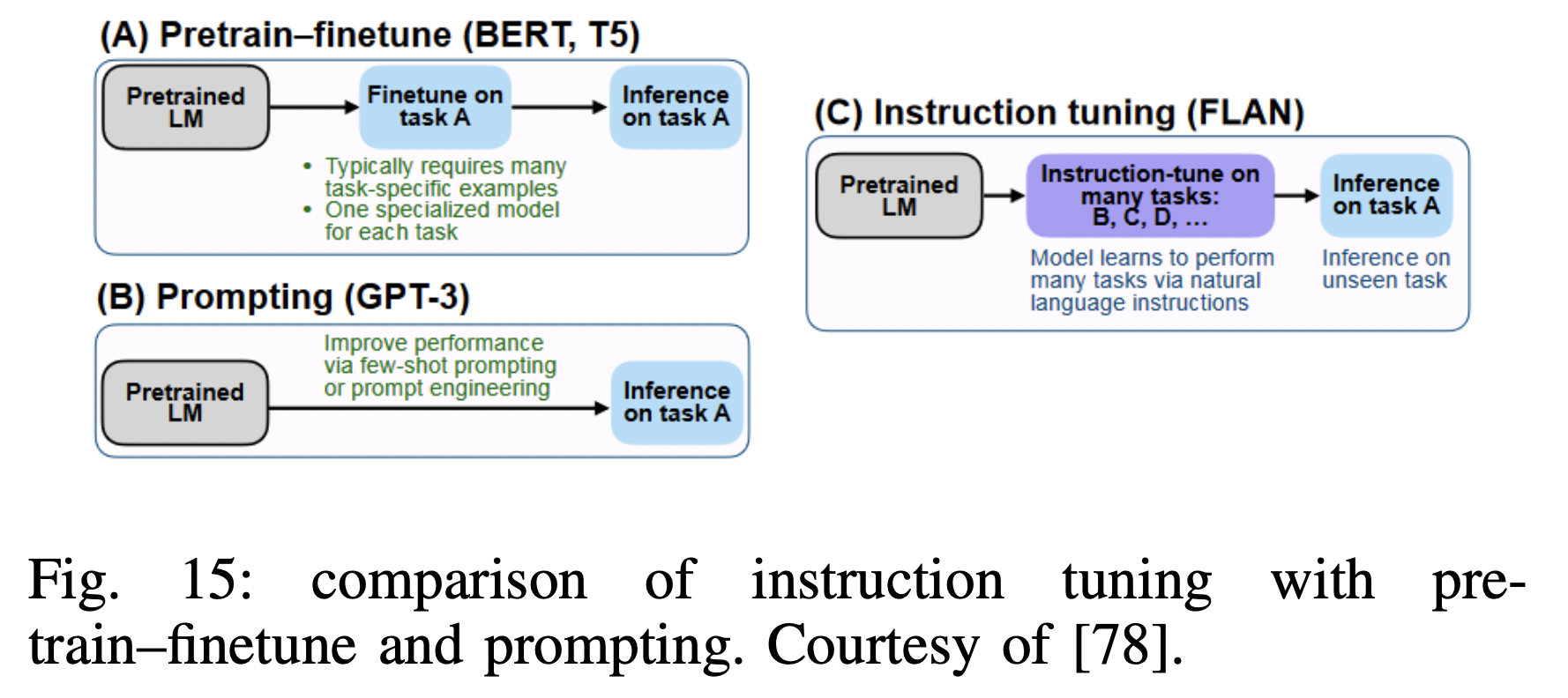
P1) FLAN
-
Simple method for improving the zero-shot learning abilities
\(\rightarrow\) Showed that instruction tuning LMs on a collection of datasets substantially improves zero-shot performance
-
Instruction-tuned model, “FLAN”
- Pretrained LM with 137B params.
