
Large Language Models: A Survey (Part 3)
https://arxiv.org/pdf/2402.06196
3. How LLMs Are Built
P1) Introduction
Popular architectures used for LLMs
Data and modeling techniques
- Data preparation
- Tokenization
- Pre-training
- Instruction tuning
- Alignment
P2) Major steps in training an LLM
- Step 1) Data preparation (collection, cleaning, deduping, etc.)
- Step 2) Tokenization
- Step 3) Model pretraining (in a SSL fashion)
- Step 4) Instruction tuning
- Step 5) Alignment
(1) Dominant LLM Architecture
P1) Three types
Most of them are based on Transformer
- Encoder-only
- Decoder-only
- Encoder-decoder
P2) Arch: Transformer
- Pass!
P2-1)
- Pass
P3) Arch: Encoder-Only
- Model: Attention layers can access all the words in the initial sentence
- Pretraining: MLM
- Experiments: Understanding of the full sequence
- e.g., Sentence classification, named entity recognition, and extractive question answering.
- Ex) BERT
P4) Arch: Decoder-Only
-
Model: Attention layers can only access the words positioned before that in the sentence
( = Autoregressive model )
-
Pretraining: NTP
-
Experiments: Text generation
-
Ex) GPT
P5) Arch: Encoder-Decoder
(Also called sequence-to-sequence models)
-
Model:
- Encoder: Can access all the words in the initial sentence
- Decoder: Can only accesses the words positioned before a given word in the input
-
Pretrained: Using the objectives of encoder or decoder models
-
e.g., Replacing random spans of text with a single mask special word
$\rightarrow$ Predict the text that this mask word replaces
-
-
Experiments: Generating new sentences conditioned on a given input
- e.g., Summarization, translation, or generative question answering
(2) Data Cleaning
P1) Data quality is crucial!
Data cleaning techniques
- e.g., Filtering, deduplication
$\rightarrow$ Big impact on the model performance
P2) Falcon40B
-
Properly filtered and deduplicated web data $\rightarrow$ Lead to powerful models!
( + Despite extensive filtering, they were able to obtain five trillion tokens from CommonCrawl )
P3) Data Filtering
Enhance the quality of training data & effectiveness of the trained LLMs
Common data filtering techniques include:
- (1) Removing noise
- (2) Handling Outliers
- (3) Addressing Imbalances
- (4) Text Preprocessing
- (5)
P3-1) Removing Noise
Ex) Removing false information from the training data
Two mainstream approaches:
- (1) Classifier-based
- (2) Heuristic-based
P3-2) Handling Outliers
Prevent them from disproportionately influencing the model.
P3-3) Addressing Imbalances
To avoid biases and ensure fair representation
P3-4) Text Preprocessing
Cleaning and standardizing text data
- By removing stop words, punctuation, …
P3-5) Dealing with Ambiguities
Resolving or excluding ambiguous or contradictory data
$\rightarrow$ Help the model to provide more definite and reliable answers
P4) Deduplication
Duplicate data: Introduce biases & Reduce the diversity
$\rightarrow$ Remove duplicate instances or repeated occurrences
P4-1) Importance of deduplication
Particularly important when dealing with large datasets!
$\rightarrow$ Unintentionally inflate the importance of certain patterns or characteristics.
P4-2) De-duplication method
Vary based on the nature of the data
- Ex) Comparing entire data points or specific features
- Ex) (Document level) Overlap ratio of high-level features (e.g. n-grams overlap) between documents
(3) Tokenizations
P1) What is Tokenization?
- Converting a sequence of text into smaller parts ( = tokens )
- Three popular tokenizers
- (1) BytePairEncoding
- (2) WordPieceEncoding
- (3) SentencePieceEncoding
P2) BytePairEncoding
-
(Originally) Data compression algorithm
$\rightarrow$ Uses frequent patterns at byte level to compress the data
-
Pros)
- (1) Simple
- (2) Keeps the vocabulary not very large
- (3) Good enough to represent common words at the same time
P3) WordPieceEncoding
- Mainly used for very well-known models (e.g., BERT, Electra)
- Similar to BPE but merges tokens based on likelihood (as in language modeling)
P4) SentencePieceEncoding
-
BPE & WPE: Take assumption of words being always separated by white-space
$\rightarrow$ Not always true!
