
Large Language Models: A Survey (Part 4)
https://arxiv.org/pdf/2402.06196
4. How LLMs are Used and Augmented
Advancing LLMs
- Naive: LLMs can be used directly through basic prompting
- Advancement: Augment the models through some external means!
This section
- (1) Main shortcoming of LLMs (e.g., hallucination)
- (2) Solutions: Prompting & Augmentation approaches
(1) LLM Limitations
P1) Limitation of LLMs
- [1] They don’t have state/memory.
- Cannot remember even what was sent to them in the previous prompt!
- [2] They are stochastic/probabilistic.
- Get different responses every time
- [3] They have stale information and, on their own, don’t have access to external data.
- Does not have access to any information that was not present in its training set
- [4] They are generally very large.
- Many costly GPU machines are needed
- [5] They hallucinate.
- Can produce very plausible but untruthful answers.
P2) Hallucination
Definition: ”the generation of content that is nonsensical or unfaithful to the provided source.”
P2-1) Categorization of Hallucination
1) Intrinsic Hallucinations
-
Directly conflict with the source material
( Factual inaccuracies or logical inconsistencies )
2) Extrinsic Hallucinations
- While not contradicting, are unverifiable against the source
P2-2) “Source” in LLM context
The definition differs by tasks!
- Dialogue-based tasks
- Source = “world knowledge”
- Text summarization
- Source = “Input text itself”
$\rightarrow$ This distinction plays a crucial role in evaluating and interpreting hallucinations
Impact of hallucinations is also highly context-dependent
- e.g., Poem writing LLMs: Hallucinations might be deemed acceptable or even beneficial!
P2-3) Recent Works to Overcome Hallucination
E.g., Instruct tuning, RLHF
$\rightarrow$ Have attempted to steer LLMs towards more factual outputs
( But the fundamental probabilistic nature and its inherent limitations remain )
“Sources of Hallucination by Large Language Models on Inference Tasks” [146]
$\rightarrow$ Two key aspects contributing to hallucinations
- (1) Veracity prior: The model assumes frequently seen information is likely true.
- (2) Relative frequency heuristic: The model trusts and generates more common words or concepts.
P2-4) Automated Measurement of Hallucinations in LLMs
Statistical Metrics
- ROUGE [147] and BLEU [148]
- Common for assessing text similarity, focusing on intrinsic hallucinations.
- PARENT [149], PARENTT [150], and Knowledge F1 [151]
- Utilized when structured knowledge sources are available
$\rightarrow$ While effective, have limitations in capturing semantics!
Model-Based Metrics
- IE-Based Metrics (Information Extraction)
- QA-Based Metrics:
- NLI-Based Metrics:
- Faithfulness Classification Metrics:
P2)
Despite advances in automated metrics, human judgment remains a vital piece. It typically involves two methodologies:
Scoring: Human evaluators rate the level of hallucination within a predefined scale. 2) Comparative Analysis: Evaluators compare generated content against baseline or ground-truth references, adding an essential layer of subjective assessment.
P2)
FactScore [155] is a recent example of a metric that can be used both for human and model-based evaluation. The metric breaks an LLM generation into “atomic facts”. The final score is computed as the sum of the accuracy of each atomic fact, giving each of them equal weight. Accuracy is a binary number that simply states whether the atomic fact is supported by the source. The authors implement different automation strategies that use LLMs to estimate this metric.
P2)
Finally, mitigating hallucinations in LLMs is a multifaceted challenge, requiring tailored strategies to suit various applications. Those include: • Product Design and User Interaction Strategies such as use case design, structuring the input/output, or providing mechanisms for user feedback. • Data Management and Continuous Improvement Maintaining and analyzing a tracking set of hallucinations is essential for ongoing model improvement. • Prompt Engineering and Metaprompt Design. Many of the advanced prompt techniques described in IV-B such as Retrieval Augmented Generation directly address hallucination risks. • Model Selection and Configuration for Hallucination Mitigation. For exemple, larger models with lower temperature settings usually perform better. Also, techniques such as RLHF or domain-sepcific finetuning can mitigate hallucination risks.
(2) Using LLMs: Prompt Design and Engineering
P2) What is prompt?
Textual input provided by users to guide the model’s output
Range from “Simple questions” ~ “Detailed descriptions or specific tasks”
Generally consist of ..
- (1) Instructions
- (2) Questions
- (3) Input data
- (4) Examples
$\rightarrow$ Must contain either (1) instructions or (2) questions ( with other elements being optional )
Advanced prompts:
- More complex structures
- E.g., ”chain of thought” prompting
- Model is guided to follow a logical reasoning process to arrive at an answer
P2) Prompt engineering is not simple!