- Instruction tune it on over 60 NLP datasets
- verbalized via natural language instruction templates
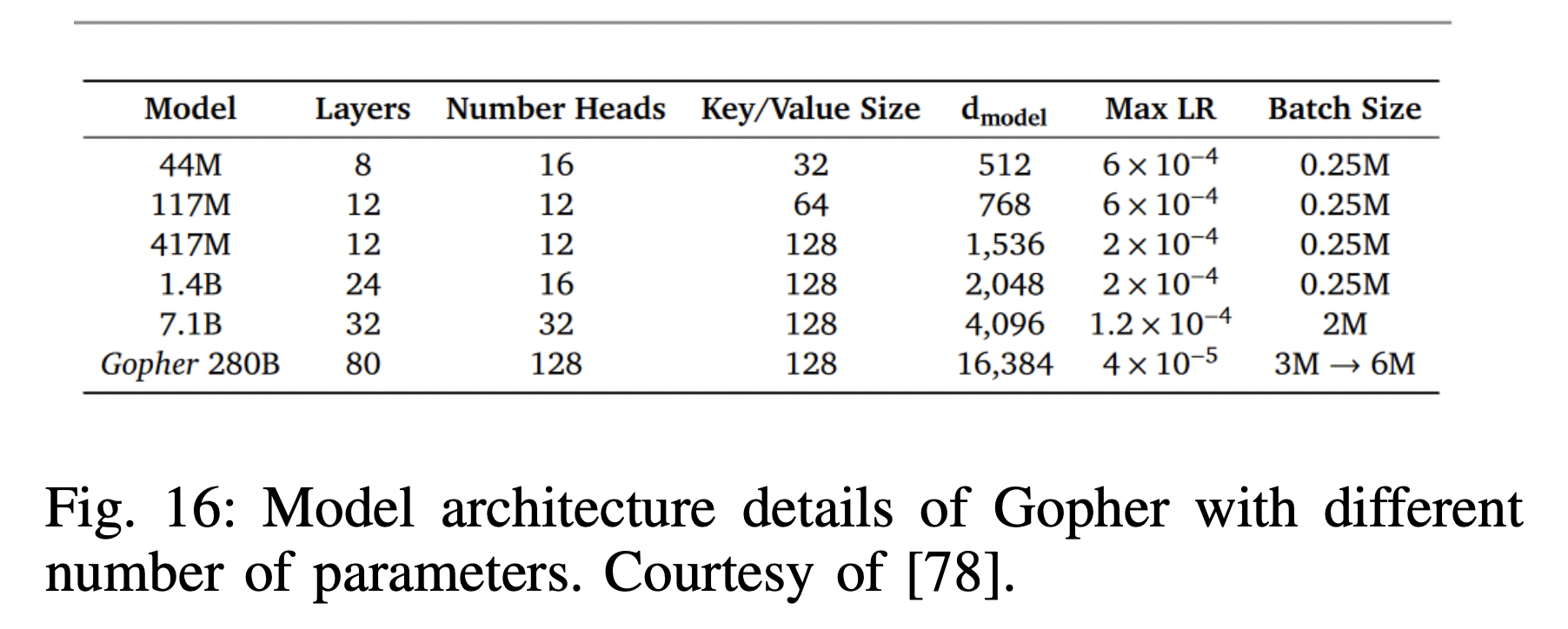
P2) Gopher
- Analysis of Transformer-based LMs across a wide range of model scales
- Gopher = 280B params model
- Evaluated on 152 diverse tasks
P3) T0
-
Easily mapping any natural language tasks into a human-readable prompted form
-
Convert (a) \(\rightarrow\) (b)
- (a) Supervised datasets
- (b) Multiple prompts with diverse wording
\(\rightarrow\)These prompted datasets allow for benchmarking the ability of a model to perform completely held-out tasks
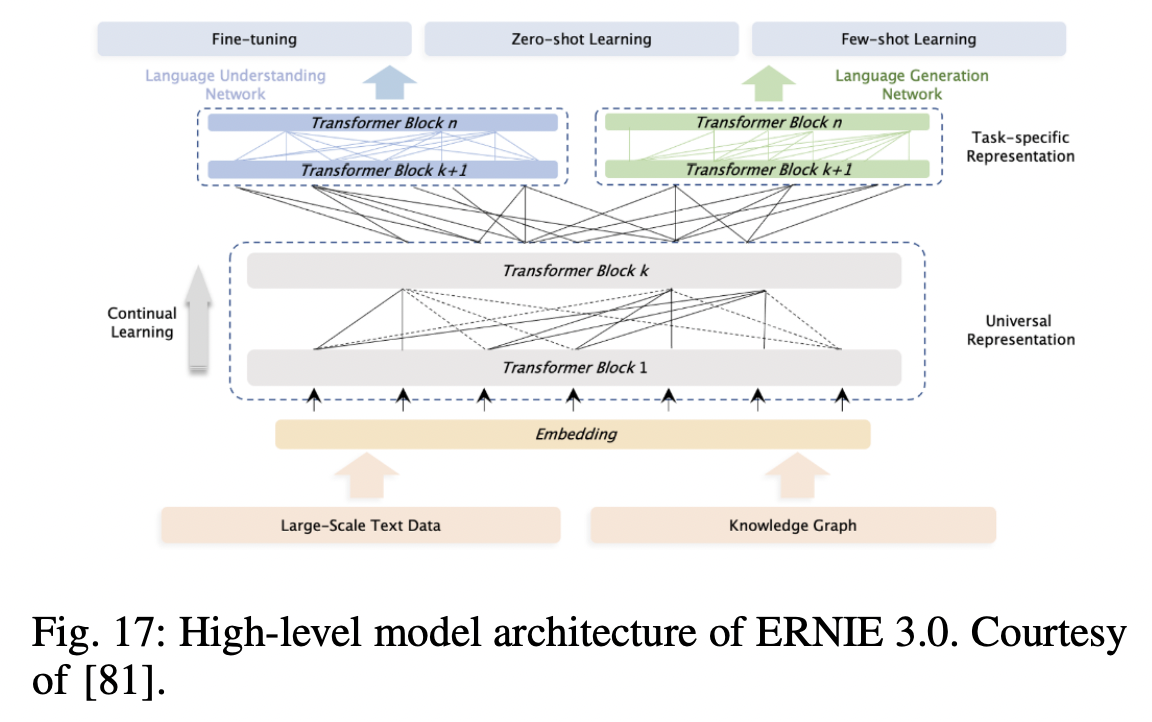