-
SPE: Works on raw text including spaces
(4) Positional Encoding
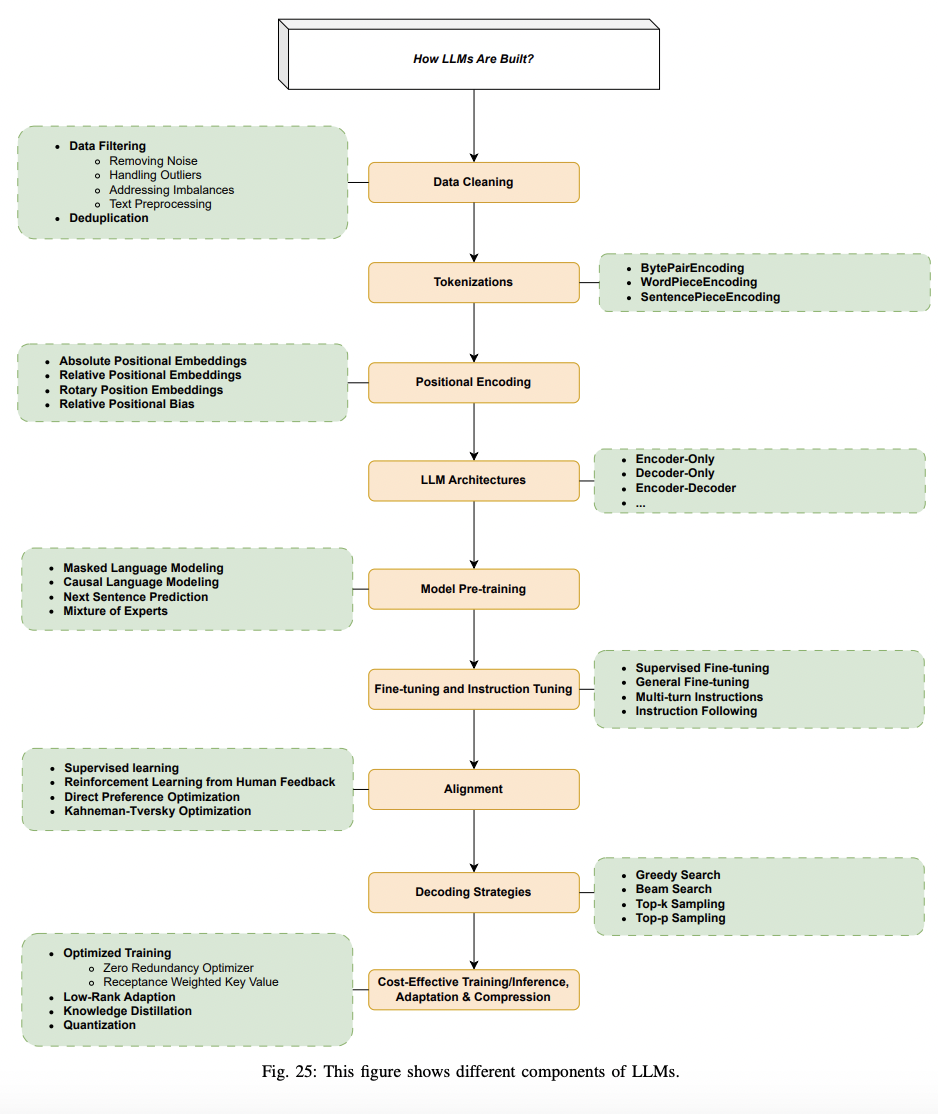
P1) Absolute Positional Embeddings
- Original Transformer model
- Learned vs. Fixed
- Main drawbacks
- (1) Restriction to a certain number of tokens
- (2) Fails to account for the relative distances between tokens
P2) Relative Positional Embeddings
- To take into account the pairwise links between input tokens
- RPE is added to the model at two levels
- (1) Additional component to the keys
- (2) Sub-component of the values matrix
P3) Rotary Position Embeddings (RoPE)
- Rotation matrix to ..
- (1) Encode the absolute position of words
- (2) Include explicit relative position details in self-attention.
- Flexibility with context lengths
- e.g., GPT-NeoX-20B, PaLM, CODEGEN, and LLaMA
(5) Model Pre-training
P1) Pretraining
Prained on a massive amount of (usually) unlabeled texts in SSL mannerl
- Next sentence prediction (NSP)
- Next token prediction (NTP)
- Masked language modeling (MLM)
P2) Next token prediction (NTP)
$\mathscr{L}{A L M}(x)=\sum{i=1}^N p\left(x_{i+n} \mid x_i, \ldots, x_{i+n-1}\right)$.