Goes beyond mere construction of prompts!
$\rightarrow$ Requires a blend of domain knowledge, understanding of the AI model…
- e.g., Creating templates that can be programmatically modified based on a given dataset or context.
P2) Prompt engineering is an iterative and exploratory process!
Akin to hyperparameter tuning
P3) Chain of Thought (CoT)
( Popular prompt engineering approaches )
Paper “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models”
- Pivotal advancement in prompt engineering for LLMs
- Hinges on the understanding that LLM are..
- Proficient in token prediction
- But not inherently designed for explicit reasoning
$\rightarrow$ CoT addresses this by guiding the model through reasoning steps
P1) CoT = Making the implicit reasoning process of LLMs explicit
By outlining the steps required for reasoning!
$\rightarrow$ The model is directed closer to a logical and reasoned output
Types of Prompts
P1) Two forms of CoT
1) Zero-Shot CoT
- “think step by step”
- Pros) Simple
- Cons) Too simple! 2) Manual CoT
- Requires providing step-by-step reasoning examples as templates for the model
- Pros) Effective
- Cons) Challenges in scalability and maintenance / error prone
$\rightarrow$ Why not use Automatic CoT?
P2) Tree of Thought (ToT)
-
Concept of considering various alternativethought processes before converging on the most plausible one
-
Branching out into multiple ”thought trees”
- Each branch = Different line of reasoning
-
Allows the LLM to explore various possibilities and hypotheses
( $\approx$ Human cognitive processes: Multiple scenarios are considered before determining the most likely one )
$\rightarrow$ More human-like problem-solving approach
( = considering a range of possibilities before arriving at a conclusion )
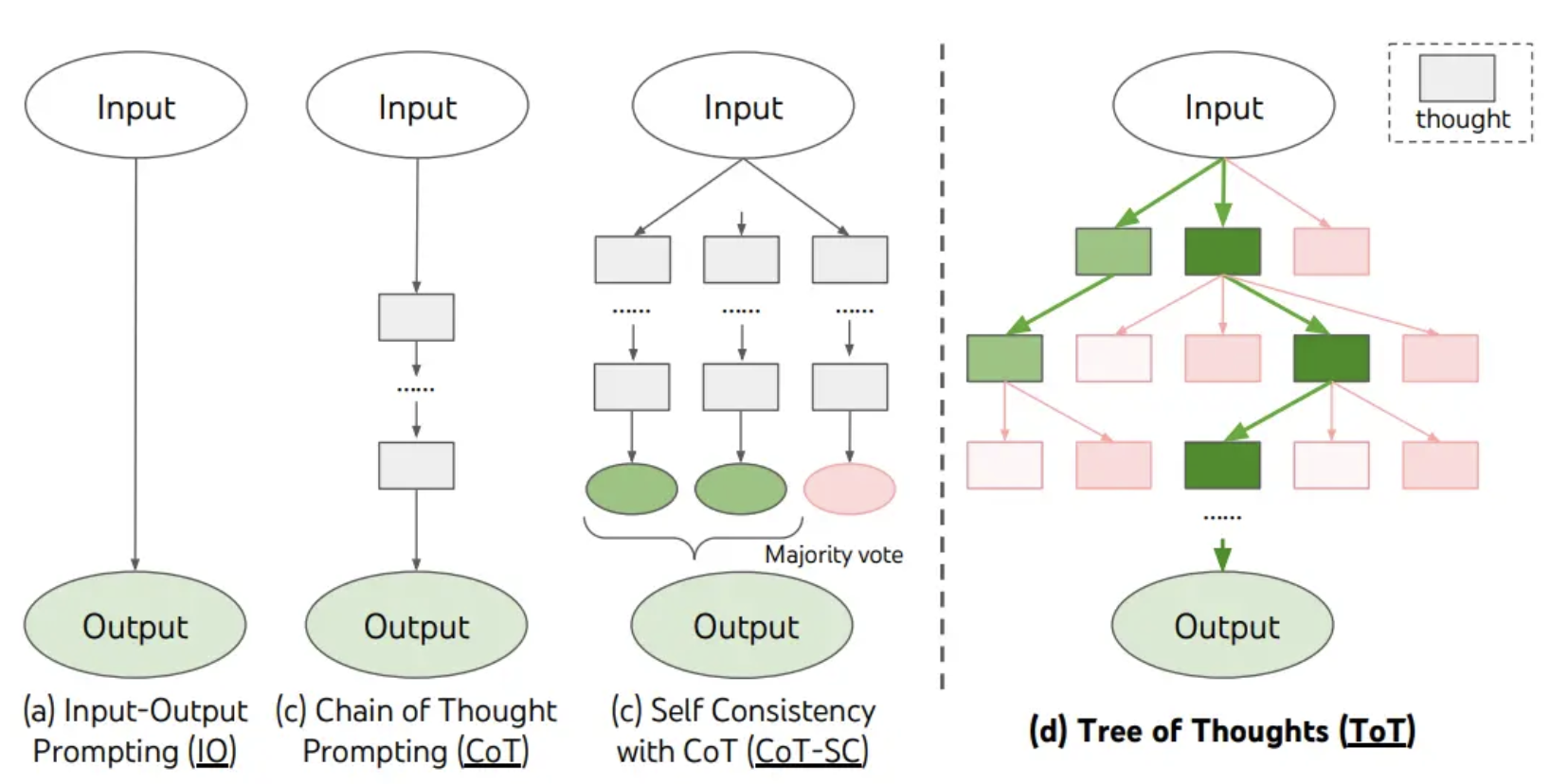
Image Source: Yao et el. (2023)
P2-1) When is ToT useful?