P4) ERNIE 3.0
- Unified framework for pre-training large-scale knowledge enhanced models
- AR model + AE model
- Tailored for both natural language (1) understanding & (2) generation tasks
- ERNIE 3.0 = 10B params + 4TB
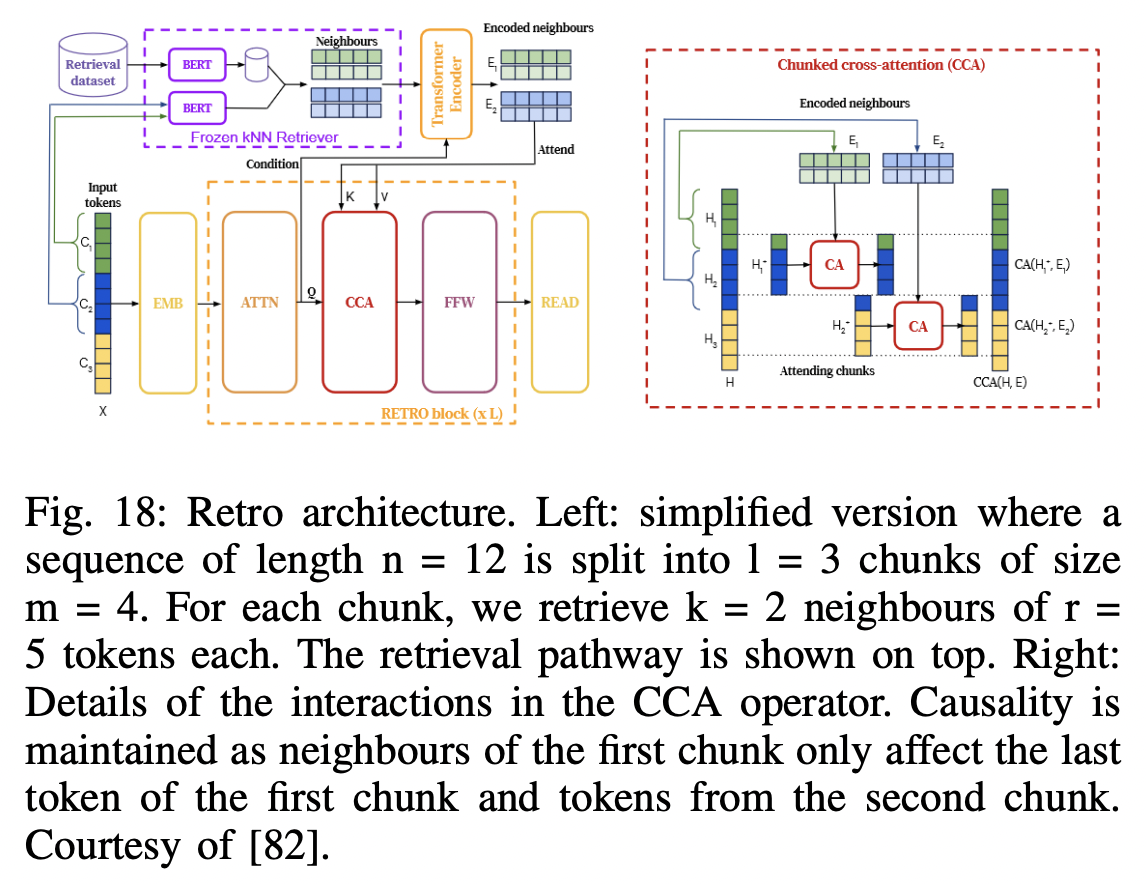
P5) RETRO (Retrieval Enhanced Transformer)
-
Enhanced AR model
-
By conditioning on document chunks retrieved from a large corpus
( based on local similarity with preceding tokens )
-
-
Frozen Bert retriever & Differentiable encoder & Chunked cross-attention mechanism
\(\rightarrow\) Predict tokens based on an order of magnitude with more data than what is typically consumed during training.