P3) Masked language modeling (MLM)
$\mathscr{L}{M L M}(x)=\sum{i=1}^N p(\bar{x} \mid x \backslash \bar{x})$.
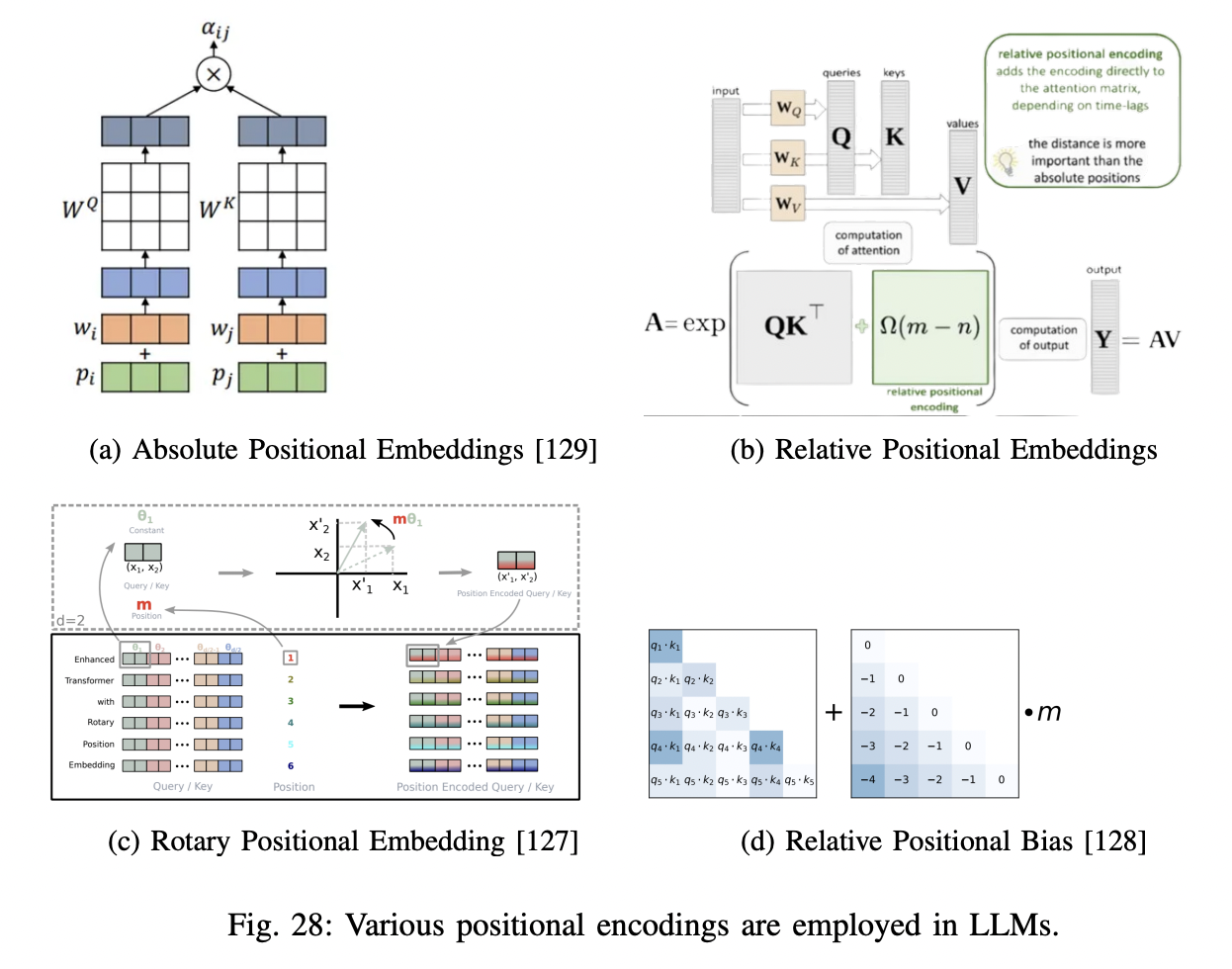
P4) Mixture of Experts (MoE)
-
Enable models to be pre-trained with much less compute
$\rightarrow$ $\therefore$ Can dramatically scale up the model or dataset size with the same compute budget
-
Two main elements:
- (1) Sparse MoE layers
- Used instead of FFN
- Have certain number of “experts” (=NN)
- (2) Gate network or router
- Determines which tokens are sent to which expert
- (1) Sparse MoE layers
(6) Fine-tuning and Instruction Tuning
P1) Necessity of fine-tuning
-
Fine-tuned to a specific task with labeled data (= SFT)
- e.g., BERT: Finetuned to 11 different tasks
-
While more recent LLMs no longer require fine-tuning to be used…
$\rightarrow$ they can still benefit from task or data-specific fine-tuning
- e.g., (Much smaller) GPT-3.5 Turbo model + fine-tune > GPT-4
P2) Multi-task fine-tuning
- Does not need to be performed to a single task!