Useful in complex problem-solving scenarios
( = where a single line of reasoning might not suffice )
P3) Self-Consistency
Ensemble-based method
- LLM is prompted to generate multiple responses to the same query.
$\rightarrow$ Consistency among these responses serves as an indicator of their accuracy and reliability!
P3-1) When is Self-Consistency useful?
Fact-checking! Where factual accuracy and precision are crucial!
P3-2) How to measure Self-Consistency?
Various methods.
- e.g., Overlap in the content of the responses.
- e.g., Comparing the semantic similarity of responses
- e.g., BERT-scores or n-gram overlaps
$\rightarrow$ These measures help in quantifying the level of agreement among the generated responses!
P4) Reflection
Prompting LLMs to assess and potentially revise their own outputs,
- Based on reasoning about the correctness and coherence of their responses!
Assumption: Self-evaluation.
How?
- Step 1) Generate an initial response
- Step 2) Model is prompted to reflect on its own output
- Considering factors like factual accuracy, logical consistency, and relevance…
$\rightarrow$ This introspective process can lead to the generation of revised or improved responses!
P4-1) Key aspect of Reflection
LLM’s capacity for self-editing
-
The model can identify potential errors or areas of improvement.
-
Iterative process of generation & reflection & revision
$\rightarrow$ Enables the LLM to refine its output
$\rightarrow$ Enhancing the overall quality and reliability of its responses
P5) Expert Prompting
Prompting the LLMs to assume the role of an expert and respond accordingly!
Multi-expert approach
= The LLM is prompted to consider responses from multiple expert perspectives
$\rightarrow$ Synthesized to form a comprehensive and well-rounded answer!
P6) Chains
Method of linking multiple components in a sequence to handle complex tasks with LLMs
Creating a series of interconnected steps or processes, each contributing to the final outcome.
= Constructing a workflow where different stages or components are sequentially arranged.
P7) Rails
Method of guiding and controlling the output of LLMs through predefined rules or templates
$\rightarrow$ To ensure that the model’s responses adhere to certain standards or criteria
P7-1) Designs of Rails
Can be designed for various purposes (depending on the specific needs)
- (1) Topical Rails:
- Ensure that the LLM sticks to a particular topic or domain.
- (2) Fact-Checking Rails:
- Aimed at minimizing the generation of false or misleading information.
- (3) Jailbreaking Rails:
- Prevent the LLM from generating responses that attempt to bypass its own operational constraints or guidelines.
P8) Automatic Prompt Engineering (APE)
Focuses on automating the process of prompt creation
Streamline and optimize the prompt design process
Leveraging the capabilities of LLM to generate and evaluate prompts by itself!
( = Self-referential manner )
( = LLM itself generates, scores, and refines the prompts )
P2)
The methodology of APE can be broken down into several key steps: • Prompt Generation: The LLM generates a range of potential prompts based on a given task or objective. • Prompt Scoring: Each generated prompt is then evaluated for its effectiveness, often using criteria like clarity, specificity, and likelihood of eliciting the desired response. • Refinement and Iteration: Based on these evaluations, prompts can be refined and iterated upon, further enhancing their quality and effectiveness.
(3) Augmenting LLMs through external knowledge - RAG
One of the main limitations of pre-trained LLMs is their lack of up-to-date knowledge or access to private or usecase-specific information. This is where retrieval augmented generation (RAG) comes into the picture [164]. RAG, illustrated in figure 37, involves extracting a query from the input prompt and using that query to retrieve relevant information from an external knowledge source (e.g. a search engine or a knowledge graph, see figure 38 ). The relevant information is then added to the original prompt and fed to the LLM in order for the model to generate the final response. A RAG system includes three important components: Retrieval, Generation, Augmentation [165].