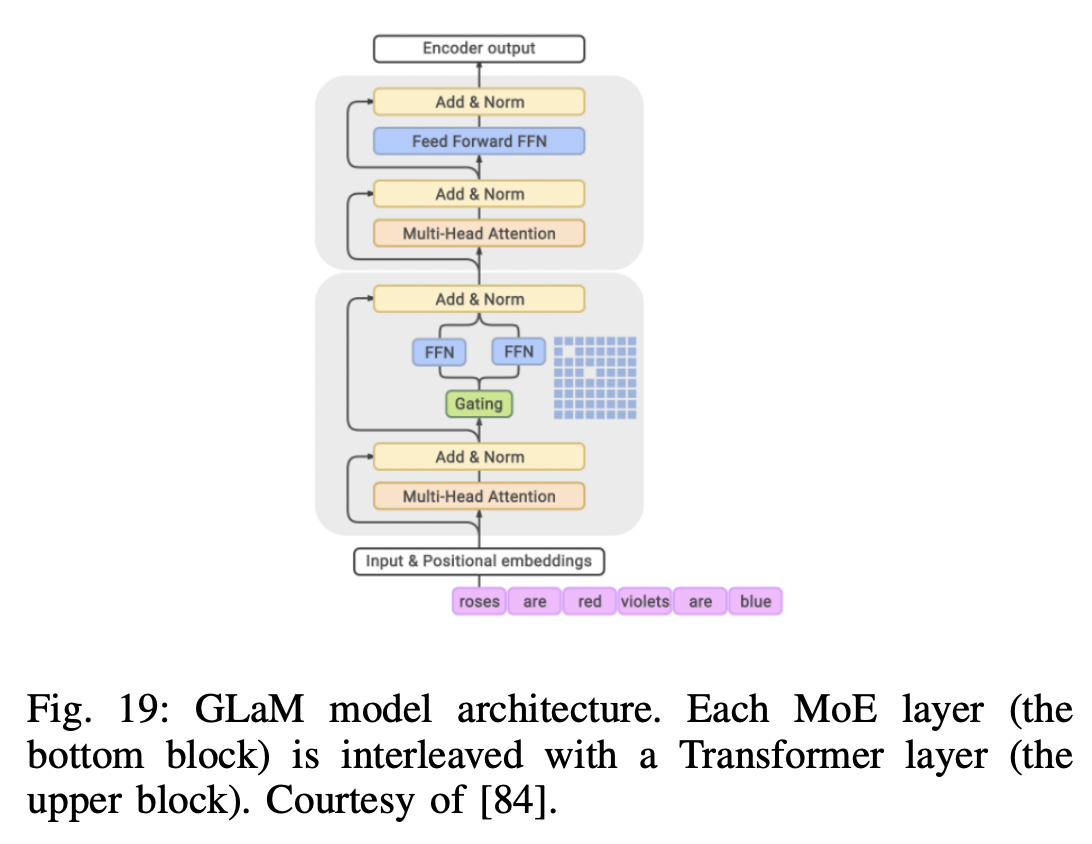
P6) GLaM (Generalist Language Model)
- Sparsely activated MoE
- To scale the model capacity & Incurring substantially less training cost
- Largest GLaM = 1.2T parameters ( = 7x larger than GPT3 )
- 1/3 of the energy used to train GPT-3
- 1/2 of the computation FLOPs for inference
P7) LaMDA
-
Transformer-based models specialized for dialog
- Up to 137B params & pre-trained on 1.56T words of public dialog data and web text
-
Findings: Fine-tuning with annotated data & enabling the model to consult external knowledge sources
\(\rightarrow\) Lead to significant improvements towards the two key challenges of safety and factual grounding
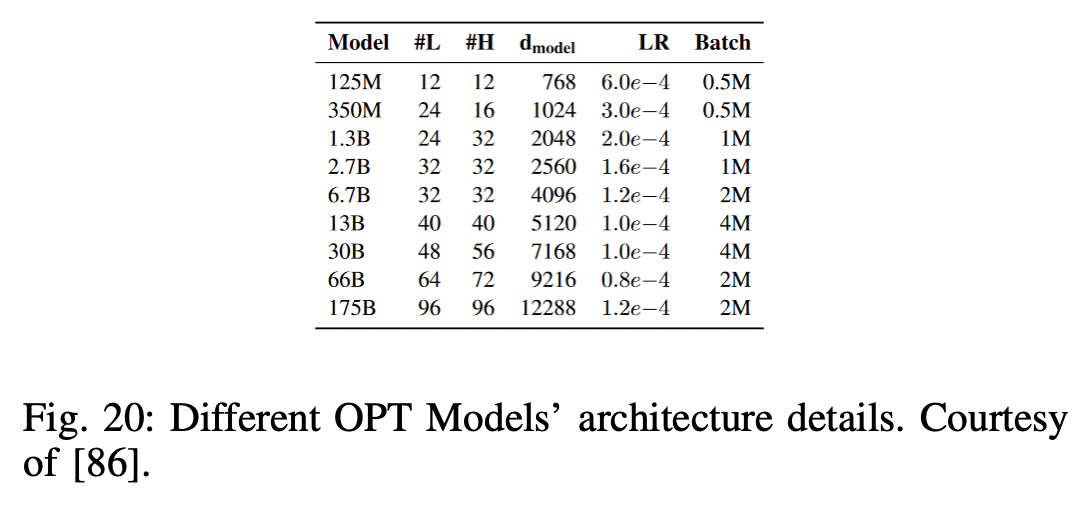
P8) OPT (Open Pre-trained Transformers)
- Decoder-only pre-trained transformers
- params: 125M ~ 175B
P9) Chinchilla
- Investigated the optimal model size and number of tokens under a given compute budget
- Experimental settings
- Over 400 language models (70M~16B parmas + 5~5B tokens)
- Findings: model size & number of training tokens should be scaled equally
- Chinchilla = Compute-optimal model
- Same compute budget as Gopher but with 70B parameters and 4% more data
P10) Galactica