- Various approaches to multi-task fine-tuning
- Improve results & Reduce the complexity of prompt engineering
- Alternative to RAG
- Ex) Fine-tune to expose the model to new data that has not been exposed to during pre-training
P3) Instruction Tuning
- Instruction = Prompt that specifies the task (that the LLM should accomplish)
- To align the responses to the expectations that humans!
- Especially, when providing instructions through prompts!
P4) Importance of Instruction Tuning
- Instruction datasets varies by LLM!
- Instruction tuned models > Original foundation models
- e.g., InstructGPT > GPT-3
- e.g., Alpaca > LLaMA
P5) Self-Instruct
- Popular approach in instruction tuning
- Framework for improving the instruction-following capabilities of pre-trained LM by bootstrapping their OWN generations
- Procedure
- Step 1) Generates (instructions, input, and output) samples with LM ( = itself )
- Step 2) Filters invalid or similar ones
- Step 3) Fine tune the original model with them
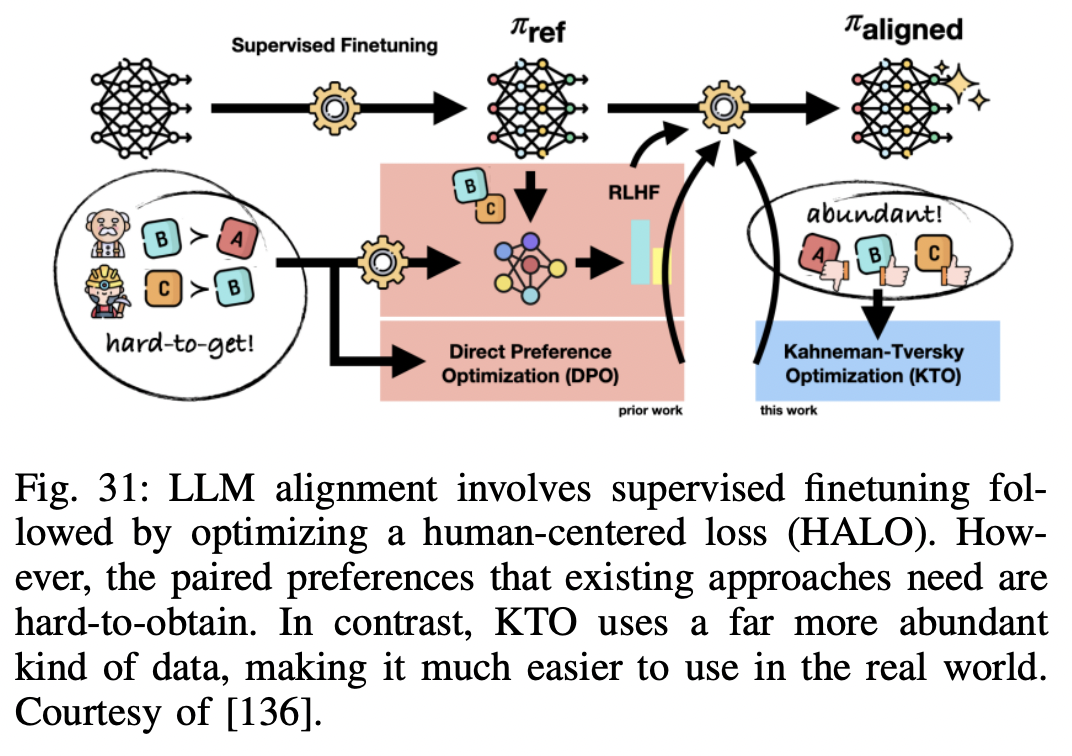
(7) Alignment
P1) What is alignment?
-
Steering AI systems towards human goals, preferences, and principles
-
LLM = Often exhibit unintended behaviors :(
( e.g., toxic, harmful, misleading and biased )
P2) Alignment & Instruction tuning
- Instruction tuning = Makes LLMs to be aligned
-
Important to include further steps to **improve the alignment of the model **and avoid unintended behaviors!!
- Most popular approaches
- (1) RLHF, RLAIF
- (2) DPO
- (3) KTO
P3) RLHF & RLAIF
- RLHF (reinforcement learning from human feedback)
- Uses reward model to learn alignment from human feedback!
- Procedure
- (1) LM generates multiple output
- (2) Reward model rates multiple outputs & scores them (based on preferences given by humans)
- (3) Feward model gives feedback to the LLM
- (4) Feedback is used to tune the LLM
- e.g., OpenAI-ChatGPT, Anthropic-Claude, Google-Gemini
- RLAIF (Reinforcement learning from AI feedback)
- Preference (Evaluation) by AI (=Model)
P4) Direct Preference Optimization (DPO)
No need for reward model & PPO!
-
Limitation of RLHF: Complex and often unstable!
-
DPO = Stable, performant, and computationally lightweight
$\rightarrow$ Eliminating the need for fitting a reward model, sampling from the LM during finetuning, or performing significant hyperparameter tuning!
P5) Kahneman-Tversky Optimization (KTO)
- Does not require paired preference data $(x, y_1, y_2)$
- Only needs $(x,y)$ & knowledge of whether $y$ is desirable or undesirable
- Better than DPO-aligned models (at scales from 1B to 30B)
- Far easier to use in the real world, as the kind of data it needs is far more abundant!
- e.g., Purchase data = successful (purchase O) & unsuccessful (purchase X)
(8) Decoding Strategies
P1) Decoding
- Decoding = Process of text generation using pretrained LLMs
- Procedure
- Step 1) LLM generates logits
- Step 2) Logits are converted to probabilities using a softmax function
- Step 3) Various decoding strategies
- e.g., Greedy search, beam search, as well as different sample techniques such as top-K, top-P (Nucleus sampling).
P2) Greedy Search
- pass
P3) Beam Search
- pass
P4) Top-k Sampling
- Low temprature = Creativity
- High temperature = Priority
(9) Cost-Effective Training/Inference/Adaptation/Compression
P1) Optimized Training
Various frameworks for optimized training of LLMs
P1-1) Zero Redundancy Optimizer (ZeRO)
Goal: To optimize memory
-
Vastly improving training speed of LLMs, while increasing the model size
-
Eliminates memory redundancies in data- and model-parallel training
-
Low communication volume and high computational granularity
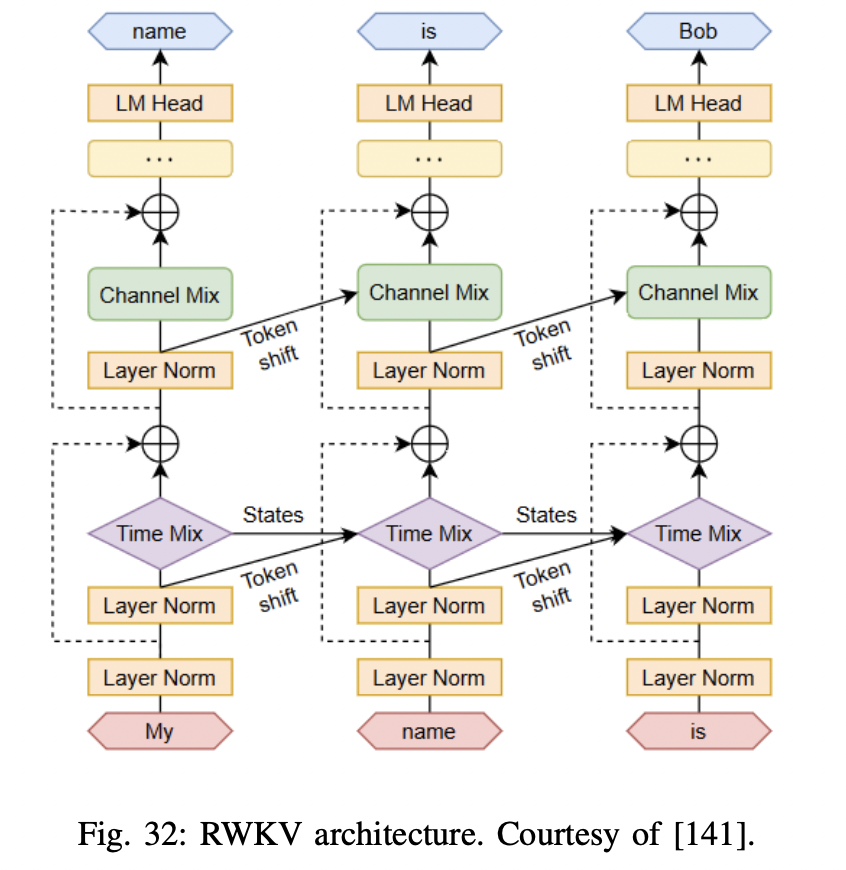
P1-2) Receptance Weighted Key Value (RWKV)
Combines the ..