- LLM that can store, combine and reason about scientific knowledge
- Dataset: Large scientific corpus of papers, reference material, knowledge bases …
- Experiments: Outperform …
- Chinchilla on mathematical MMLU: by 41.3% to 35.7%
- PaLM 540B on MATH: with a score of 20.4% versus 8.8%
P11) CodeGen
-
Family of LLMs up to 16.1B params
-
Dataset:
- (1) Natural language
- (2) Programming language data
- (3) Open sourced the training library JAXFORMER
-
Competitive with the previous SOTA on zero-shot Python code generation on HumanEval.
-
Multi-step paradigm for program synthesis
= Single program is factorized into multiple prompts specifying sub-problems
-
Constructed an open benchmark: Multi-Turn Programming Benchmark (MTPB)
- Consisting of 115 diverse problem sets that are factorized into multi-turn prompts
P12) AlextaTM (Alexa Teacher Model)
- Demonstrated that multilingual seq2seq models, pre-trained on a mixture of denoising and Causal Language Modeling (CLM) tasks, are more efficient few-shot learners than decoder-only models on various task!
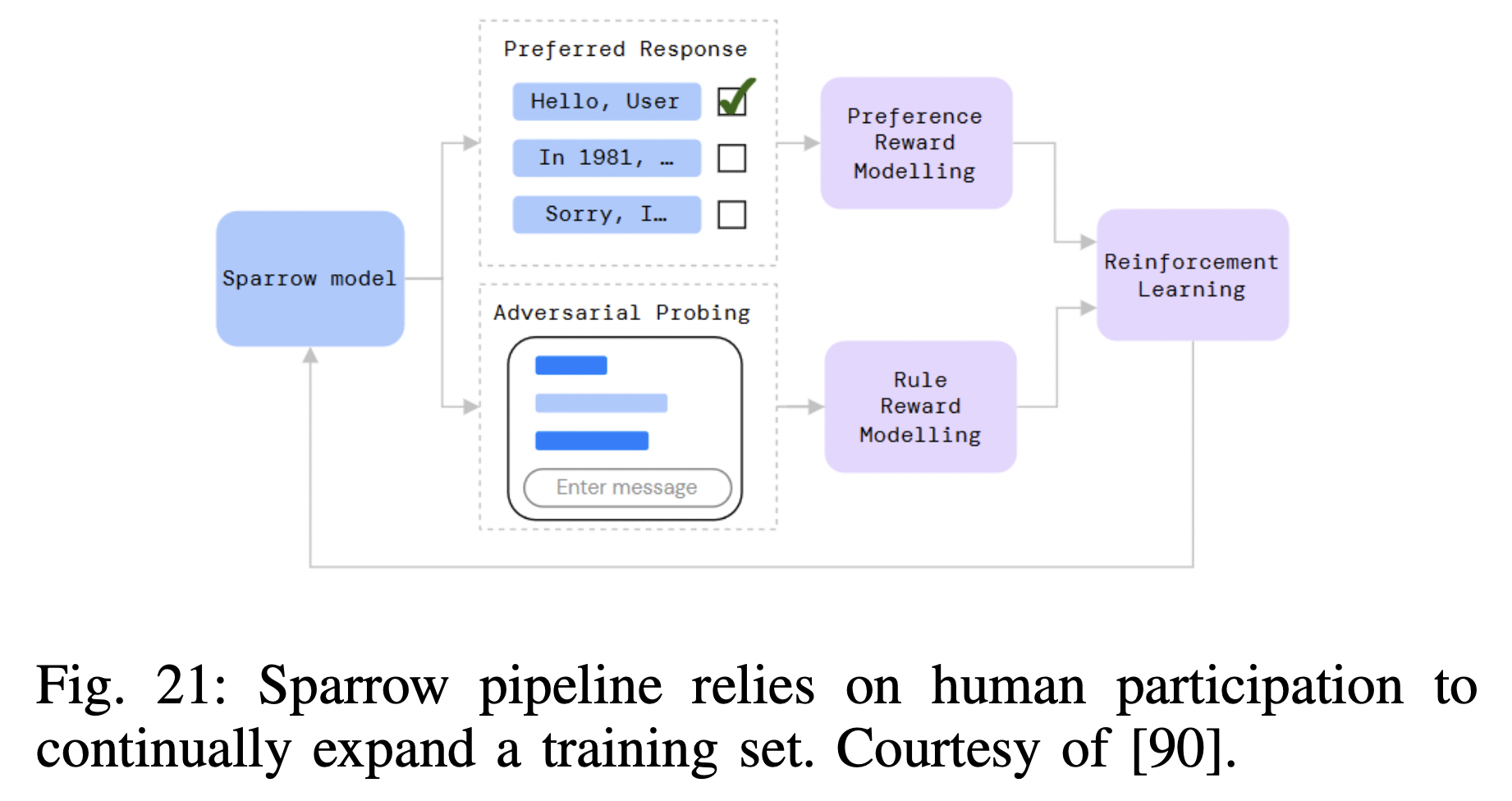
P13) Sparrow
- Information-seeking dialogue agent
- More helpful, correct, and harmless compared to prompted language model baselines
- Use RLHF
P14) Minerva
-
Pretrained on general natural language data
-
Further trained on technical content
\(\rightarrow\) To tackle previous LLM struggle with quantitative reasoning
( e.g., mathematics, science, and engineering problems )
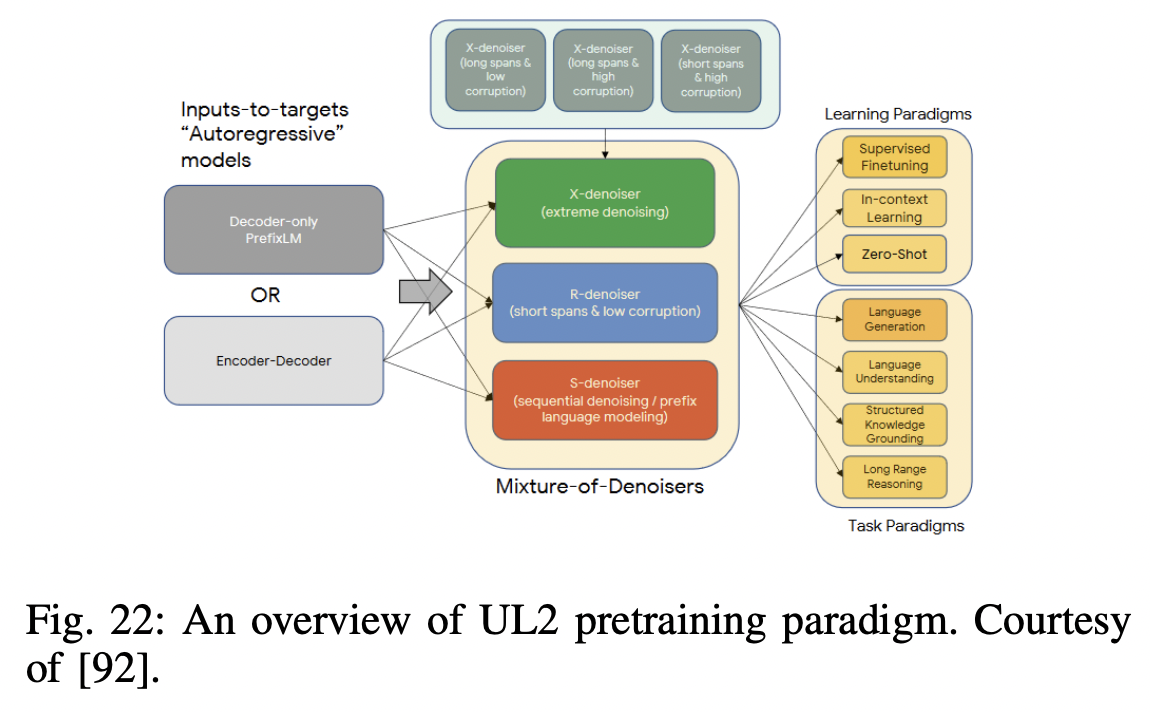
P15) MoD (Mixture-of-Denoisers)
-
Unified perspective for self-supervision in NLP
-
Findings
- How different pre-training objectives can be cast as one another
- How interpolating between different objectives can be effective
-
Mixture-of-Denoisers (MoD)
-
Pretraining objective = Combines diverse pre-training paradigms
\(\rightarrow\) This framework is known as Unifying Language Learning (UL2)
-
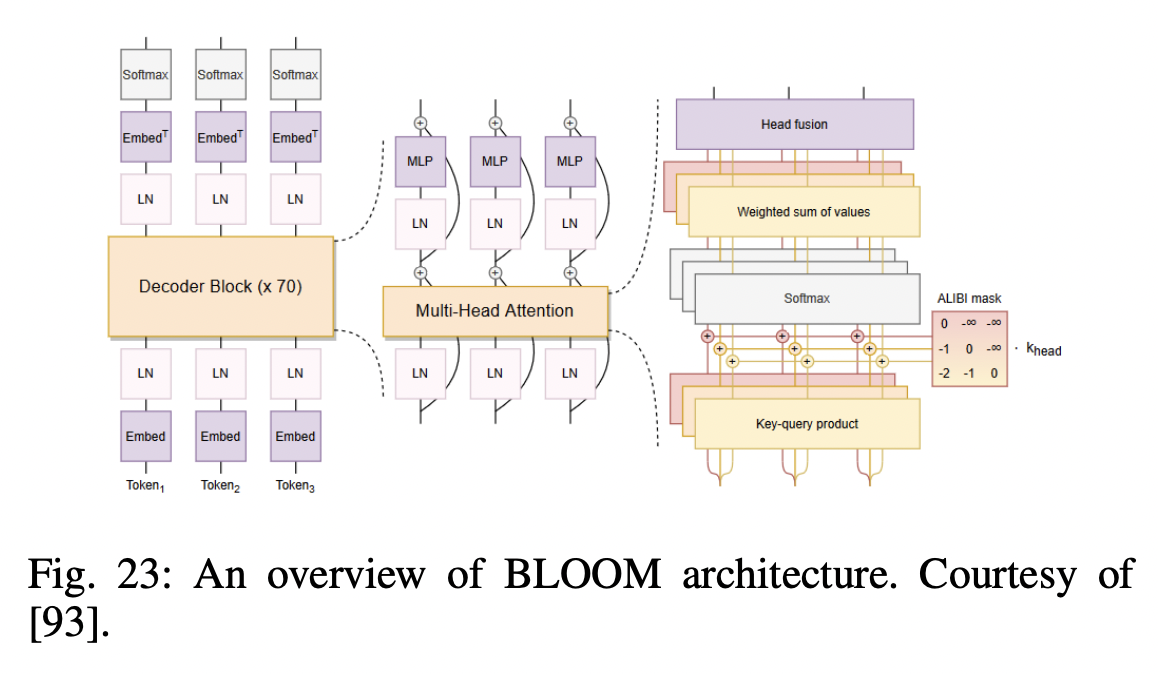
P16) BLOOM
- [Model] Decoder-only Transformer
- [Size] 176B
- [Dataset] ROOTS corpus
- Hundreds of sources in 46 natural and 13 programming languages (59 in total)
P17) GLM
- GLM-130B: Bilingual (English and Chinese) pre-trained LLM
P18) Pythia
- Suite of 16 LLMs (70M ~ 12B params)
- Trained on public data seen in the exact same order
- Public access to 154 checkpoints for each one of the 16 models
P19) Orca
- 13B parameter model
- Imitate the reasoning process of large foundation models
- Learns from rich signals from GPT-4
- e.g., explanation traces, step-by-step thought processes, ..
P20) StarCoder
StarCoder & StarCoderBase
-
15.5B parameter models with 8K context length
-
Infilling capabilities
-
Fast large-batch inference enabled by multi-query attention
-
[Dataset]
-
StarCoderBase: 1T tokens sourced from The Stack
( = Large collection of permissively licensed GitHub repositories )
-
StarCoder: StarCoderBase + (fine-tune) 35B Python tokens
-
P21) KOSMOS
-
Multimodal LLM (MLLM): Can perceive general modalities
-
Trained from scratch
-
On web-scale multi-modal corpora
( including arbitrarily interleaved text and images, image-caption pairs, and text data )
-
-
Impressive performance on …
- (1) Language understanding, generation, and even OCR-free NLP
- (2) Perception-language tasks
- e.g., Multimodal dialogue, image captioning, visual question answering
- (3) Vision tasks
- e.g., Image recognition with descriptions
P22) Gemini
-
Multimodal LLM (MLLM): Can perceive general modalities
\(\rightarrow\) Promising. capabilities across image, audio, video, and text understanding
- Built on top of Transformer decoders
-
Support 32k context length (via using efficient attention mechanisms).