- (1) Efficient parallelizable training of Transformers
- (2) Efficient inference of RNNs
Leverages a linear attention mechanism & Allows them to formulate the model as either a Transformer or an RNN
P2) Low-Rank Adaption (LoRA)
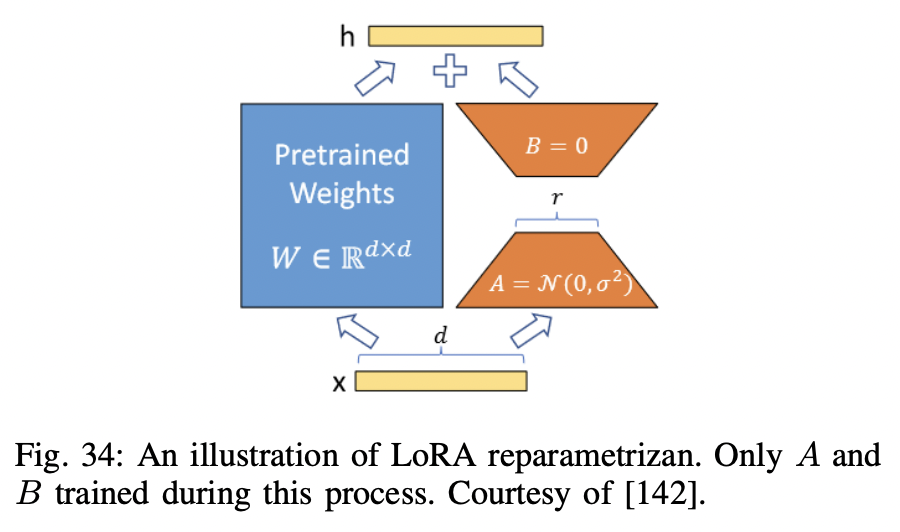
-
Can be applied to any a subset of weight matrices in a NN
- e.g., Self-attention module $\left(W_q, W_k, W_v, W_o\right)$, & two in the MLP module
-
Mostly focused on adapting the “attention weights”only for downstream tasks
( Freezes the MLP modules, so they are not trained in downstream tasks both for simplicity and parameter-efficiency )
P3) Knowledge Distillation
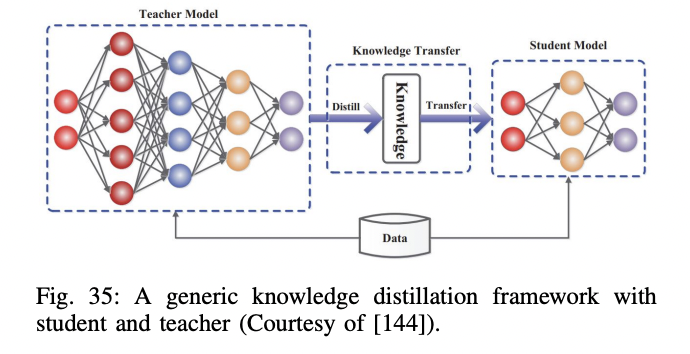
P3-1) Various types of distillation
- Response distillation
- Follow the output of the teacher model!
- Tries to teach the student model how to similariy perform as teacher
- Feature distillation
- Follow the representation of the teacher model!
- Not only the last layer, but also intermediate layers
- API distillation
- Process of using an API (typically from an LLM provider such as OpenAI) to train smaller models
P4) Quantization
- Reducing the precision of the weights $\rightarrow$ Reduce the size of the model $\rightarrow$ Faster
- e.g., FP32, FP16, NF16 …
- Main approaches for model quantization
- (1) Post training quantization
- (2) Quantization-aware training