- Three versions
- (1) Ultra: for highly-complex tasks
- (2) Pro: for enhanced performance and deployability at scale
- (3) Nano: for on-device applications
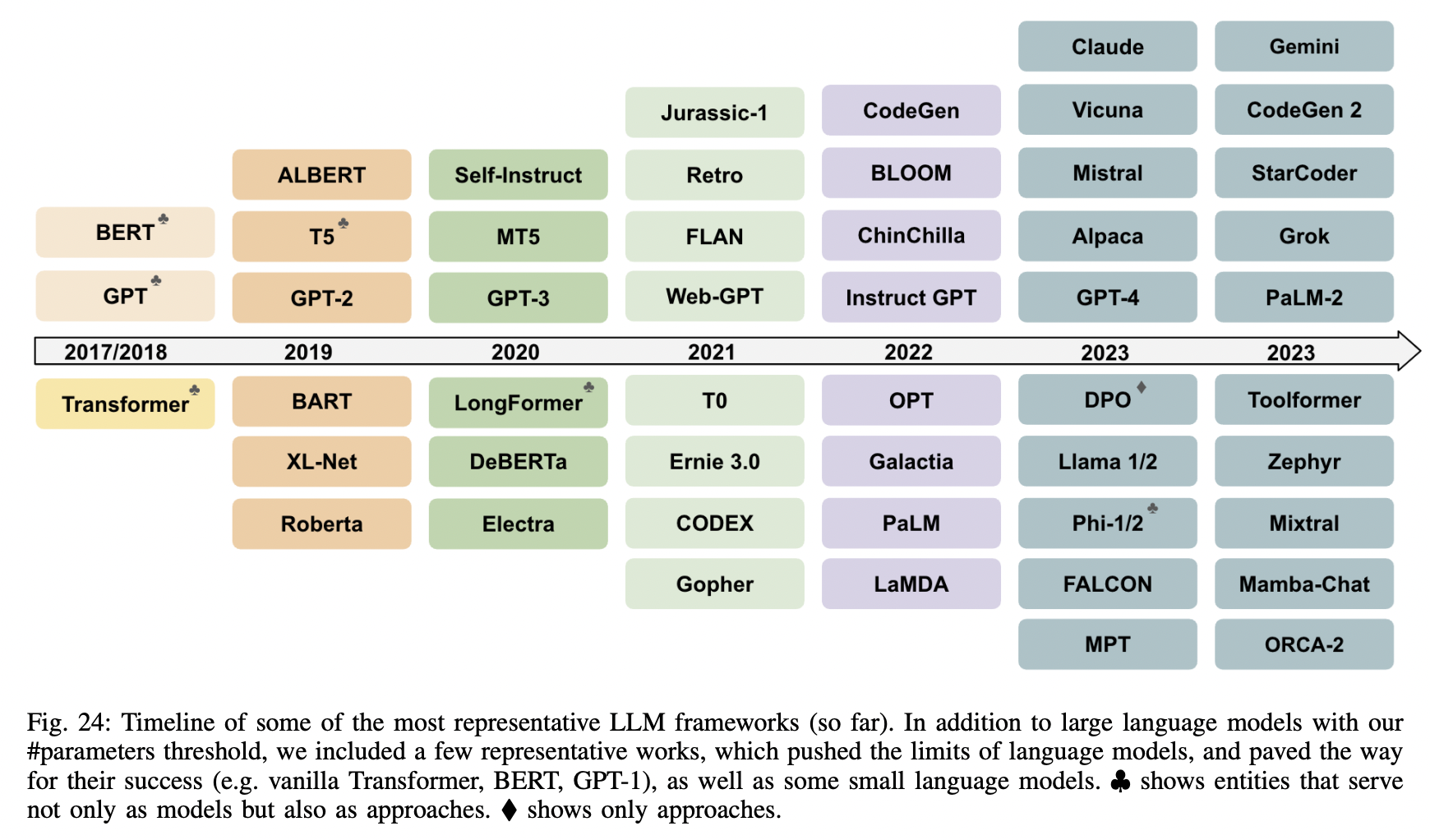
P23) Overview of some of the most representative LLM frameworks